Nucleotide Sequence (with vector) for pF1KA1161
Download
>pF1KA1161 5153 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGTACACCTTC
CTGCCCGACAACTTCTCACCTGCCAAGCCCAAGCCTTCCAAAGAGCTGAAGCCGCTGCTG
GGCTCCGCGGTTCTGGGGCTGCTGCTTGTGCTGGCCGCGGTGGTGGCCTGGTGCTACTAC
AGCGTCTCCCTACGCAAGGCGGAGCGACTTCGCGCGGAGCTGCTGGACCTGAAAGCTGGC
GGCTTCTCCATCCGCAATCAGAAGGGAGAGCAGGTCTTCCGCCTGGCCTTCCGCTCCGGC
GCGCTGGACCTTGACTCCTGCAGCCGCGATGGCGCCCTGCTGGGCTGCTCGCTCACGGCC
GACGGGCTGCCGCTGCACTTCTTCATCCAGACTGTGCGGCCCAAGGACACGGTCATGTGC
TACCGCGTGCGCTGGGAGGAGGCAGCGCCGGGCCGGGCCGTGGAGCACGCCATGTTCTTG
GGCGACGCGGCGGCCCACTGGTATGGTGGCGCCGAGATGAGGACGCAACACTGGCCCATC
CGCCTGGATGGCCAGCAGGAGCCCCAGCCGTTCGTCACCAGCGATGTCTACTCCTCCGAC
GCCGCGTTTGGGGGCATCCTCGAGCGCTACTGGCTATCTTCGCGCGCGGCCGCCATCAAA
GTCAATGACTCAGTGCCCTTCCACCTGGGCTGGAACAGCACGGAGCGCTCGCTGCGGCTT
CAGGCGCGCTACCACGACACGCCCTACAAGCCACCCGCCGGCCGCGCCGCAGCGCCAGAG
CTGAGCTACCGAGTGTGCGTGGGCTCAGACGTCACCTCCATCCACAAGTACATGGTGCGT
CGCTACTTCAACAAGCCGTCAAGGGTGCCAGCACCCGAGGCCTTCCGAGACCCCATTTGG
TCCACATGGGCGCTGTACGGGCGCGCCGTGGACCAGGACAAGGTGCTGCGTTTTGCCCAA
CAGATCCGCCTGCACCACTTCAACAGCAGCCACCTGGAAATCGACGACATGTACACACCT
GCTTATGGCGACTTCGACTTCGATGAGGTCAAATTCCCCAACGCCAGCGACATGTTCCGC
CGCCTGCGCGACGCCGGCTTCCGCGTCACGCTCTGGGTGCACCCTTTTGTCAACTACAAC
TCGTCGCGCTTCGGCGAGGGCGTGGAGCGCGAGCTGTTCGTGCGCGAACCCACGGGCCGG
TTACCTGCGCTGGTGCGCTGGTGGAACGGCATCGGCGCGGTGCTAGACTTCACGCACCCA
AAGGCCCGCGACTGGTTCCAGGGACACCTGCGGCGGCTGCGCTCTCGCTACTCCGTGGCT
TCCTTCAAGTTCGACGCGGGCGAGGTCAGCTACCTGCCGCGGGACTTCAGCACCTACCGG
CCGCTGCCGGACCCCAGCGTCTGGAGCCGGCGCTACACTGAGATGGCGCTGCCCTTCTTC
TCGCTGGCGGAGGTGCGCGTAGGCTACCAGTCACAGAACATCTCCTGCTTCTTCCGCCTG
GTGGATCGCGACTCTGTGTGGGGCTACGACCTGGGGTTGCGCTCACTCATCCCCGCGGTG
CTCACCGTCAGCATGCTGGGCTACCCATTCATCCTACCCGATATGGTGGGCGGCAACGCC
GTGCCCCAGCGGACAGCCGGCGGCGATGTGCCCGAGCGCGAGCTCTACATTCGCTGGCTG
GAAGTGGCCGCCTTTATGCCGGCCATGCAGTTCTCTATCCCGCCCTGGCGCTACGACGCG
GAAGTGGTGGCCATCGCGCAGAAGTTCGCCGCCCTGCGGGCCTCGCTTGTGGCACCGCTG
TTGCTTGAGCTGGCGGGCGAGGTCACCGACACGGGTGACCCTATCGTGCGCCCCCTTTGG
TGGATTGCGCCCGGCGACGAGACAGCTCACCGTATCGACTCGCAGTTCCTTATTGGGGAC
ACGCTGCTTGTGGCCCCGGTGCTGGAGCCAGGCAAGCAGGAGCGCGACGTCTATTTGCCC
GCCGGCAAGTGGCGCAGCTACAAGGGTGAGCTTTTCGACAAGACGCCGGTGCTGCTCACC
GATTACCCGGTCGACCTGGATGAGATCGCCTACTTTACCTGGGCGTCCGTTTAAACGAAT
TCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGC
TGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGC
ATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTAT
ATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACT
GCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCT
GACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCT
TTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCT
GGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCG
CCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTT
CGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTA
TTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTG
TCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAA
CTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCT
GTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGG
CAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCA
ATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACAT
CGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGAC
GAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCG
GATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAA
AATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAG
GACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGC
TTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTT
CTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCA
ACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGC
AGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTT
GCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAG
TCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTC
CCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCC
TTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGT
CGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTT
ATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGC
AGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAA
GTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAA
GCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGG
TAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGA
AGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGG
GATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAA
TACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGC
TTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATAC
GGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTAC
CTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTAT
GGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCA
CGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACG
CAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGA
CCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCA
TGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGG
CCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGG
GAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCAT
AAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTC
TACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 2040 bp
Length: 2040 bp Restriction map B
Restriction map B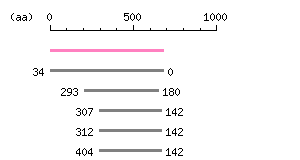

 more Linker info
more Linker info
{kind=link}