Nucleotide Sequence (with vector) for pF1KA0418
Download
>pF1KA0418 5933 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGATCCTGGAA
CAGTACGTGGTGGTGTCCAACTATAAGAAGCAGGAGAACTCGGAGCTGAGCCTCCAGGCC
GGGGAGGTGGTGGATGTCATCGAGAAGAACGAGAGCGGCTGGTGGTTCGTGAGCACTTCT
GAGGAGCAGGGCTGGGTCCCTGCCACCTACCTGGAGGCCCAGAATGGTACTCGGGATGAC
TCCGACATCAACACCTCTAAGACTGGAGAAGAGGAGAAGTATGTCACCGTGCAGCCTTAC
ACCAGCCAAAGCAAGGACGAGATTGGCTTTGAGAAGGGCGTCACAGTGGAGGTGATCCGG
AAGAATCTGGAAGGCTGGTGGTATATCAGATACCTGGGCAAAGAGGGCTGGGCGCCAGCA
TCCTACCTGAAGAAGGCCAAGGATGACCTGCCAACCCGGAAGAAGAACCTGGCCGGCCCA
GTGGAGATCATTGGGAACATCATGGAGATCAGCAACCTGCTGAACAAGAAGGCGTCTGGG
GACAAGGAAACTCCACCAGCCGAAGGCGAGGGCCATGAGGCCCCCATTGCCAAGAAGGAG
ATCAGCCTGCCCATCCTCTGCAATGCCTCCAATGGCAGTGCCGTGGGCGTTCCTGACAGG
ACTGTCTCCAGGCTGGCCCAGGGCTCTCCAGCTGTGGCCAGGATTGCCCCTCAGCGGGCC
CAGATCAGCTCCCCGAACCTACGGACAAGACCTCCACCACGCAGAGAATCCAGCCTGGGG
TTCCAACTGCCAAAGCCACCAGAGCCCCCTTCTGTTGAGGTGGAGTACTACACCATTGCC
GAATTCCAGTCGTGCATTTCCGATGGCATCAGCTTTCGGGGTGGACAGAAGGCAGAGGTC
ATTGATAAGAACTCAGGTGGCTGGTGGTACGTGCAGATCGGTGAGAAGGAGGGCTGGGCC
CCCGCATCATACATCGATAAGCGCAAGAAGCCCAACCTGAGCCGCCGCACAAGCACGCTG
ACCCGGCCCAAGGTGCCCCCGCCAGCACCCCCCAGCAAGCCCAAGGAGGCCGAGGAGGGC
CCTACGGGGGCCAGTGAGAGCCAGGACTCCCCGCGGAAGCTCAAGTATGAGGAGCCTGAG
TATGACATCCCTGCATTCGGCTTTGACTCAGAGCCTGAGCTGAGCGAGGAGCCCGTGGAG
GACAGAGCCTCAGGGGAGAGGCGGCCTGCCCAGCCCCACCGGCCCTCGCCGGCCTCTTCT
CTGCAGCGGGCCCGCTTCAAGGTGGGTGAGTCTTCAGAGGATGTGGCCCTGGAAGAGGAG
ACCATCTATGAGAATGAGGGCTTCCGGCCATATGCAGAGGACACCCTGTCAGCCAGAGGC
TCCTCCGGGGACAGCGACTCCCCAGGCAGCTCCTCGCTGTCCCTGACCAGGAAAAACTCC
CCCAAATCAGGCTCCCCCAAGTCATCATCACTCCTAAAGCTCAAGGCAGAGAAGAATGCC
CAGGCAGAAATGGGGAAGAACCACTCCTCAGCCTCCTTTTCCTCATCCATCACCATCAAC
ACCACTTGCTGCTCCTCCTCTTCCTCCTCCTCCTCTTCCTTGTCCAAAACCAGTGGCGAC
CTGAAGCCCCGCTCTGCTTCGGACGCAGGCATCCGCGGCACTCCCAAGGTCAGGGCAAAG
AAGGATGCTGATGCGAACGCTGGGCTGACCTCCTGTCCCCGGGCCAAGCCATCGGTCCGG
CCCAAGCCATTCCTAAACCGAGCAGAGTCGCAGAGCCAAGAGAAGATGGACATCAGCACT
TTACGGCGCCAGCTGAGACCCACAGGCCAGCTCCGTGGAGGGCTCAAGGGCTCCAAGAGT
GAGGATTCGGAGCTGCCCCCGCAGACGGCCTCCGAGGCTCCCAGTGAGGGGTCTAGGAGA
AGCTCATCCGACCTCATCACCCTCCCAGCCACCACTCCCCCATGTCCCACCAAGAAGGAA
TGGGAAGGGCCAGCCACCTCGTACATGACATGCAGCGCCTACCAGAAGGTCCAGGACTCG
GAGATCAGCTTCCCCGCGGGCGTGGAGGTGCAGGTGCTGGAGAAGCAGGAGAGCGGGTGG
TGGTATGTGAGGTTTGGGGAGCTGGAGGGCTGGGCCCCTTCCCACTATTTGGTGCTGGAT
GAGAACGAGCAACCTGACCCCTCTGGCAAAGAGCTGGACACAGTGCCCGCCAAGGGCAGG
CAGAACGAAGGCAAGTCAGACAGCCTGGAGAAGATCGAGAGGCGCGTCCAAGCACTGAAC
ACCGTCAACCAGAGCAAGAAGGCCACGCCCCCCATCCCCTCCAAACCTCCCGGGGGCTTT
GGCAAGACCTCAGGCACTCCAGCGGTGAAGATGAGGAACGGAGTGCGGCAGGTGGCGGTC
AGGCCCCAGTCGGTGTTTGTGTCCCCGCCACCCAAGGACAACAACCTGTCCTGCGCCCTG
CGGAGGAATGAGTCACTCACGGCCACTGATGGCCTCCGAGGCGTCCGACGGAACTCCTCC
TTTAGCACTGCTCGCTCCGCTGCCGCCGAGGCCAAGGGCCGCCTGGCCGAACGGGCTGCC
AGCCAGGGTTCAGACTCACCCCTACTGCCCGCCCAGCGCAACAGCATCCCCGTGTCCCCT
GTGCGCCCCAAGCCCATCGAGAAGTCTCAGTTCATCCACAATAACCTCAAAGATGTGTAC
GTCTCTATCGCAGACTACGAGGGGGATGAGGAGACAGCAGGCTTCCAGGAGGGGGTGTCC
ATGGAGGTTCTGGAGAGGAACCCTAATGGCTGGTGGTACTGCCAGATCCTGGATGGTGTG
AAGCCCTTCAAAGGCTGGGTGCCTTCCAACTACCTTGAGAAAAAGAACGTTTAAACGAAT
TCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGC
TGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGC
ATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTAT
ATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACT
GCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCT
GACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCT
TTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCT
GGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCG
CCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTT
CGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTA
TTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTG
TCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAA
CTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCT
GTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGG
CAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCA
ATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACAT
CGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGAC
GAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCG
GATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAA
AATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAG
GACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGC
TTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTT
CTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCA
ACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGC
AGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTT
GCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAG
TCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTC
CCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCC
TTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGT
CGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTT
ATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGC
AGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAA
GTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAA
GCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGG
TAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGA
AGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGG
GATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAA
TACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGC
TTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATAC
GGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTAC
CTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTAT
GGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCA
CGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACG
CAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGA
CCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCA
TGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGG
CCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGG
GAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCAT
AAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTC
TACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 2820 bp
Length: 2820 bp Restriction map B
Restriction map B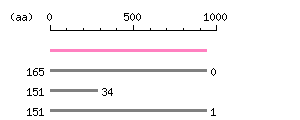

 more Linker info
more Linker info
{kind=link}