Nucleotide Sequence (with vector) for pF1KA0226
Download
>pF1KA0226 5894 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGCAGAGCATC
CTCTATCACGGGCTTATCCGTGACCAGGCGTGCCGCCGCCAGACGGATTACTGGCAGTTC
GTGAAAGACATCCGGTGGCTCAGTCCCCACTCAGCCCTTCACGTGGAGAAGTTCATCAGC
GTGCACGAGAACGACCAGAGCAGTGCTGATGGTGCCAGTGAACGTGCTGTTGCCGAGCTG
TGGCTGCAGCACAGCCTGCAGTACCACTGCCTCTCAGCCCAGCTCCGGCCCCTGCTCGGG
GATAGACAGTATATCAGAAAATTCTACACAGATGCTGCCTTCCTGCTAAGTGACGCTCAT
GTCACGGCCATGCTGCAGTGCCTGGAAGCAGTGGAACAGAACAACCCCCGCCTCCTGGCT
CAGATCGATGCGTCCATGTTTGCCAGAAAGCACGAGAGCCCGCTCCTGGTGACAAAGAGC
CAGAGCCTGACAGCCCTGCCCAGTTCCACATACACCCCTCCAAACAGCTATGCTCAGCAT
TCCTACTTTGGGTCCTTCTCTAGCCTCCACCAATCCGTGCCCAACAATGGCTCAGAGAGA
AGATCTACTTCCTTTCCACTCTCTGGCCCTCCCCGGAAACCTCAAGAAAGCAGAGGGCAC
GTCTCACCAGCAGAGGATCAAACCATCCAAGCCCCCCCAGTTTCAGTCTCTGCACTAGCC
AGGGATTCCCCTTTGACCCCAAATGAAATGAGCTCCAGTACTCTGACCAGCCCCATAGAG
GCATCCTGGGTCAGCAGCCAGAATGATTCCCCAGGTGATGCCAGTGAGGGGCCTGAGTAC
CTGGCCATTGGCAACTTGGACCCCCGAGGCCGGACTGCCAGCTGTCAGAGTCACAGCAGC
AATGCCGAGAGCAGCAGTTCCAATTTGTTCTCCTCCAGCAGCTCCCAGAAGCCAGATTCT
GCTGCCTCTTCCTTAGGGGACCAGGAAGGAGGTGGGGAGAGCCAGCTGTCCAGTGTCCTC
CGCAGGTCCAGCTTCTCAGAGGGGCAGACACTCACTGTCACCAGTGGGGCAAAGAAAAGC
CACATTCGCTCCCATTCGGATACCAGCATTGCCTCCAGGGGAGCTCCAGGAGGCCCCAGG
AATATCACCATTATAGTTGAAGATCCCATTGCAGAATCCTGCAATGATAAGGCGAAGTTG
AGAGGCCCTTTGCCCTACTCTGGTCAAAGCAGTGAAGTCAGCACACCCAGCTCTCTGTAC
ATGGAATATGAAGGTGGTCGGTACCTGTGCTCAGGGGAAGGCATGTTCCGAAGACCATCA
GAAGGACAGTCCCTCATCAGCTACCTCTCTGAGCAAGACTTCGGCAGCTGTGCCGACCTG
GAAAAGGAGAATGCCCACTTCAGCATCTCAGAGTCCTTAATTGCTGCCATCGAGCTAATG
AAGTGCAACATGATGAGCCAGTGCCTAGAGGAGGAGGAAGTGGAAGAGGAAGACAGTGAT
AGAGAGATCCAGGAGCTGAAGCAGAAGATCCGCCTTCGGCGCCAGCAAATCCGCACCAAG
AACCTGCTCCCCATGTACCAGGAGGCTGAGCACGGAAGCTTTCGGGTCACCTCCAGCAGC
TCCCAGTTCAGCTCACGTGATTCGGCACAGCTCTCTGACTCTGGCTCTGCTGATGAGGTT
GATGAATTTGAAATCCAAGATGCTGACATCAGAAGGAACACAGCCTCAAGCAGCAAATCC
TTCGTTTCCTCCCAGTCCTTCTCCCACTGCTTCCTGCACTCCACGTCTGCTGAGGCGGTG
GCCATGGGGCTCCTGAAGCAGTTTGAGGGGATGCAGCTTCCAGCCGCCTCGGAGCTGGAG
TGGCTTGTCCCGGAGCATGATGCCCCTCAGAAGCTCCTGCCCATTCCTGACTCACTGCCC
ATCTCACCGGATGACGGGCAGCACGCTGACATCTACAAGCTGCGGATTCGTGTTCGTGGC
AACTTGGAGTGGGCCCCGCCCCGGCCTCAGATAATTTTTAATGTTCATCCAGCCCCAACG
AGGAAAATTGCCGTGGCCAAGCAGAATTACCGCTGTGCAGGATGTGGCATCCGGACTGAC
CCTGATTACATCAAGCGACTGCGGTACTGTGAGTACCTGGGCAAGTACTTCTGCCAGTGC
TGCCACGAGAATGCCCAGATGGCCATCCCCAGCCGGGTTCTGCGCAAGTGGGACTTCAGC
AAGTACTACGTCAGCAACTTCTCCAAGGACCTGCTCATTAAGATCTGGAATGATCCTCTC
TTCAACGTGCAGGACATAAACAGTGCCCTCTATAGGAAGGTCAAGCTGCTCAATCAAGTC
CGGCTGCTGCGGGTCCAGCTGTGTCACATGAAGAACATGTTCAAGACTTGCCGACTGGCC
AAGGAGCTTCTGGATTCCTTTGACACAGTCCCAGGCCACCTGACAGAGGACCTCCACCTG
TACTCACTGAATGACCTGACTGCGACCAGGAAGGGGGAGCTGGGGCCCCGGCTTGCTGAG
CTCACCAGGGCAGGGGCTACCCATGTGGAGAGATGCATGCTCTGCCAAGCCAAAGGCTTC
ATCTGTGAGTTCTGTCAGAATGAGGATGACATCATCTTTCCCTTTGAGCTCCATAAGTGC
CGGACCTGTGAAGAGTGTAAAGCGTGTTACCATAAAGCCTGCTTCAAGTCTGGAAGCTGT
CCGCGCTGCGAGCGGCTGCAGGCCCGGCGGGAGGCACTGGCCAGGCAGAGCCTGGAGTCT
TACCTGTCAGACTACGAGGAGGAGCCCGCGGAAGCGCTGGCCCTGGAAGCCGCCGTCCTG
GAGGCCACCGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGC
AGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGC
CACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTT
TTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAG
CTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCT
TGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGC
TTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGA
GCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTA
AACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAA
GAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCG
GCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCT
GATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGAC
CTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACG
ACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTG
CTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAA
GTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCA
TTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTT
GTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCC
AGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGC
TTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTG
GGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTT
GGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAG
CGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAA
TGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATC
CACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAG
GAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCA
TCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCA
GGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGG
ATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAG
GTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGT
TCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACA
CGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGG
CGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATT
TGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATC
CGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCG
CAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTG
GAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTA
GATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGT
GAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTC
TGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGG
GTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGG
TGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGA
TAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCT
GATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAG
TAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGA
TGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAA
AGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCC
TGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGT
GGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGA
CGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAAT
ATGTATCCGCTCAT



 Length: 2781 bp
Length: 2781 bp Restriction map B
Restriction map B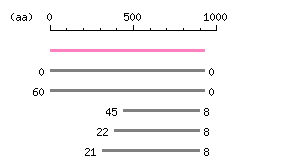

 more Linker info
more Linker info
{kind=link}