Nucleotide Sequence (with vector) for pF1KA0954
Download
>pF1KA0954 6566 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGAGGTGGTG
GACGAGACGGAGGCGCTGCAGCGCTTCTTCGAAGGCCACGACATCAACGGTGCCCTGGAG
CCCTCCAACATAGACACCAGCATCCTGGAGGAGTACATCAGCAAGGAGGATGCCTCCGAC
CTCTGCTTCCCTGACATCTCTGCTCCAGCCAGCTCGGCCTCCTACTCCCACGGGCAGCCT
GCGATGCCTGGCTCCAGCGGGGTCCACCACCTGAGCCCCCCTGGGGGTGGACCCTCCCCG
GGGCGCCATGGTCCCCTCCCACCCCCGGGCTACGGCACCCCGCTGAACTGCAACAACAAC
AACGGCATGGGCGCTGCCCCCAAGCCCTTCCCGGGGGGCACCGGGCCCCCCATCAAGGCT
GAGCCCAAGGCTCCCTATGCCCCAGGCACACTGCCGGACTCTCCCCCAGACTCGGGCTCC
GAGGCCTACTCCCCCCAGCAGGTGAATGAGCCCCACCTCCTGCGCACGATAACCCCTGAG
ACACTGTGCCACGTGGGAGTGCCCTCCCGCCTGGAGCATCCGCCCCCACCTCCAGCCCAC
TTGCCAGGCCCCCCGCCACCCCCACCACCCCCACCTCACTACCCTGTCCTGCAGCGGGAT
CTGTACATGAAGGCCGAGCCCCCGATCCCCCACTACGCTGCCATGGGGCAGGGGCTGGTG
CCCACTGATCTTCACCACACCCAGCAGTCCCAGATGCTGCACCAGCTCCTGCAGCAGCAC
GGAGCTGAGCTCCCTACACACCCCTCCAAGAAGAGGAAGCACTCTGAATCCCCCCCCAGC
ACCCTCAATGCCCAGATGCTGAATGGAATGATCAAACAGGAGCCTGGGACCGTGACAGCC
CTGCCTCTGCACCCCACTCGAGCCCCATCGCCACCCTGGCCTCCCCAGGGTCCGCTCTCC
CCGGGCCCTGGTTCCTTGCCTCTCAGCATTGCCCGTGTCCAGACACCGCCTTGGCACCCG
CCAGGTGCCCCCTCCCCAGGCCTCCTGCAGGACAGTGACAGCCTCAGTGGCTCCTACCTG
GACCCCAACTACCAGTCCATCAAGTGGCAGCCTCATCAGCAGAACAAGTGGGCAACCCTG
TACGATGCTAACTACAAGGAGCTGCCCATGCTCACCTACCGCGTGGATGCGGACAAGGGC
TTCAACTTTTCGGTGGGCGACGACGCCTTTGTGTGCCAGAAGAAGAACCACTTCCAGGTG
ACAGTGTACATCGGCATGCTGGGCGAGCCCAAGTACGTCAAGACGCCCGAGGGCCTCAAG
CCCCTCGACTGCTTCTATCTGAAGCTGCACGGAGTGAAGCTGGAGGCCCTGAACCAGTCC
ATTAACATCGAGCAGTCCCAGTCAGACCGGAGCAAGCGGCCCTTCAACCCGGTCACGGTC
AATCTGCCCCCTGAGCAGGTCACGAAGGTGACTGTGGGGCGGCTGCACTTCAGCGAGACC
ACCGCTAACAACATGCGTAAGAAGGGCAAGCCCAACCCGGACCAGAGGTACTTCATGCTG
GTGGTGGCCCTCCAGGCTCATGCACAGAACCAGAACTACACGCTGGCCGCCCAGATCTCA
GAGCGCATCATTGTGCGGGCCTCCAACCCAGGCCAGTTCGAGAGCGACAGCGATGTGTTG
TGGCAGCGGGCACAGGTGCCCGACACCGTCTTCCACCACGGCCGCGTGGGCATCAACACA
GACCGGCCGGATGAGGCGCTGGTTGTGCACGGGAATGTCAAGGTCATGGGCTCGCTTATG
CACCCCTCCGACCTGCGCGCCAAGGAACACGTGCAGGAGGTGGACACCACCGAGCAATTG
AAGAGGATCTCGCGCATGCGGCTGGTGCACTACAGATACAAGCCCGAGTTCGCCGCCAGC
GCGGGCATCGAGGCCACCGCGCCAGAGACAGGTGTCATCGCTCAGGAGGTGAAGGAGATC
TTGCCTGAGGCTGTGAAAGACACCGGAGACATGGTCTTTGCCAATGGGAAAACCATAGAG
AACTTCCTGGTGGTGAACAAGGAGCGCATCTTCATGGAGAACGTAGGGGCCGTGAAGGAG
CTGTGCAAGCTGACAGACAACCTGGAGACGCGCATTGATGAGCTGGAGCGCTGGAGCCAC
AAGCTGGCCAAGCTGCGGCGGCTCGACAGCCTCAAGTCCACCGGCAGCTCGGGCGCCTTC
AGCCATGCAGGGAGCCAGTTCAGTCGGGCGGGCAGCGTCCCCCACAAGAAGAGGCCCCCC
AAGGTGGCCAGCAAGTCATCGTCCGTGGTTCCGGACCAGGCCTGCATCAGCCAGCGCTTC
CTGCAGGGAACCATCATTGCCCTGGTGGTGGTCATGGCCTTCAGCGTGGTGTCCATGTCC
ACACTGTACGTGCTGAGCCTGCGCACAGAGGAGGACCTGGTAGACACTGATGGCTCTTTT
GCCGTGTCCACTTCCTGTCTCCTGGCCCTGCTCCGGCCCCAGCCCCCTGGGGGGAGTGAG
GCCTTGTGCCCATGGTCCAGCCAGAGCTTTGGGACCACGCAGCTCCGACAGTCCCCCTTG
ACCACGGGGCTACCAGGCATACAGCCCTCTTTGCTGCTGGTGACCACCAGCCTCACCAGC
TCGGCCCCAGGTTCTGCTGTCCGCACCTTGGACATGTGTTCCAGCCACCCCTGCCCTGTC
ATCTGCTGTTCCTCACCCACTACCAACCCTACCACTGGTCCTAGTCTTGGCCCCAGCTTT
AACCCTGGCCATGTTCTCAGCCCAAGTCCCAGCCCCAGCACCAACCGCTCAGGCCCCAGC
CAGATGGCCCTTCTGCCAGTCACCAACATCAGAGCCAAGTCCTGGGGTCTTTCAGTCAAT
GGCATTGGCCACTCCAAGCATCACAAGAGTCTGGAGCCTCTGGCCAGCCCTGCAGTCCCC
TTCCCTGGGGGGCAGGGCAAAGCCAAGAACAGTCCCAGCCTTGGTTTCCATGGCCGGGCC
CGCCGAGGGGCCCTCCAGTCCAGCGTGGGCCCTGCTGAGCCCACCTGGGCCCAGGGCCAG
TCAGCCTCTCTCCTTGCAGAGCCAGTGCCCTCCCTGACCTCCATCCAGGTGCTGGAGAAT
TCGATGTCCATCACCTCCCAGTACTGTGCTCCAGGGGATGCCTGCAGGCCTGGGAACTTC
ACCTACCACATCCCTGTCAGTAGTGGCACCCCACTGCACCTCAGCCTGACTCTGCAGATG
AACTCCTCCTCCCCCGTGTCTGTGGTGCTGTGCAGCCTGAGGTCAAAGGAGGAACCATGT
GAGGAGGGGAGCCTTCCACAGAGTCTCCACACCCACCAGGACACCCAGGGCACCTCTCAC
CGGTGGCCAATAACCATCCTGTCCTTCCGTGAATTCACCTACCACTTCCGGGTGGCACTG
CTGGGTCAGGCCAACTGCAGTTCAGAGGCTCTCGCCCAGCCAGCCACAGACTACCACTTC
CACTTCTACCGCCTGTGTGACGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTA
GAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGA
GTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGT
CTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAAC
CGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCT
TGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTT
CTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTT
GCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAG
CCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCA
AGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCAC
GCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACA
ATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTT
GTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCG
TGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGA
AGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCT
CCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCG
GCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATG
GAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCC
GAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCAT
GGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGAC
TGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATT
GCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCT
CCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTC
TGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGT
AATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCA
GCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCC
CCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACT
ATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCT
GCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAG
CTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCA
CGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAA
CCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGC
GAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAG
AAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGG
TAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCA
GCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTC
TGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAG
GATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTT
CGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTG
GCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCG
GCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAAC
GCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCG
TAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGA
TCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTT
GCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACG
CCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATC
AAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGG
TGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAAC
GGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGA
AGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAA
ATACATTCAAATATGTATCCGCTCAT



 Length: 3453 bp
Length: 3453 bp Restriction map B
Restriction map B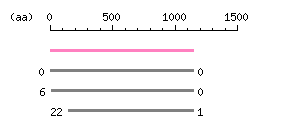

 more Linker info
more Linker info
{kind=link}