


-
SpecieshumanProduct IDFXC00025Cloning SiteSgfI-PmeIGeneKIAA0131SymbolARHGAP4
Alias : C1, RGC1, RhoGAP4, SrGAP4, p115DescriptionRho GTPase activating protein 4, transcript variant 2Original Clone IDcp01191 Length: 2838 bp
Length: 2838 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 946 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
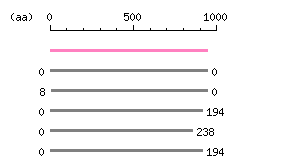
Entry Exp ID% symbol CCDS14736.1 2.2e-216 100.0 ARHGAP4 CCDS55540.1 3e-165 95.9 ARHGAP4 CCDS2572.1 2.4e-90 47.3 SRGAP3 CCDS8967.1 1.9e-88 47.1 SRGAP1 CCDS33689.1 3.9e-33 46.1 SRGAP3
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]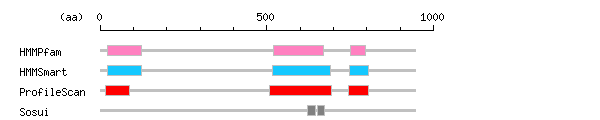 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition HMMPfam IPR001060 23 124 PF00611 Fps/Fes/Fer/CIP4 homology IPR000198 521 669 PF00620 Rho GTPase-activating protein domain IPR001452 752 797 PF00018 Src homology-3 domain HMMSmart IPR001060 22 124 SM00055 Fps/Fes/Fer/CIP4 homology IPR000198 518 692 SM00324 Rho GTPase-activating protein domain IPR001452 749 804 SM00326 Src homology-3 domain ProfileScan IPR001060 15 88 PS50133 Fps/Fes/Fer/CIP4 homology IPR000198 507 695 PS50238 Rho GTPase-activating protein domain IPR001452 746 805 PS50002 Src homology-3 domain
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 623 RLPAPVLVVLRYLFTFLNHLAQY 645 PRIMARY 23 2 653 PYNLAVCFGPTLLPVPAGQD 672 SECONDARY 20
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_001657 946 300023 100.0 100.0 NP_001158213 986 300023 95.9 99.2 NP_055665 1099 606525 47.3 96.9 NP_065813 1085 188470,606523 47.1 90.3 XP_016863068 876 606525 50.2 85.0 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KA0131 Download>KIAA0131 2838 bp ATGGCCGCTCACGGGAAGCTGCGGCGGGAGCGGGGGCTGCAGGCTGAGTATGAGACGCAA GTCAAAGAGATGCGCTGGCAGCTGAGCGAGCAGCTGCGCTGCCTGGAGCTGCAGGGCGAG CTGCGGCGGGAGTTGCTGCAGGAGCTGGCAGAGTTCATGCGGCGCCGCGCTGAGGTGGAG CTGGAATACTCCCGGGGCCTGGAAAAGCTGGCCGAGCGCTTCTCCAGCCGTGGAGGCCGC CTGGGGAGCAGCCGGGAGCACCAAAGCTTCCGGAAGGAGCCGTCCCTCCTGTCGCCCTTG CACTGCTGGGCGGTGCTGCTGCAGCACACGCGGCAGCAGAGCCGGGAGAGCGCGGCCCTG AGTGAGGTGCTGGCCGGGCCCCTGGCCCAGCGCCTGAGTCACATTGCAGAGGACGTGGGG CGCCTGGTCAAGAAGAGCAGGGATCTGGAGCAGCAGCTGCAGGATGAGCTCCTGGAGGTG GTCTCAGAGCTCCAGACGGCCAAGAAGACGTACCAGGCATATCACATGGAGAGCGTGAAT GCCGAGGCCAAGCTCCGGGAGGCCGAGCGGCAGGAGGAGAAGCGGGCAGGCCGGAGTGTC CCCACCACCACCGCTGGTGCCACTGAGGCAGGGCCCCTCCGCAAGAGCTCCCTCAAGAAG GGAGGGAGGCTGGTGGAGAAGCGGCAGGCCAAGTTCATGGAGCACAAACTCAAGTGCACA AAGGCGCGCAACGAGTACCTGCTTAGCCTGGCTAGTGTCAACGCTGCTGTCAGTAACTAC TACCTGCATGACGTCTTGGACCTCATGGACTGCTGTGACACAGGGTTCCACCTGGCCCTG GGGCAGGTGCTCCGGAGCTACACGGCCGCTGAGAGCCGCACCCAAGCCTCCCAAGTGCAG GGCCTGGGCAGCCTGGAAGAAGCTGTGGAGGCCCTGGATCCTCCAGGGGACAAAGCCAAG GTTCTCGAGGTGCATGCTACCGTCTTCTGTCCCCCGCTGCGCTTTGACTACCACCCCCAT GATGGGGATGAGGTGGCTGAGATCTGCGTTGAAATGGAGCTGCGGGACGAGATTCTGCCC AGAGCCCAGAACATCCAGAGCCGCCTGGACCGACAGACCATTGAGACAGAGGAGGTGAAC AAGACTCTGAAGGCGACACTGCAGGCCCTGCTGGAGGTGGTGGCCTCGGATGACGGGGAT GTGCTTGATTCCTTCCAGACCAGCCCCTCCACCGAGTCCCTCAAGTCCACCAGCTCAGAC CCAGGCAGCCGGCAGGCGGGCCGGAGGCGCGGCCAGCAGCAGGAGACCGAAACCTTCTAC CTCACGAAGCTCCAGGAGTATCTGAGTGGACGGAGCATCCTCGCCAAGCTGCAGGCCAAG CACGAGAAGCTGCAGGAGGCCCTTCAGCGAGGTGACAAGGAGGAGCAGGAGGTGTCTTGG ACCCAGTACACACAGAGAAAATTCCAGAAGAGCCGCCAGCCCCGCCCCAGCTCCCAGTAT AACCAGAGACTCTTTGGGGGAGACATGGAGAAGTTTATCCAGAGCTCAGGCCAGCCTGTG CCCCTGGTGGTGGAGAGCTGCATTCGCTTCATCAACCTCAATGGCCTGCAGCATGAAGGC ATCTTCCGGGTATCGGGTGCCCAGCTCCGGGTCTCAGAGATCCGTGATGCCTTCGAGAGA GGGGAGGACCCACTGGTGGAGGGCTGCACTGCCCACGACCTGGACTCGGTGGCCGGGGTG CTGAAGCTCTACTTCCGGAGCCTGGAGCCCCCACTCTTCCCCCCAGACCTGTTCGGCGAG CTGCTGGCTTCTTCGGAGCTGGAGGCCACAGCGGAGAGGGTGGAGCACGTGAGCCGCCTG CTGTGGCGGCTGCCCGCGCCGGTGCTGGTGGTTCTGCGCTACCTCTTCACCTTCCTCAAC CACCTGGCCCAGTACAGCGATGAGAACATGATGGACCCCTACAACCTGGCCGTGTGCTTC GGGCCCACGCTGCTACCGGTGCCCGCTGGGCAGGACCCGGTGGCGCTGCAGGGCCGGGTG AACCAGCTGGTGCAGACGCTCATAGTGCAGCCCGATCGGGTCTTCCCGCCCCTGACCTCG CTGCCTGGCCCCGTCTACGAGAAGTGCATGGCACCGCCTTCCGCCAGCTGCCTGGGGGAC GCCCAGCTGGAGAGCCTGGGGGCGGACAATGAGCCGGAGCTGGAAGCCGAGATGCCCGCA CAGGAGGATGACCTGGAGGGGGTCGTGGAGGCTGTGGCCTGCTTTGCCTACACGGGCCGC ACAGCCCAGGAGCTGAGCTTCCGGCGGGGGGACGTACTGCGGCTGCACGAGAGGGCCTCG AGCGACTGGTGGCGGGGGGAGCACAACGGCATGCGGGGCCTCATCCCCCACAAGTATATC ACGCTGCCCGCCGGGACGGAGAAGCAGGTGGTGGGCGCAGGGCTGCAGACTGCAGGGGAG TCTGGGAGCAGTCCCGAGGGCCTCCTGGCATCGGAGCTGGTCCACCGGCCAGAGCCATGC ACCTCACCTGAGGCCATGGGACCCTCTGGACACAGACGACGCTGCTTGGTCCCAGCCTCC CCAGAGCAACACGTGGAGGTGGATAAGGCTGTGGCACAGAACATGGACTCTGTGTTTAAG GAGCTCTTGGGAAAGACCTCTGTCCGCCAGGGCCTTGGGCCAGCATCTACCACCTCTCCC AGTCCTGGGCCCCGAAGCCCAAAGGCCCCGCCCAGCAGCCGCCTGGGCAGGAACAAAGGC TTCTCCCGGGGCCCTGGGGCCCCAGCCTCACCCTCAGCTTCCCACCCCCAGGGCCTAGAC ACGACCCCCAAGCCACAC
Cloned ORF protein sequence for pF1KA0131 Download>KIAA0131 946 aa MAAHGKLRRERGLQAEYETQVKEMRWQLSEQLRCLELQGELRRELLQELAEFMRRRAEVE LEYSRGLEKLAERFSSRGGRLGSSREHQSFRKEPSLLSPLHCWAVLLQHTRQQSRESAAL SEVLAGPLAQRLSHIAEDVGRLVKKSRDLEQQLQDELLEVVSELQTAKKTYQAYHMESVN AEAKLREAERQEEKRAGRSVPTTTAGATEAGPLRKSSLKKGGRLVEKRQAKFMEHKLKCT KARNEYLLSLASVNAAVSNYYLHDVLDLMDCCDTGFHLALGQVLRSYTAAESRTQASQVQ GLGSLEEAVEALDPPGDKAKVLEVHATVFCPPLRFDYHPHDGDEVAEICVEMELRDEILP RAQNIQSRLDRQTIETEEVNKTLKATLQALLEVVASDDGDVLDSFQTSPSTESLKSTSSD PGSRQAGRRRGQQQETETFYLTKLQEYLSGRSILAKLQAKHEKLQEALQRGDKEEQEVSW TQYTQRKFQKSRQPRPSSQYNQRLFGGDMEKFIQSSGQPVPLVVESCIRFINLNGLQHEG IFRVSGAQLRVSEIRDAFERGEDPLVEGCTAHDLDSVAGVLKLYFRSLEPPLFPPDLFGE LLASSELEATAERVEHVSRLLWRLPAPVLVVLRYLFTFLNHLAQYSDENMMDPYNLAVCF GPTLLPVPAGQDPVALQGRVNQLVQTLIVQPDRVFPPLTSLPGPVYEKCMAPPSASCLGD AQLESLGADNEPELEAEMPAQEDDLEGVVEAVACFAYTGRTAQELSFRRGDVLRLHERAS SDWWRGEHNGMRGLIPHKYITLPAGTEKQVVGAGLQTAGESGSSPEGLLASELVHRPEPC TSPEAMGPSGHRRRCLVPASPEQHVEVDKAVAQNMDSVFKELLGKTSVRQGLGPASTTSP SPGPRSPKAPPSSRLGRNKGFSRGPGAPASPSASHPQGLDTTPKPH
Nucleotide Sequence (with vector) for pF1KA0131 Download>pF1KA0131 5951 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGCCGCTCAC GGGAAGCTGCGGCGGGAGCGGGGGCTGCAGGCTGAGTATGAGACGCAAGTCAAAGAGATG CGCTGGCAGCTGAGCGAGCAGCTGCGCTGCCTGGAGCTGCAGGGCGAGCTGCGGCGGGAG TTGCTGCAGGAGCTGGCAGAGTTCATGCGGCGCCGCGCTGAGGTGGAGCTGGAATACTCC CGGGGCCTGGAAAAGCTGGCCGAGCGCTTCTCCAGCCGTGGAGGCCGCCTGGGGAGCAGC CGGGAGCACCAAAGCTTCCGGAAGGAGCCGTCCCTCCTGTCGCCCTTGCACTGCTGGGCG GTGCTGCTGCAGCACACGCGGCAGCAGAGCCGGGAGAGCGCGGCCCTGAGTGAGGTGCTG GCCGGGCCCCTGGCCCAGCGCCTGAGTCACATTGCAGAGGACGTGGGGCGCCTGGTCAAG AAGAGCAGGGATCTGGAGCAGCAGCTGCAGGATGAGCTCCTGGAGGTGGTCTCAGAGCTC CAGACGGCCAAGAAGACGTACCAGGCATATCACATGGAGAGCGTGAATGCCGAGGCCAAG CTCCGGGAGGCCGAGCGGCAGGAGGAGAAGCGGGCAGGCCGGAGTGTCCCCACCACCACC GCTGGTGCCACTGAGGCAGGGCCCCTCCGCAAGAGCTCCCTCAAGAAGGGAGGGAGGCTG GTGGAGAAGCGGCAGGCCAAGTTCATGGAGCACAAACTCAAGTGCACAAAGGCGCGCAAC GAGTACCTGCTTAGCCTGGCTAGTGTCAACGCTGCTGTCAGTAACTACTACCTGCATGAC GTCTTGGACCTCATGGACTGCTGTGACACAGGGTTCCACCTGGCCCTGGGGCAGGTGCTC CGGAGCTACACGGCCGCTGAGAGCCGCACCCAAGCCTCCCAAGTGCAGGGCCTGGGCAGC CTGGAAGAAGCTGTGGAGGCCCTGGATCCTCCAGGGGACAAAGCCAAGGTTCTCGAGGTG CATGCTACCGTCTTCTGTCCCCCGCTGCGCTTTGACTACCACCCCCATGATGGGGATGAG GTGGCTGAGATCTGCGTTGAAATGGAGCTGCGGGACGAGATTCTGCCCAGAGCCCAGAAC ATCCAGAGCCGCCTGGACCGACAGACCATTGAGACAGAGGAGGTGAACAAGACTCTGAAG GCGACACTGCAGGCCCTGCTGGAGGTGGTGGCCTCGGATGACGGGGATGTGCTTGATTCC TTCCAGACCAGCCCCTCCACCGAGTCCCTCAAGTCCACCAGCTCAGACCCAGGCAGCCGG CAGGCGGGCCGGAGGCGCGGCCAGCAGCAGGAGACCGAAACCTTCTACCTCACGAAGCTC CAGGAGTATCTGAGTGGACGGAGCATCCTCGCCAAGCTGCAGGCCAAGCACGAGAAGCTG CAGGAGGCCCTTCAGCGAGGTGACAAGGAGGAGCAGGAGGTGTCTTGGACCCAGTACACA CAGAGAAAATTCCAGAAGAGCCGCCAGCCCCGCCCCAGCTCCCAGTATAACCAGAGACTC TTTGGGGGAGACATGGAGAAGTTTATCCAGAGCTCAGGCCAGCCTGTGCCCCTGGTGGTG GAGAGCTGCATTCGCTTCATCAACCTCAATGGCCTGCAGCATGAAGGCATCTTCCGGGTA TCGGGTGCCCAGCTCCGGGTCTCAGAGATCCGTGATGCCTTCGAGAGAGGGGAGGACCCA CTGGTGGAGGGCTGCACTGCCCACGACCTGGACTCGGTGGCCGGGGTGCTGAAGCTCTAC TTCCGGAGCCTGGAGCCCCCACTCTTCCCCCCAGACCTGTTCGGCGAGCTGCTGGCTTCT TCGGAGCTGGAGGCCACAGCGGAGAGGGTGGAGCACGTGAGCCGCCTGCTGTGGCGGCTG CCCGCGCCGGTGCTGGTGGTTCTGCGCTACCTCTTCACCTTCCTCAACCACCTGGCCCAG TACAGCGATGAGAACATGATGGACCCCTACAACCTGGCCGTGTGCTTCGGGCCCACGCTG CTACCGGTGCCCGCTGGGCAGGACCCGGTGGCGCTGCAGGGCCGGGTGAACCAGCTGGTG CAGACGCTCATAGTGCAGCCCGATCGGGTCTTCCCGCCCCTGACCTCGCTGCCTGGCCCC GTCTACGAGAAGTGCATGGCACCGCCTTCCGCCAGCTGCCTGGGGGACGCCCAGCTGGAG AGCCTGGGGGCGGACAATGAGCCGGAGCTGGAAGCCGAGATGCCCGCACAGGAGGATGAC CTGGAGGGGGTCGTGGAGGCTGTGGCCTGCTTTGCCTACACGGGCCGCACAGCCCAGGAG CTGAGCTTCCGGCGGGGGGACGTACTGCGGCTGCACGAGAGGGCCTCGAGCGACTGGTGG CGGGGGGAGCACAACGGCATGCGGGGCCTCATCCCCCACAAGTATATCACGCTGCCCGCC GGGACGGAGAAGCAGGTGGTGGGCGCAGGGCTGCAGACTGCAGGGGAGTCTGGGAGCAGT CCCGAGGGCCTCCTGGCATCGGAGCTGGTCCACCGGCCAGAGCCATGCACCTCACCTGAG GCCATGGGACCCTCTGGACACAGACGACGCTGCTTGGTCCCAGCCTCCCCAGAGCAACAC GTGGAGGTGGATAAGGCTGTGGCACAGAACATGGACTCTGTGTTTAAGGAGCTCTTGGGA AAGACCTCTGTCCGCCAGGGCCTTGGGCCAGCATCTACCACCTCTCCCAGTCCTGGGCCC CGAAGCCCAAAGGCCCCGCCCAGCAGCCGCCTGGGCAGGAACAAAGGCTTCTCCCGGGGC CCTGGGGCCCCAGCCTCACCCTCAGCTTCCCACCCCCAGGGCCTAGACACGACCCCCAAG CCACACGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGG CATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCAC CGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTT GCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTA TCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGT CCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTT CTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCT TCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAAC TGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAG ACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCC GCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGAT GCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTG TCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACG GGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTA TTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTA TCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTC GACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTC GATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGG CTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTG CCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGT GTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGC GGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGC ATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGA CCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCAC AGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAA CCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCA CAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGC GTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATA CCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTA TCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCA GCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGA CTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGG TGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGG TATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGG CAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAG AAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAA CGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGAT CCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAA ACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGG TTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTG GTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGC GTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAA ACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGAT ACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAG CGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGG TAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGG CTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGA GTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGC GGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGG ATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATG TATCCGCTCAT
 more Linker info
more Linker info
{kind=link}