Nucleotide Sequence (with vector) for pF1KA1364
Download
>pF1KA1364 5957 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGAGGAGAGG
AAGCATGAGACCATGAACCCAGCTCATGTCCTCTTTGACCGGTTTGTCCAGGCCACCACC
TGCAAGGGAACCCTCAAGGCTTTCCAGGAGCTCTGTGACCACCTGGAACTAAAGCCAAAG
GACTACCGCTCCTTCTATCACAAGCTCAAGTCCAAGCTTAACTACTGGAAAGCCAAAGCC
CTCTGGGCAAAATTGGACAAACGGGGCAGTCACAAAGACTACAAAAAGGGAAAAGCGTGC
ACTAACACCAAGTGTCTCATCATTGGGGCTGGCCCCTGTGGTCTCCGTACAGCCATCGAC
TTATCCTTACTGGGGGCCAAGGTGGTTGTTATTGAGAAACGAGATGCCTTCTCCCGCAAC
AACGTCTTGCATCTCTGGCCATTCACCATACATGATCTACGAGGTCTGGGTGCCAAGAAG
TTCTATGGCAAGTTCTGTGCTGGAGCCATCGACCATATCAGTATCCGTCAGCTCCAACTA
ATACTTTTGAAAGTAGCCTTGATCCTAGGCATTGAAATCCACGTCAATGTGGAATTCCAA
GGACTTATACAGCCTCCTGAGGACCAAGAGAATGAACGGATAGGCTGGCGGGCACTGGTG
CACCCCAAGACTCATCCTGTGTCAGAGTATGAATTTGAAGTGATCATCGGTGGGGATGGT
CGGAGGAACACCTTGGAAGGGTTTCGTCGGAAAGAATTCCGTGGCAAACTGGCCATCGCC
ATCACGGCAAATTTTATCAACCGAAATACAACAGCAGAAGCTAAAGTGGAAGAGATCAGT
GGTGTGGCTTTTATATTCAACCAAAAATTTTTCCAGGAACTGAGGGAAGCCACAGGTATT
GACTTGGAGAACATCGTTTACTACAAAGATGACACACACTATTTCGTTATGACAGCCAAA
AAGCAGAGTTTGCTGGACAAAGGAGTGATACTACATGACTACGCCGACACAGAGCTCCTG
CTTTCCCGAGAAAACGTGGACCAGGAGGCTCTGCTCAGCTATGCCAGGGAGGCGGCAGAC
TTCTCTACCCAGCAGCAGCTGCCGTCTCTGGATTTTGCCATCAATCACTATGGGCAGCCC
GATGTGGCCATGTTTGACTTCACTTGTATGTATGCCTCCGAGAACGCCGCCTTGGTGCGG
GAGCAGAACGGACACCAGTTACTAGTGGCTCTGGTCGGGGACAGCCTCCTAGAGCCTTTC
TGGCCAATGGGAACAGGAATAGCCCGGGGCTTTCTAGCTGCTATGGACTCTGCCTGGATG
GTCCGAAGTTGGTCTCTAGGAACGAGCCCTTTGGAAGTGCTGGCAGAGAGGGAAAGTATT
TACAGGTTGCTGCCTCAGACCACCCCTGAGAATGTGAGTAAGAACTTCAGCCAGTACAGT
ATCGACCCTGTCACTCGGTATCCCAATATCAACGTCAACTTCCTCCGGCCAAGCCAGGTG
CGCCATTTATATGATACTGGCGAAACAAAAGATATTCACCTGGAAATGGAGAGCCTGGTG
AATTCCCGAACCACCCCCAAATTGACTCGCAATGAGTCTGTAGCTCGTTCAAGCAAACTG
CTGGGTTGGTGCCAGAGGCAGACAGATGGCTATGCAGGGGTAAACGTGACAGATCTCACC
ATGTCCTGGAAAAGTGGCTTGGCCCTTTGTGCAATTATCCATAGATACCGCCCTGACCTG
ATAGATTTTGATTCTTTGGATGAGCAAAATGTGGAGAAGAATAACCAACTGGCCTTTGAC
ATTGCTGAGAAGGAATTGGGCATTTCTCCCATCATGACAGGCAAAGAAATGGCCTCCGTG
GGGGAGCCTGATAAGCTGTCCATGGTGATGTACCTGACTCAGTTCTACGAGATGTTTAAG
GACTCCCTCCCCTCTAGCGACACCTTGGACCTAAATGCCGAGGAGAAAGCAGTCCTGATA
GCCAGCACCAGATCCCCTATCTCCTTCCTAAGCAAACTTGGCCAGACCATCTCTCGGAAG
CGTTCTCCCAAGGATAAAAAGGAAAAGGACTTGGATGGTGCTGGGAAGAGGAGAAAGACC
AGTCAATCAGAGGAGGAGGAAGCTCCTCGGGGCCACAGAGGAGAAAGACCGACCCTGGTG
AGCACTCTGACAGACAGGAGGATGGACGTTGCCGTTGGGAACCAGAACAAAGTGAAGTAC
ATGGCGACCCAGCTGCTGGCCAAATTTGAAGAGAATGCGCCCGCACAGTCCATCGGCATA
CGGAGACAGGGCTCCATGAAGAAGGAGTTCCCACAGAACCTGGGAGGCAGCGACACATGC
TACTTCTGCCAGAAGCGGGTCTACGTGATGGAGAGGCTGAGTGCCGAGGGCAAGTTCTTC
CACCGGAGCTGCTTCAAGTGCGAGTACTGCGCCACCACCCTGCGCCTCTCGGCCTACGCC
TACGACATCGAGGATGGTAAATTCTACTGTAAGCCACACTACTGCTATCGACTCTCTGGC
TACGCACAAAGGAAGAGACCGGCAGTGGCTCCCCTGTCTGGAAAGGAGGCCAAAGGACCC
CTGCAGGATGGCGCCACCACAGATGCAAACGGACGGGCCAACGCCGTGGCCAGCTCCACT
GAGAGAACCCCAGGTTCAGGCGTGAACGGCCTGGAGGAGCCCAGCATCGCCAAGCGACTG
AGGGGCACCCCAGAGCGGATCGAGCTGGAGAACTACCGCCTGTCCCTGAGGCAGGCTGAG
GCACTGCAGGAGGTACCGGAGGAGACTCAGGCCGAGCACAACCTGAGCAGCGTGCTGGAC
ACGGGCGCCGAGGAGGACGTCGCCAGCAGGTCAGCACGCAGGGCTGCAGGGCGCCCACCC
GCCACACGGCCCGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACC
TGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGC
TGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGG
TTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTC
TAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTC
CCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACT
GGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCG
TGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAA
GTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGAT
CAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCT
CCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGC
TCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACC
GACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCC
ACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGG
CTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAG
AAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGC
CCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGT
CTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTC
GCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCC
TGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGG
CTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAG
CTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCG
CAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCG
AAATGACCGACCAAGCGACGCCCAACCGGACTATAAAAGGATCTAGGTGAAGATCCTTTT
TGATAATCTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCC
CGTAGAAAAGATCAAAGGATCTTCTTGAAATCCTTTTTTTCTGCGCGTAATCTGCTGCTT
GCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAAC
TCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGT
GTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCT
GCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGA
CTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCAC
ACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCTATG
AGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGT
CGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCC
TGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCG
GAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCC
TTTTGCTCACATGTTCTTTCCTGCGTTATCCCCTGATTCTGTGGATAACCGTATTACCGC
CTTTGAGTGAGCTGATACCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGAT
GGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACC
CTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTT
CGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAG
CGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCG
AGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAG
CCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGG
CAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGC
CGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAAC
GAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTC
TCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAG
GGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCC
TGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCA
AATATGTATCCGCTCAT



 Length: 2844 bp
Length: 2844 bp Restriction map B
Restriction map B
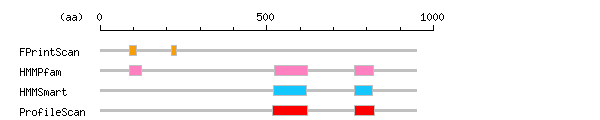
 more Linker info
more Linker info
{kind=link}