Nucleotide Sequence (with vector) for pF1KA1104
Download
>pF1KA1104 6224 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGTGGCGCTGC
GGCGGGCGGCAGGGCCTGTGTGTGCTGAGGCGGCTGAGCGGCGGACATGCACACCACAGA
GCGTGGCGATGGAACAGTAACCGGGCTTGTGAGAGGGCTCTGCAGTATAAACTAGGAGAC
AAGATCCATGGATTCACCGTAAACCAGGTGACATCTGTTCCCGAGCTGTTCCTGACTGCA
GTGAAGCTCACCCATGATGACACAGGAGCCAGGTATTTACACCTGGCCAGAGAAGACACG
AATAATCTGTTCAGCGTGCAGTTCCGTACCACTCCCATGGACAGTACTGGTGTTCCTCAC
ATTCTTGAGCATACCGTCCTTTGTGGGTCTCAGAAATATCCGTGCAGAGACCCTTTCTTC
AAAATGTTGAACCGGTCCCTCTCCACGTTCATGAACGCCTTCACAGCTAGTGATTATACT
CTGTATCCATTTTCCACACAAAATCCCAAGGACTTTCAGAATCTCCTCTCGGTGTATTTG
GATGCCACCTTTTTCCCATGTTTACGCGAGCTGGATTTCTGGCAGGAAGGATGGCGGCTG
GAACATGAGAATCCGAGCGACCCCCAGACGCCCTTGGTCTTTAAAGGAGTCGTCTTTAAT
GAGATGAAGGGAGCGTTTACAGACAATGAGAGGATATTCTCCCAGCACCTTCAGAACAGA
CTTCTTCCCGACCACACGTACTCAGTGGTCTCCGGGGGTGACCCACTGTGCATCCCGGAG
CTTACATGGGAGCAGCTTAAGCAGTTTCATGCCACTCACTATCACCCAAGCAATGCTAGG
TTCTTCACGTACGGTAATTTTCCATTAGAACAGCATCTGAAACAAATTCACGAGGAAGCA
CTGAGCAAATTCCAGAAAATTGAACCAAGCACCGTGGTGCCAGCTCAGACACCCTGGGAC
AAGCCTAGGGAATTCCAGATAACATGTGGCCCGGATTCATTTGCTACAGATCCCTCTAAA
CAAACAACCGTCAGCGTTAGCTTCCTCTTACCGGACATCACCGACACATTTGAAGCCTTC
ACATTAAGTCTTCTGTCTTCACTCTTGACTTCTGGGCCCAATTCTCCCTTTTACAAAGCC
TTGATTGAATCTGGCCTTGGCACAGACTTTTCTCCTGATGTTGGATATAATGGCTACACG
AGGGAGGCCTACTTTAGTGTCGGCCTCCAAGGGATTGTGGAGAAAGACATTGAGACCGTC
AGAAGCCTCATAGACAGAACGATTGATGAAGTAGTTGAGAAAGGATTTGAAGATGATCGA
ATTGAGGCTTTACTTCATAAAATTGAAATACAGATGAAACATCAGTCTACCAGCTTTGGG
CTGATGCTGACATCATACATAGCTTCTTGCTGGAACCATGATGGGGACCCTGTGGAGCTC
TTGAAGTTGGGAAATCAGTTAGCTAAATTCAGACAGTGCCTGCAGGAAAATCCAAAATTT
TTGCAAGAAAAAGTAAAACAGTATTTTAAGAATAACCAGCATAAGCTGACTTTATCGATG
AGGCCAGATGACAAGTATCACGAGAAGCAGGCACAGGTGGAAGCCACGAAGCTCAAGCAG
AAGGTCGAGGCTCTGTCCCCCGGAGACAGGCAGCAGATCTACGAGAAAGGTCTAGAATTA
CGGAGTCAACAAAGCAAACCTCAAGATGCCTCTTGTCTGCCAGCGTTGAAAGTTTCCGAT
ATTGAACCCACCATACCTGTCACAGAGTTGGACGTGGTCCTGACAGCTGGAGATATCCCT
GTTCAGTACTGCGCCCAGCCCACCAATGGCATGGTGTATTTCCGGGCCTTCTCCAGCCTG
AACACACTCCCCGAGGAGCTGAGGCCCTATGTGCCCCTCTTCTGCAGCGTCCTCACCAAG
CTGGGCTGCGGCCTTCTTGACTACCGGGAGCAGGCTCAGCAGATAGAATTGAAGACCGGA
GGGATGAGTGCTTCTCCCCACGTGCTCCCCGACGACTCACACATGGACACCTACGAGCAG
GGTGTGCTTTTCTCCTCTCTCTGCCTGGATCGAAACCTGCCAGACATGATGCAGCTATGG
AGTGAAATATTTAACAACCCGTGCTTTGAAGAAGAGGAGCACTTCAAGGTGCTGGTGAAG
ATGACCGCCCAGGAGCTCGCCAATGGAATTCCTGACTCTGGGCACCTGTACGCATCCATC
AGGGCAGGCCGGACCCTCACGCCCGCAGGGGACCTGCAGGAGACCTTCAGCGGGATGGAT
CAGGTGCGGCTGATGAAGAGGATTGCAGAAATGACAGATATCAAACCCATCCTGAGGAAG
CTCCCACGTATCAAGAAACACTTGTTAAATGGTGATAATATGAGGTGTTCAGTGAATGCG
ACTCCTCAGCAGATGCCTCAGACAGAAAAAGCGGTCGAAGACTTCCTTAGAAGCATCGGT
CGGAGTAAAAAGGAACGGAGGCCTGTGCGCCCACACACGGTCGAGAAACCTGTGCCCAGC
AGCTCTGGTGGAGATGCCCACGTTCCCCATGGCTCCCAGGTCATTAGGAAGCTGGTCATG
GAACCCACCTTCAAGCCCTGGCAGATGAAGACTCACTTCCTGATGCCCTTCCCGGTGAAT
TACGTGGGTGAATGCATCCGAACTGTCCCCTACACGGACCCAGATCATGCCAGTCTTAAA
ATCCTTGCACGTTTGATGACTGCCAAATTCTTGCATACAGAAATTCGAGAAAAAGGCGGT
GCTTATGGTGGAGGCGCAAAACTCAGCCACAATGGGATTTTCACCCTTTACTCTTACAGG
GACCCAAATACAATAGAGACGCTCCAGTCTTTTGGGAAGGCTGTCGACTGGGCTAAGTCT
GGAAAATTCACACAGCAAGACATCGACGAAGCCAAACTTTCTGTCTTCTCAACCGTAGAT
GCTCCTGTCGCTCCTTCAGACAAAGGAATGGACCACTTCTTGTACGGCCTCTCGGATGAG
ATGAAGCAGGCCCACAGAGAGCAGCTCTTTGCTGTCAGCCACGACAAGCTCCTGGCCGTG
AGCGATAGATACCTCGGCACTGGGAAGAGCACACACGGCCTGGCCATCCTCGGACCCGAG
AACCCGAAAATTGCCAAGGACCCATCCTGGATCATCCGAGTTTAAACGAATTCGAGCTCG
GTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAA
AGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCT
TGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTC
GCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTAC
CTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCAT
CCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCC
CTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCC
TCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATC
TGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTT
GAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTAT
GACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAG
GGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGAC
GAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGAC
GTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTC
CTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGG
CTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAG
CGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCAT
CAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAG
GATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGC
TTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCG
TTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTG
CTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAG
TTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGACTA
TAAAAGGATCTAGGTGAAGATCCTTTTTGATAATCTCATGACCAAAATCCCTTAACGTGA
GTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAAATCC
TTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGT
TTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGC
GCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTC
TGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGG
CGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCG
GTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGA
ACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGC
GGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGG
GGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCG
ATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTT
TTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATGTTCTTTCCTGCGTTATCCCC
TGATTCTGTGGATAACCGTATTACCGCCTTTGAGTGAGCTGATACCGGAAATACAGGAAC
GCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGA
TTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAAT
TTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCT
GCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCC
ACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTC
CGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGG
TCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCC
GAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGT
AGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTT
TTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATT
TGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCA
GGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTC
TTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 3111 bp
Length: 3111 bp Restriction map B
Restriction map B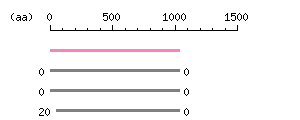

 more Linker info
more Linker info
{kind=link}