Nucleotide Sequence (with vector) for pF1KSDA1088
Download
>pF1KSDA1088 7337 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT
AGAACCATGCCCAAGATAGTCCTGAATGGTGTGACCGTAGACTTCCCTTTCCAGCCCTAC
AAATGCCAACAGGAGTACATGACCAAGGTCCTGGAATGTCTGCAGCAGAAGGTGAATGGC
ATCCTGGAGAGCCCTACGGGTACAGGGAAGACGCTGTGCCTGCTGTGCACCACGCTGGCC
TGGCGAGAACACCTCCGAGACGGCATCTCTGCCCGCAAGATTGCCGAGAGGGCGCAAGGA
GAGCTTTTCCCGGATCGGGCCTTGTCATCCTGGGGCAACGCTGCTGCTGCTGCTGGAGAC
CCCATAGCTTGCTACACGGACATCCCAAAGATTATTTACGCCTCCAGGACCCACTCGCAA
CTCACACAGGTCATCAACGAGCTTCGGAACACCTCCTACCGGCCTAAGGTGTGTGTGCTG
GGCTCCCGGGAGCAGCTGTGCATCCATCCTGAGGTGAAGAAACAAGAGAGTAACCATCTA
CAGATCCACTTGTGCCGTAAGAAGGTGGCAAGTCGCTCCTGTCATTTCTACAACAACGTA
GAAGAAAAAAGCCTGGAGCAGGAGCTGGCCAGCCCCATCCTGGACATTGAGGACTTGGTC
AAGAGCGGAAGCAAGCACAGGGTGTGCCCTTACTACCTGTCCCGGAACCTGAAGCAGCAA
GCCGACATCATATTCATGCCGTACAATTACTTGTTGGATGCCAAGAGCCGCAGAGCACAC
AACATTGACCTGAAGGGGACAGTCGTGATCTTTGACGAAGCTCACAACGTGGAGAAGATG
TGTGAAGAATCGGCATCCTTTGACCTGACTCCCCATGACCTGGCTTCAGGACTGGACGTC
ATAGACCAGGTGCTGGAGGAGCAGACCAAGGCAGCGCAGCAGGGTGAGCCCCACCCGGAG
TTCAGCGCGGACTCCCCCAGCCCAGGGCTGAACATGGAGCTGGAAGACATTGCAAAGCTG
AAGATGATCCTGCTGCGCCTGGAGGGGGCCATCGATGCTGTTGAGCTGCCTGGAGACGAC
AGCGGTGTCACCAAGCCAGGGAGCTACATCTTTGAGCTGTTTGCTGAAGCCCAGATCACG
TTTCAGACCAAGGGCTGCATCCTGGACTCGCTGGACCAGATCATCCAGCACCTGGCAGGA
CGTGCTGGAGTGTTCACCAACACGGCCGGACTGCAGAAGCTGGCGGACATTATCCAGATT
GTGTTCAGTGTGGACCCCTCCGAGGGCAGCCCTGGTTCCCCAGCAGGGCTGGGGGCCTTA
CAGTCCTATAAGGTGCACATCCATCCTGATGCTGGTCACCGGAGGACGGCTCAGCGGTCT
GATGCCTGGAGCACCACTGCAGCCAGAAAGCGAGGGAAGGTGCTGAGCTACTGGTGCTTC
AGTCCCGGCCACAGCATGCACGAGCTGGTCCGCCAGGGCGTCCGCTCCCTCATCCTTACC
AGCGGCACGCTGGCCCCGGTGTCCTCCTTTGCTCTGGAGATGCAGATCCCTTTCCCAGTC
TGCCTGGAGAACCCACACATCATCGACAAGCACCAGATCTGGGTGGGGGTCGTCCCCAGA
GGCCCCGATGGAGCCCAGTTGAGCTCCGCGTTTGACAGACGGTTTTCCGAGGAGTGCTTA
TCCTCCCTGGGGAAGGCTCTGGGCAACATCGCCCGCGTGGTGCCCTATGGGCTCCTGATC
TTCTTCCCTTCCTATCCTGTCATGGAGAAGAGCCTGGAGTTCTGGCGGGCCCGCGACTTG
GCCAGGAAGATGGAGGCGCTGAAGCCGCTGTTTGTGGAGCCCAGGAGCAAAGGCAGCTTC
TCCGAGACCATCAGTGCTTACTATGCAAGGGTTGCCGCCCCTGGGTCCACCGGCGCCACC
TTCCTGGCGGTCTGCCGGGGCAAGGCCAGCGAGGGGCTGGACTTCTCAGACACGAATGGC
CGTGGTGTGATTGTCACGGGCCTCCCGTACCCCCCACGCATGGACCCCCGGGTTGTCCTC
AAGATGCAGTTCCTGGACGAGATGAAGGGCCAGGGTGGGGCTGGGGGCCAGTTCCTCTCT
GGGCAGGAGTGGTACCGGCAGCAGGCGTCCAGGGCTGTGAACCAGGCCATCGGGCGAGTG
ATCCGGCACCGCCAGGACTACGGAGCTGTCTTCCTCTGTGACCACAGGTTCGCCTTTGCC
GACGCAAGAGCCCAACTGCCCTCCTGGGTGCGTCCCCACGTCAGGGTGTATGACAACTTT
GGCCATGTCATCCGAGACGTGGCCCAGTTCTTCCGTGTTGCCGAGCGAACTATGCCAGCA
CCGGCCCCCCGGGCTACAGCACCCAGTGTGCGTGGAGAAGATGCTGTCAGCGAGGCCAAG
TCGCCTGGCCCCTTCTTCTCCACCAGGAAAGCTAAGAGTCTGGACCTGCATGTCCCCAGC
CTGAAGCAGAGGTCCTCAGGGTCACCAGCTGCCGGGGACCCCGAGAGTAGCCTGTGTGTG
GAGTATGAGCAGGAGCCAGTTCCTGCCCGGCAGAGGCCCAGGGGGCTGCTGGCCGCCCTG
GAGCACAGCGAACAGCGGGCGGGGAGCCCCGGCGAGGAGCAGGCCCACAGCTGCTCCACC
CTGTCCCTCCTGTCTGAGAAGAGGCCGGCAGAAGAACCGCGAGGAGGGAGGAAGAAGATC
CGGCTGGTCAGCCACCCGGAGGAGCCCGTGGCTGGTGCACAGACGGACAGGGCCAAGCTC
TTCATGGTGGCCGTGAAGCAGGAGTTGAGCCAAGCCAACTTTGCCACCTTCACCCAGGCC
CTGCAGGACTACAAGGGTTCCGATGACTTCGCCGCCCTGGCCGCCTGTCTCGGCCCCCTC
TTTGCTGAGGACCCCAAGAAGCACAACCTGCTCCAAGGCTTCTACCAGTTTGTGCGGCCC
CACCATAAGCAGCAGTTTGAGGAGGTCTGTATCCAGCTGACAGGACGAGGCTGTGGCTAT
CGGCCTGAGCACAGCATTCCCCGAAGGCAGCGGGCACAGCCGGTCCTGGACCCCACTGGA
AGAACGGCGCCGGATCCCAAGCTGACCGTGTCCACGGCTGCAGCCCAGCAGCTGGACCCC
CAAGAGCACCTGAACCAGGGCAGGCCCCACCTGTCGCCCAGGCCACCCCCAACAGGAGAC
CCTGGCAGCCACCCACAGTGGGGGTCTGGAGTGCCCAGAGCAGGGAAGCAGGGCCAGCAC
GCCGTGAGCGCCTACCTGGCTGATGCCCGCAGGGCCCTGGGGTCCGCGGGCTGTAGCCAA
CTCTTGGCAGCGCTGACAGCCTATAAGCAAGACGACGACCTCGACAAGGTGCTGGCTGTG
TTGGCCGCCCTGACCACTGCAAAGCCAGAGGACTTCCCCCTGCTGCACAGGTTCAGCATG
TTTGTGCGTCCACACCACAAGCAGCGCTTCTCACAGACGTGCACAGACCTGACCGGCCGG
CCCTACCCGGGCATGGAGCCACCGGGACCCCAGGAGGAGAGGCTTGCCGTGCCTCCTGTG
CTTACCCACAGGGCTCCCCAACCAGGCCCCTCACGGTCCGAGAAGACCGGGAAGACCCAG
AGCAAGATCTCGTCCTTCCTTAGACAGAGGCCAGCAGGGACTGTGGGGGCGGGCGGTGAG
GATGCAGGTCCCAGCCAGTCCTCAGGACCTCCCCACGGGCCTGCAGCATCTGAGTGGGGT
GAGCCTCATGGGAGAGACATCGCTGGGCAGCAGGCCACGGGAGCTCCGGGCGGGCCCCTC
TCAGCAGGCTGTGTGTGCCAGGGCTGTGGGGCAGAGGACGTGGTGCCCTTCCAGTGCCCT
GCCTGTGACTTCCAGCGCTGCCAAGCCTGCTGGCAACGGCACCTTCAGGCCTCTAGGATG
TGCCCAGCCTGCCACACCGCCTCCAGGAAGCAGAGCGTCATGCAGGTCTTCTGGCCAGAG
CCCCACAAGGACCATGAGGGCGCTGGAGGGGCCAGGCCTGTCGCTGCTGTGCCTGGTGTT
GGCGCTGCCTGCCCTGCTGCCGGTGCCGGCTGTACGCGGAGTGGCAGAAACACCCACCTA
CCCCTGGCGGGACGCAGAGACAGGGGAGCGGCTGGTGTGCGCCCAGTGCCCCCCAGGCAC
CTTTGTGCAGCGGCCGTGCCGCCGAGACAGCCCCACGACGTGTGGCCCGTGTCCACCGCG
CCACTACACGCAGTTCTGGAACTACCTGGAGCGCTGCCGCTACTGCAACGTCCTCTGCGG
GGAGCGTACGTAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACC
TGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGC
TGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGG
TTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTC
TAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTC
CCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACT
GGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCG
TGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAA
GTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGAT
CAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCT
CCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGC
TCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACC
GACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCC
ACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGG
CTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAG
AAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGC
CCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGT
CTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTC
GCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCC
TGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGG
CTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAG
CTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCG
CAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCG
AAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTT
ATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGC
CAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGA
GCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATA
CCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTAC
CGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTG
TAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCC
CGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAG
ACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGT
AGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGT
ATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTG
ATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTAC
GCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCA
GTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCAC
CTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGAT
GGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACC
CTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTT
CGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAG
CGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCG
AGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAG
CCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGG
CAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGC
CGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAAC
GAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTC
TCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAG
GGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCC
TGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCA
AATATGTATCCGCTCAT



 Length: 4200 bp
Length: 4200 bp Restriction map B
Restriction map B
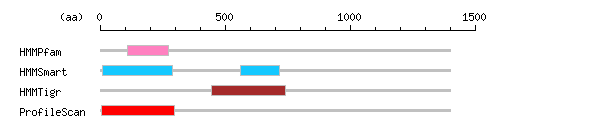
 more Linker info
more Linker info
{kind=link}