


-
SpecieshumanProduct IDFXC01951Cloning SiteSgfI-PmeISymbolTLR1
Alias : CD281, TIL, TIL. LPRS5, rsc786Descriptiontoll-like receptor 1 Length: 2358 bp
Length: 2358 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 786 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
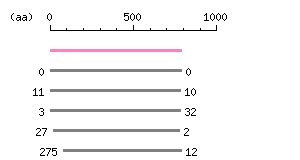
Entry Exp ID% symbol CCDS33973.1 0 99.9 TLR1 CCDS3446.1 3.2e-180 69.4 TLR6 CCDS3445.1 9.2e-123 49.6 TLR10 CCDS3784.1 8e-55 30.2 TLR2 CCDS14152.1 1.9e-20 26.4 TLR8
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR004075 672 699 PR01537 Interleukin-1 receptor IPR004075 710 735 PR01537 Interleukin-1 receptor IPR004075 761 780 PR01537 Interleukin-1 receptor HMMPfam IPR001611 95 110 PF00560 Leucine-rich repeat IPR000157 639 774 PF01582 Toll-Interleukin receptor HMMSmart IPR003591 68 91 SM00369 Leucine-rich repeat IPR003591 113 137 SM00369 Leucine-rich repeat IPR003591 371 394 SM00369 Leucine-rich repeat NULL 371 390 SM00364 NULL NULL 444 463 SM00364 NULL IPR003591 467 491 SM00369 Leucine-rich repeat NULL 467 486 SM00364 NULL IPR000483 524 578 SM00082 Cysteine-rich flanking region IPR000157 636 779 SM00255 Toll-Interleukin receptor ProfileScan IPR001611 46 67 PS51450 Leucine-rich repeat IPR001611 70 91 PS51450 Leucine-rich repeat IPR001611 94 115 PS51450 Leucine-rich repeat IPR001611 116 136 PS51450 Leucine-rich repeat IPR001611 373 394 PS51450 Leucine-rich repeat IPR001611 399 420 PS51450 Leucine-rich repeat IPR001611 424 444 PS51450 Leucine-rich repeat IPR001611 446 467 PS51450 Leucine-rich repeat IPR001611 469 490 PS51450 Leucine-rich repeat IPR001611 491 512 PS51450 Leucine-rich repeat IPR000157 635 779 PS50104 Toll-Interleukin receptor
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 4 IFHFAIIFMLILQIRIQLSEESE 26 SECONDARY 23 2 577 CNITLLIVTIVATMLVLAVTVTS 599 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_003254 786 601194,613223 99.9 100.0 XP_011512046 786 601194,613223 99.9 100.0 XP_011512047 786 601194,613223 99.9 100.0 XP_005262719 786 601194,613223 99.9 100.0 XP_016864060 786 601194,613223 99.9 100.0 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KA0012 Download>KIAA0012 2358 bp ATGACTAGCATCTTCCATTTTGCCATTATCTTCATGTTAATACTTCAGATCAGAATACAA TTATCTGAAGAAAGTGAATTTTTAGTTGATAGGTCAAAAAACGGTCTCATCCACGTTCCT AAAGACCTATCCCAGAAAACAACAATCTTAAATATATCGCAAAATTATATATCTGAGCTT TGGACTTCTGACATCTTATCACTGTCAAAACTGAGGATTTTGATAATTTCTCATAATACA ATCCAGTATCTTGATATCAGTGTTTTCAAATTCAACCAGGAATTGGAATACTTGGATTTG TCCCACAACAAGTTGGTGAAGATTTCTTGCCACCCTACTGTGAACCTCAAGCACTTGGAC CTGTCATTTAATGCATTTGATGCCCTGCCTATATGCAAAGAGTTTGGCAATATGTCTCAA CTAAAATTTCTGGGGTTGAGCACCACACACTTAGAAAAATCTAGTGTGCTGCCAATTGCT CATTTGAATATCAGCAAGGTCTTGCTGGTCTTAGGAGAGACTTATGGGGAAAAAGAAGAC CCTGAGGGCCTTCAAGACTTTAACACTGAGAGTCTGCACATTGTGTTCCCCACAAACAAA GAATTCCATTTTATTTTGGATGTGTCAGTCAAGACTGTAGCAAATCTGGAACTATCTAAT ATCAAATGTGTGCTAGAAGATAACAAATGTTCTTACTTCCTAAGTATTCTGGCGAAACTT CAAACAAATCCAAAGTTATCAAATCTTACCTTAAACAACATTGAAACAACTTGGAATTCT TTCATTAGGATCCTCCAGCTGGTTTGGCATACAACTGTATGGTATTTCTCAATTTCAAAC GTGAAGCTACAGGGTCAGCTGGACTTCAGAGATTTTGATTATTCTGGCACTTCCTTGAAG GCCTTGTCTATACACCAAGTTGTCAGCGATGTGTTCGGTTTTCCGCAAAGTTATATCTAT GAAATCTTTTCGAATATGAACATCAAAAATTTCACAGTGTCTGGTACACGCATGGTCCAC ATGCTTTGCCCATCCAAAATTAGCCCGTTCCTGCATTTGGATTTTTCCAATAATCTCTTA ACAGACACGGTTTTTGAAAATTGTGGGCACCTTACTGAGTTGGAGACACTTATTTTACAA ATGAATCAATTAAAAGAACTTTCAAAAATAGCTGAAATGACTACACAGATGAAGTCTCTG CAACAATTGGATATTAGCCAGAATTCTGTAAGCTATGATGAAAAGAAAGGAGACTGTTCT TGGACTAAAAGTTTATTAAGTTTAAATATGTCTTCAAATATACTTACTGACACTATTTTC AGATGTTTACCTCCCAGGATCAAGGTACTTGATCTTCACAGCAATAAAATAAAGAGCATT CCTAAACAAGTCGTAAAACTGGAAGCTTTGCAAGAACTCAATGTTGCTTTCAATTCTTTA ACTGACCTTCCTGGATGTGGCAGCTTTAGCAGCCTTTCTGTATTGATCATTGATCACAAT TCAGTTTCCCACCCATCGGCTGATTTCTTCCAGAGCTGCCAGAAGATGAGGTCAATAAAA GCAGGGGACAATCCATTCCAATGTACCTGTGAGCTAGGAGAATTTGTCAAAAATATAGAC CAAGTATCAAGTGAAGTGTTAGAGGGCTGGCCTGATTCTTATAAGTGTGACTACCCGGAA AGTTATAGAGGAACCCTACTAAAGGACTTTCACATGTCTGAATTATCCTGCAACATAACT CTGCTGATCGTCACCATCGTTGCCACCATGCTGGTGTTGGCTGTGACTGTGACCTCCCTC TGCAGCTACTTGGATCTGCCCTGGTATCTCAGGATGGTGTGCCAGTGGACCCAGACCCGG CGCAGGGCCAGGAACATACCCTTAGAAGAACTCCAAAGAAATCTCCAGTTTCATGCATTT ATTTCATATAGTGGGCACGATTCTTTCTGGGTGAAGAATGAATTATTGCCAAACCTAGAG AAAGAAGGTATGCAGATTTGCCTTCATGAGAGAAACTTTGTTCCTGGCAAGAGCATTGTG GAAAATATCATCACCTGCATTGAGAAGAGTTACAAGTCCATCTTTGTTTTGTCTCCCAAC TTTGTCCAGAGTGAATGGTGCCATTATGAACTCTACTTTGCCCATCACAATCTCTTTCAT GAAGGATCTAATAGCTTAATCCTGATCTTGCTGGAACCCATTCCGCAGTACTCCATTCCT AGCAGTTATCACAAGCTCAAAAGTCTCATGGCCAGGAGGACTTATTTGGAATGGCCCAAG GAAAAGAGCAAACGTGGCCTTTTTTGGGCTAACTTAAGGGCAGCCATTAATATTAAGCTG ACAGAGCAAGCAAAGAAA
Cloned ORF protein sequence for pF1KA0012 Download>KIAA0012 786 aa MTSIFHFAIIFMLILQIRIQLSEESEFLVDRSKNGLIHVPKDLSQKTTILNISQNYISEL WTSDILSLSKLRILIISHNTIQYLDISVFKFNQELEYLDLSHNKLVKISCHPTVNLKHLD LSFNAFDALPICKEFGNMSQLKFLGLSTTHLEKSSVLPIAHLNISKVLLVLGETYGEKED PEGLQDFNTESLHIVFPTNKEFHFILDVSVKTVANLELSNIKCVLEDNKCSYFLSILAKL QTNPKLSNLTLNNIETTWNSFIRILQLVWHTTVWYFSISNVKLQGQLDFRDFDYSGTSLK ALSIHQVVSDVFGFPQSYIYEIFSNMNIKNFTVSGTRMVHMLCPSKISPFLHLDFSNNLL TDTVFENCGHLTELETLILQMNQLKELSKIAEMTTQMKSLQQLDISQNSVSYDEKKGDCS WTKSLLSLNMSSNILTDTIFRCLPPRIKVLDLHSNKIKSIPKQVVKLEALQELNVAFNSL TDLPGCGSFSSLSVLIIDHNSVSHPSADFFQSCQKMRSIKAGDNPFQCTCELGEFVKNID QVSSEVLEGWPDSYKCDYPESYRGTLLKDFHMSELSCNITLLIVTIVATMLVLAVTVTSL CSYLDLPWYLRMVCQWTQTRRRARNIPLEELQRNLQFHAFISYSGHDSFWVKNELLPNLE KEGMQICLHERNFVPGKSIVENIITCIEKSYKSIFVLSPNFVQSEWCHYELYFAHHNLFH EGSNSLILILLEPIPQYSIPSSYHKLKSLMARRTYLEWPKEKSKRGLFWANLRAAINIKL TEQAKK
Nucleotide Sequence (with vector) for pF1KA0012 Download>pF1KA0012 5471 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGACTAGCATC TTCCATTTTGCCATTATCTTCATGTTAATACTTCAGATCAGAATACAATTATCTGAAGAA AGTGAATTTTTAGTTGATAGGTCAAAAAACGGTCTCATCCACGTTCCTAAAGACCTATCC CAGAAAACAACAATCTTAAATATATCGCAAAATTATATATCTGAGCTTTGGACTTCTGAC ATCTTATCACTGTCAAAACTGAGGATTTTGATAATTTCTCATAATACAATCCAGTATCTT GATATCAGTGTTTTCAAATTCAACCAGGAATTGGAATACTTGGATTTGTCCCACAACAAG TTGGTGAAGATTTCTTGCCACCCTACTGTGAACCTCAAGCACTTGGACCTGTCATTTAAT GCATTTGATGCCCTGCCTATATGCAAAGAGTTTGGCAATATGTCTCAACTAAAATTTCTG GGGTTGAGCACCACACACTTAGAAAAATCTAGTGTGCTGCCAATTGCTCATTTGAATATC AGCAAGGTCTTGCTGGTCTTAGGAGAGACTTATGGGGAAAAAGAAGACCCTGAGGGCCTT CAAGACTTTAACACTGAGAGTCTGCACATTGTGTTCCCCACAAACAAAGAATTCCATTTT ATTTTGGATGTGTCAGTCAAGACTGTAGCAAATCTGGAACTATCTAATATCAAATGTGTG CTAGAAGATAACAAATGTTCTTACTTCCTAAGTATTCTGGCGAAACTTCAAACAAATCCA AAGTTATCAAATCTTACCTTAAACAACATTGAAACAACTTGGAATTCTTTCATTAGGATC CTCCAGCTGGTTTGGCATACAACTGTATGGTATTTCTCAATTTCAAACGTGAAGCTACAG GGTCAGCTGGACTTCAGAGATTTTGATTATTCTGGCACTTCCTTGAAGGCCTTGTCTATA CACCAAGTTGTCAGCGATGTGTTCGGTTTTCCGCAAAGTTATATCTATGAAATCTTTTCG AATATGAACATCAAAAATTTCACAGTGTCTGGTACACGCATGGTCCACATGCTTTGCCCA TCCAAAATTAGCCCGTTCCTGCATTTGGATTTTTCCAATAATCTCTTAACAGACACGGTT TTTGAAAATTGTGGGCACCTTACTGAGTTGGAGACACTTATTTTACAAATGAATCAATTA AAAGAACTTTCAAAAATAGCTGAAATGACTACACAGATGAAGTCTCTGCAACAATTGGAT ATTAGCCAGAATTCTGTAAGCTATGATGAAAAGAAAGGAGACTGTTCTTGGACTAAAAGT TTATTAAGTTTAAATATGTCTTCAAATATACTTACTGACACTATTTTCAGATGTTTACCT CCCAGGATCAAGGTACTTGATCTTCACAGCAATAAAATAAAGAGCATTCCTAAACAAGTC GTAAAACTGGAAGCTTTGCAAGAACTCAATGTTGCTTTCAATTCTTTAACTGACCTTCCT GGATGTGGCAGCTTTAGCAGCCTTTCTGTATTGATCATTGATCACAATTCAGTTTCCCAC CCATCGGCTGATTTCTTCCAGAGCTGCCAGAAGATGAGGTCAATAAAAGCAGGGGACAAT CCATTCCAATGTACCTGTGAGCTAGGAGAATTTGTCAAAAATATAGACCAAGTATCAAGT GAAGTGTTAGAGGGCTGGCCTGATTCTTATAAGTGTGACTACCCGGAAAGTTATAGAGGA ACCCTACTAAAGGACTTTCACATGTCTGAATTATCCTGCAACATAACTCTGCTGATCGTC ACCATCGTTGCCACCATGCTGGTGTTGGCTGTGACTGTGACCTCCCTCTGCAGCTACTTG GATCTGCCCTGGTATCTCAGGATGGTGTGCCAGTGGACCCAGACCCGGCGCAGGGCCAGG AACATACCCTTAGAAGAACTCCAAAGAAATCTCCAGTTTCATGCATTTATTTCATATAGT GGGCACGATTCTTTCTGGGTGAAGAATGAATTATTGCCAAACCTAGAGAAAGAAGGTATG CAGATTTGCCTTCATGAGAGAAACTTTGTTCCTGGCAAGAGCATTGTGGAAAATATCATC ACCTGCATTGAGAAGAGTTACAAGTCCATCTTTGTTTTGTCTCCCAACTTTGTCCAGAGT GAATGGTGCCATTATGAACTCTACTTTGCCCATCACAATCTCTTTCATGAAGGATCTAAT AGCTTAATCCTGATCTTGCTGGAACCCATTCCGCAGTACTCCATTCCTAGCAGTTATCAC AAGCTCAAAAGTCTCATGGCCAGGAGGACTTATTTGGAATGGCCCAAGGAAAAGAGCAAA CGTGGCCTTTTTTGGGCTAACTTAAGGGCAGCCATTAATATTAAGCTGACAGAGCAAGCA AAGAAAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGG CATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCAC CGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTT GCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTA TCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGT CCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTT CTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCT TCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAAC TGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAG ACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCC GCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGAT GCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTG TCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACG GGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTA TTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTA TCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTC GACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTC GATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGG CTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTG CCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGT GTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGC GGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGC ATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGA CCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCAC AGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAA CCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCA CAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGC GTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATA CCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTA TCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCA GCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGA CTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGG TGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGG TATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGG CAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAG AAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAA CGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGAT CCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAA ACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGG TTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTG GTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGC GTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAA ACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGAT ACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAG CGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGG TAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGG CTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGA GTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGC GGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGG ATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATG TATCCGCTCAT
 more Linker info
more Linker info
{kind=link}