


-
SpecieshumanProduct IDFXC01285Cloning SiteSgfI-PmeIGeneKIBB3408SymbolATP2A3
Alias : SERCA3DescriptionATPase, Ca++ transporting, ubiquitous, transcript variant 1Original Clone IDha01215 Length: 2997 bp
Length: 2997 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 999 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)

Entry Exp ID% symbol CCDS45579.1 0 100.0 ATP2A3 CCDS45580.1 0 99.9 ATP2A3 CCDS42234.1 0 100.0 ATP2A3 CCDS11041.1 0 100.0 ATP2A3 CCDS11042.1 0 100.0 ATP2A3
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]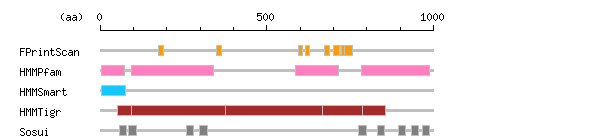 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR001757 176 190 PR00119 ATPase IPR001757 349 363 PR00119 ATPase IPR001757 595 606 PR00119 ATPase IPR001757 617 627 PR00119 ATPase IPR000695 673 689 PR00120 ATPase IPR001757 701 720 PR00119 ATPase IPR000695 701 717 PR00120 ATPase IPR001757 724 736 PR00119 ATPase IPR000695 732 757 PR00120 ATPase HMMPfam IPR004014 5 72 PF00690 ATPase IPR008250 93 341 PF00122 ATPase IPR005834 585 714 PF00702 Haloacid dehalogenase-like hydrolase IPR006068 784 987 PF00689 ATPase HMMSmart IPR004014 3 77 SM00831 ATPase HMMTigr IPR005782 53 856 TIGR01116 ATPase IPR001757 93 376 TIGR01494 ATPase IPR001757 668 786 TIGR01494 ATPase
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 58 EDLLVRILLLAALVSFVLAWFE 79 PRIMARY 22 2 86 TAFVEPLVIMLILVANAIVGVWQ 108 PRIMARY 23 3 258 RQLSHAISVICVAVWVINIGHFA 280 PRIMARY 23 4 299 AVALAVAAIPEGLPAVITTCLAL 321 PRIMARY 23 5 776 FLTAILGLPEALIPVQLLWVNLV 798 SECONDARY 23 6 831 GWLFFRYLAIGVYVGLATVAAAT 853 PRIMARY 23 7 895 FPTTMALSVLVTIEMCNALNSVS 917 SECONDARY 23 8 933 LLVAVAMSMALHFLILLVPPLPL 955 PRIMARY 23 9 966 QWVVVLQISLPVILLDEALKYLS 988 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_005164 999 601929 100.0 100.0 NP_777617 998 601929 99.9 100.0 XP_011522191 1024 601929 100.0 99.4 XP_011522190 1028 601929 100.0 99.4 NP_777618 1029 601929 100.0 99.4 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KB3408 Download>KIBB3408 2997 bp ATGGAGGCGGCGCATCTGCTCCCGGCCGCCGACGTGCTGCGCCACTTCTCGGTGACAGCC GAGGGCGGCCTGAGCCCGGCGCAGGTGACCGGCGCGCGGGAGCGCTACGGCCCCAACGAG CTCCCGAGTGAGGAAGGGAAGTCCCTGTGGGAGCTGGTGCTGGAACAGTTTGAGGACCTC CTGGTGCGCATCCTGCTGCTGGCTGCCCTTGTCTCCTTTGTCCTGGCCTGGTTCGAGGAG GGCGAGGAGACCACGACCGCCTTCGTGGAGCCCCTGGTCATCATGCTGATCCTCGTGGCC AACGCCATTGTGGGCGTGTGGCAGGAACGCAACGCCGAGAGTGCCATCGAGGCCCTGAAG GAGTATGAGCCTGAGATGGGCAAGGTGATCCGCTCGGACCGCAAGGGCGTGCAGAGGATC CGTGCCCGGGACATCGTCCCAGGGGACATTGTAGAAGTGGCAGTGGGGGACAAAGTGCCT GCTGACCTCCGCCTCATCGAGATCAAGTCCACCACGCTGCGAGTGGACCAGTCCATCCTG ACGGGTGAATCTGTGTCCGTGACCAAGCACACAGAGGCCATCCCAGACCCCAGAGCTGTG AACCAGGACAAGAAGAACATGCTGTTTTCTGGCACCAATATCACATCGGGCAAAGCGGTG GGTGTGGCCGTGGCCACCGGCCTGCACACGGAGCTGGGCAAGATCCGGAGCCAGATGGCG GCAGTCGAGCCCGAGCGGACGCCGCTGCAGCGCAAGCTGGACGAGTTTGGACGGCAGCTG TCCCACGCCATCTCTGTGATCTGCGTGGCCGTGTGGGTCATCAACATCGGCCACTTCGCC GACCCGGCCCACGGTGGCTCCTGGCTGCGTGGCGCTGTCTACTACTTCAAGATCGCCGTG GCCCTGGCGGTGGCGGCCATCCCCGAGGGCCTCCCGGCTGTCATCACTACATGCCTGGCA CTGGGCACGCGGCGCATGGCACGCAAGAACGCCATCGTGCGAAGCCTGCCGTCCGTGGAG ACCCTGGGCTGCACCTCAGTCATCTGCTCCGACAAGACGGGCACGCTCACCACCAATCAG ATGTCTGTCTGCCGGATGTTCGTGGTAGCCGAGGCCGATGCGGGCTCCTGCCTTTTGCAC GAGTTCACCATCTCGGGTACCACGTATACCCCCGAGGGCGAAGTGCGGCAGGGGGATCAG CCTGTGCGCTGCGGCCAGTTCGACGGGCTGGTGGAGCTGGCGACCATCTGCGCCCTGTGC AACGACTCGGCTCTGGACTACAACGAGGCCAAGGGTGTGTATGAGAAGGTGGGAGAGGCC ACGGAGACAGCTCTGACTTGCCTGGTGGAGAAGATGAACGTGTTCGACACCGACCTGCAG GCTCTGTCCCGGGTGGAGCGAGCTGGCGCCTGTAACACGGTCATCAAGCAGCTGATGCGG AAGGAGTTCACCCTGGAGTTCTCCCGAGACCGGAAATCCATGTCCGTGTACTGCACGCCC ACCCGCCCTCACCCTACTGGCCAGGGCAGCAAGATGTTTGTGAAGGGGGCTCCTGAGAGT GTGATCGAGCGCTGTAGCTCAGTCCGCGTGGGGAGCCGCACAGCACCCCTGACCCCCACC TCCAGGGAGCAGATCCTGGCAAAGATCCGGGATTGGGGCTCAGGCTCAGACACGCTGCGC TGCCTGGCACTGGCCACCCGGGACGCGCCCCCAAGGAAGGAGGACATGGAGCTGGACGAC TGCAGCAAGTTTGTGCAGTACGAGACGGACCTGACCTTCGTGGGCTGCGTAGGCATGCTG GACCCGCCGCGACCTGAGGTGGCTGCCTGCATCACACGCTGCTACCAGGCGGGCATCCGC GTGGTCATGATCACGGGGGATAACAAAGGCACTGCCGTGGCCATCTGCCGCAGGCTTGGC ATCTTTGGGGACACGGAAGACGTGGCGGGCAAGGCCTACACGGGCCGCGAGTTTGATGAC CTCAGCCCCGAGCAGCAGCGCCAGGCCTGCCGCACCGCCCGCTGCTTCGCCCGCGTGGAG CCCGCACACAAGTCCCGCATCGTGGAGAACCTGCAGTCCTTTAACGAGATCACTGCTATG ACCGGCGATGGAGTGAACGACGCACCAGCCCTGAAGAAAGCAGAGATCGGCATCGCCATG GGCTCAGGCACGGCCGTGGCCAAGTCGGCGGCAGAGATGGTGCTGTCAGATGACAACTTT GCCTCCATCGTGGCTGCGGTGGAGGAGGGCCGGGCCATCTACAGCAACATGAAGCAATTC ATCCGCTACCTCATCTCCTCCAATGTTGGCGAGGTCGTCTGCATCTTCCTCACGGCAATT CTGGGCCTGCCCGAAGCCCTGATCCCTGTGCAGCTGCTCTGGGTGAACCTGGTGACAGAC GGCCTACCTGCCACGGCTCTGGGCTTCAACCCGCCAGACCTGGACATCATGGAGAAGCTG CCCCGGAGCCCCCGAGAAGCCCTCATCAGTGGCTGGCTCTTCTTCCGATACCTGGCTATC GGAGTGTACGTAGGCCTGGCCACAGTGGCTGCCGCCACCTGGTGGTTTGTGTATGACGCC GAGGGACCTCACATCAACTTCTACCAGCTGAGGAACTTCCTGAAGTGCTCAGAAGACAAC CCGCTCTTTGCCGGCATCGACTGTGAGGTGTTCGAGTCACGCTTCCCCACCACCATGGCC TTGTCCGTGCTCGTGACCATTGAAATGTGCAATGCCCTCAACAGCGTCTCGGAGAACCAG TCGCTGCTGCGGATGCCGCCCTGGATGAACCCCTGGCTGCTGGTGGCTGTGGCCATGTCC ATGGCCCTGCACTTCCTCATCCTGCTCGTGCCGCCCCTGCCTCTCATTTTCCAGGTGACC CCACTGAGCGGGCGCCAGTGGGTGGTGGTGCTCCAGATATCTCTGCCTGTCATCCTGCTG GATGAGGCCCTCAAGTACCTGTCCCGGAACCACATGCACGAAGAAATGAGCCAGAAG
Cloned ORF protein sequence for pF1KB3408 Download>KIBB3408 999 aa MEAAHLLPAADVLRHFSVTAEGGLSPAQVTGARERYGPNELPSEEGKSLWELVLEQFEDL LVRILLLAALVSFVLAWFEEGEETTTAFVEPLVIMLILVANAIVGVWQERNAESAIEALK EYEPEMGKVIRSDRKGVQRIRARDIVPGDIVEVAVGDKVPADLRLIEIKSTTLRVDQSIL TGESVSVTKHTEAIPDPRAVNQDKKNMLFSGTNITSGKAVGVAVATGLHTELGKIRSQMA AVEPERTPLQRKLDEFGRQLSHAISVICVAVWVINIGHFADPAHGGSWLRGAVYYFKIAV ALAVAAIPEGLPAVITTCLALGTRRMARKNAIVRSLPSVETLGCTSVICSDKTGTLTTNQ MSVCRMFVVAEADAGSCLLHEFTISGTTYTPEGEVRQGDQPVRCGQFDGLVELATICALC NDSALDYNEAKGVYEKVGEATETALTCLVEKMNVFDTDLQALSRVERAGACNTVIKQLMR KEFTLEFSRDRKSMSVYCTPTRPHPTGQGSKMFVKGAPESVIERCSSVRVGSRTAPLTPT SREQILAKIRDWGSGSDTLRCLALATRDAPPRKEDMELDDCSKFVQYETDLTFVGCVGML DPPRPEVAACITRCYQAGIRVVMITGDNKGTAVAICRRLGIFGDTEDVAGKAYTGREFDD LSPEQQRQACRTARCFARVEPAHKSRIVENLQSFNEITAMTGDGVNDAPALKKAEIGIAM GSGTAVAKSAAEMVLSDDNFASIVAAVEEGRAIYSNMKQFIRYLISSNVGEVVCIFLTAI LGLPEALIPVQLLWVNLVTDGLPATALGFNPPDLDIMEKLPRSPREALISGWLFFRYLAI GVYVGLATVAAATWWFVYDAEGPHINFYQLRNFLKCSEDNPLFAGIDCEVFESRFPTTMA LSVLVTIEMCNALNSVSENQSLLRMPPWMNPWLLVAVAMSMALHFLILLVPPLPLIFQVT PLSGRQWVVVLQISLPVILLDEALKYLSRNHMHEEMSQK
Nucleotide Sequence (with vector) for pF1KB3408 Download>pF1KB3408 6110 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGAGGCGGCG CATCTGCTCCCGGCCGCCGACGTGCTGCGCCACTTCTCGGTGACAGCCGAGGGCGGCCTG AGCCCGGCGCAGGTGACCGGCGCGCGGGAGCGCTACGGCCCCAACGAGCTCCCGAGTGAG GAAGGGAAGTCCCTGTGGGAGCTGGTGCTGGAACAGTTTGAGGACCTCCTGGTGCGCATC CTGCTGCTGGCTGCCCTTGTCTCCTTTGTCCTGGCCTGGTTCGAGGAGGGCGAGGAGACC ACGACCGCCTTCGTGGAGCCCCTGGTCATCATGCTGATCCTCGTGGCCAACGCCATTGTG GGCGTGTGGCAGGAACGCAACGCCGAGAGTGCCATCGAGGCCCTGAAGGAGTATGAGCCT GAGATGGGCAAGGTGATCCGCTCGGACCGCAAGGGCGTGCAGAGGATCCGTGCCCGGGAC ATCGTCCCAGGGGACATTGTAGAAGTGGCAGTGGGGGACAAAGTGCCTGCTGACCTCCGC CTCATCGAGATCAAGTCCACCACGCTGCGAGTGGACCAGTCCATCCTGACGGGTGAATCT GTGTCCGTGACCAAGCACACAGAGGCCATCCCAGACCCCAGAGCTGTGAACCAGGACAAG AAGAACATGCTGTTTTCTGGCACCAATATCACATCGGGCAAAGCGGTGGGTGTGGCCGTG GCCACCGGCCTGCACACGGAGCTGGGCAAGATCCGGAGCCAGATGGCGGCAGTCGAGCCC GAGCGGACGCCGCTGCAGCGCAAGCTGGACGAGTTTGGACGGCAGCTGTCCCACGCCATC TCTGTGATCTGCGTGGCCGTGTGGGTCATCAACATCGGCCACTTCGCCGACCCGGCCCAC GGTGGCTCCTGGCTGCGTGGCGCTGTCTACTACTTCAAGATCGCCGTGGCCCTGGCGGTG GCGGCCATCCCCGAGGGCCTCCCGGCTGTCATCACTACATGCCTGGCACTGGGCACGCGG CGCATGGCACGCAAGAACGCCATCGTGCGAAGCCTGCCGTCCGTGGAGACCCTGGGCTGC ACCTCAGTCATCTGCTCCGACAAGACGGGCACGCTCACCACCAATCAGATGTCTGTCTGC CGGATGTTCGTGGTAGCCGAGGCCGATGCGGGCTCCTGCCTTTTGCACGAGTTCACCATC TCGGGTACCACGTATACCCCCGAGGGCGAAGTGCGGCAGGGGGATCAGCCTGTGCGCTGC GGCCAGTTCGACGGGCTGGTGGAGCTGGCGACCATCTGCGCCCTGTGCAACGACTCGGCT CTGGACTACAACGAGGCCAAGGGTGTGTATGAGAAGGTGGGAGAGGCCACGGAGACAGCT CTGACTTGCCTGGTGGAGAAGATGAACGTGTTCGACACCGACCTGCAGGCTCTGTCCCGG GTGGAGCGAGCTGGCGCCTGTAACACGGTCATCAAGCAGCTGATGCGGAAGGAGTTCACC CTGGAGTTCTCCCGAGACCGGAAATCCATGTCCGTGTACTGCACGCCCACCCGCCCTCAC CCTACTGGCCAGGGCAGCAAGATGTTTGTGAAGGGGGCTCCTGAGAGTGTGATCGAGCGC TGTAGCTCAGTCCGCGTGGGGAGCCGCACAGCACCCCTGACCCCCACCTCCAGGGAGCAG ATCCTGGCAAAGATCCGGGATTGGGGCTCAGGCTCAGACACGCTGCGCTGCCTGGCACTG GCCACCCGGGACGCGCCCCCAAGGAAGGAGGACATGGAGCTGGACGACTGCAGCAAGTTT GTGCAGTACGAGACGGACCTGACCTTCGTGGGCTGCGTAGGCATGCTGGACCCGCCGCGA CCTGAGGTGGCTGCCTGCATCACACGCTGCTACCAGGCGGGCATCCGCGTGGTCATGATC ACGGGGGATAACAAAGGCACTGCCGTGGCCATCTGCCGCAGGCTTGGCATCTTTGGGGAC ACGGAAGACGTGGCGGGCAAGGCCTACACGGGCCGCGAGTTTGATGACCTCAGCCCCGAG CAGCAGCGCCAGGCCTGCCGCACCGCCCGCTGCTTCGCCCGCGTGGAGCCCGCACACAAG TCCCGCATCGTGGAGAACCTGCAGTCCTTTAACGAGATCACTGCTATGACCGGCGATGGA GTGAACGACGCACCAGCCCTGAAGAAAGCAGAGATCGGCATCGCCATGGGCTCAGGCACG GCCGTGGCCAAGTCGGCGGCAGAGATGGTGCTGTCAGATGACAACTTTGCCTCCATCGTG GCTGCGGTGGAGGAGGGCCGGGCCATCTACAGCAACATGAAGCAATTCATCCGCTACCTC ATCTCCTCCAATGTTGGCGAGGTCGTCTGCATCTTCCTCACGGCAATTCTGGGCCTGCCC GAAGCCCTGATCCCTGTGCAGCTGCTCTGGGTGAACCTGGTGACAGACGGCCTACCTGCC ACGGCTCTGGGCTTCAACCCGCCAGACCTGGACATCATGGAGAAGCTGCCCCGGAGCCCC CGAGAAGCCCTCATCAGTGGCTGGCTCTTCTTCCGATACCTGGCTATCGGAGTGTACGTA GGCCTGGCCACAGTGGCTGCCGCCACCTGGTGGTTTGTGTATGACGCCGAGGGACCTCAC ATCAACTTCTACCAGCTGAGGAACTTCCTGAAGTGCTCAGAAGACAACCCGCTCTTTGCC GGCATCGACTGTGAGGTGTTCGAGTCACGCTTCCCCACCACCATGGCCTTGTCCGTGCTC GTGACCATTGAAATGTGCAATGCCCTCAACAGCGTCTCGGAGAACCAGTCGCTGCTGCGG ATGCCGCCCTGGATGAACCCCTGGCTGCTGGTGGCTGTGGCCATGTCCATGGCCCTGCAC TTCCTCATCCTGCTCGTGCCGCCCCTGCCTCTCATTTTCCAGGTGACCCCACTGAGCGGG CGCCAGTGGGTGGTGGTGCTCCAGATATCTCTGCCTGTCATCCTGCTGGATGAGGCCCTC AAGTACCTGTCCCGGAACCACATGCACGAAGAAATGAGCCAGAAGGTTTAAACGAATTCG AGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGC TAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATA ACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATC CGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCA AGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGAC ATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTA GCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGG GCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCA AGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGC ATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTC GGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCA GCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTG CAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTG CTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAG GATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATG CGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGC ATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAA GAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGAT GGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAAT GGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGAC ATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTC CTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTT GACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACC GGACTATAAAAGGATCTAGGTGAAGATCCTTTTTGATAATCTCATGACCAAAATCCCTTA ACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTG AAATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGC GGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAG CAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAA GAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGC CAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGC GCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTA CACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAG AAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCT TCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGA GCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGC GGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATGTTCTTTCCTGCGTT ATCCCCTGATTCTGTGGATAACCGTATTACCGCCTTTGAGTGAGCTGATACCGGAAATAC AGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTC AGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGT TAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTG TCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGT AAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGA TGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAG AAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCC CATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGC GAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCT TTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAG CGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAA CTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTAC AAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}