Nucleotide Sequence (with vector) for pF1KA1405
Download
>pF1KA1405 6200 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGCCTCCGAG
GCGGTGAAGGTTGTCGTGCGCTGCCGTCCCATGAACCAGCGGGAGCGAGAGCTGCGCTGC
CAGCCCGTGGTGACTGTGGACTGCGCGCGCGCCCAGTGCTGCATCCAGAACCCGGGCGCC
GCCGACGAGCCGCCCAAGCAGTTCACCTTCGACGGCGCCTACCACGTGGACCACGTCACC
GAGCAGATCTACAACGAGATCGCCTATCCGCTGGTGGAGGGCGTCACTGAGGGCTACAAT
GGCACCATCTTTGCCTACGGCCAGACAGGCAGCGGGAAGTCCTTCACCATGCAGGGCCTG
CCGGATCCGCCCTCCCAGAGAGGCATCATCCCCAGGGCCTTCGAGCACGTGTTCGAGAGC
GTCCAGTGTGCAGAGAACACTAAGTTCCTGGTCCGGGCCTCCTACCTGGAGATCTACAAT
GAAGATGTCCGGGACCTCCTTGGGGCTGACACCAAGCAGAAGCTGGAGCTGAAGGAGCAC
CCAGAGAAGGGCGTGTACGTGAAGGGGCTGTCCATGCACACGGTGCACAGCGTGGCCCAG
TGTGAGCACATCATGGAGACTGGCTGGAAGAACCGTTCGGTCGGCTACACGCTGATGAAC
AAGGATTCCTCACGCTCGCACTCCATCTTCACCATCAGCATCGAGATGTCTGCCGTGGAT
GAGCGGGGCAAGGACCACCTCCGGGCGGGCAAGCTGAACCTGGTGGACCTGGCGGGCAGC
GAGCGGCAGTCCAAGACCGGGGCCACGGGCGAGCGGCTCAAGGAGGCCACCAAGATCAAC
CTGTCGCTCTCGGCACTGGGCAATGTCATCTCGGCGCTGGTGGACGGGCGCTGTAAGCAC
GTCCCCTACCGTGACTCGAAGCTGACGCGGCTGCTGCAGGACTCACTGGGCGGCAACACC
AAGACGCTCATGGTGGCCTGCCTGTCGCCTGCGGACAACAACTACGATGAGACACTCAGC
ACGCTGCGCTACGCCAACCGGGCCAAGAACATCAGGAACAAGCCGCGCATCAATGAGGAC
CCCAAGGATGCGCTGCTTCGCGAGTACCAGGAGGAGATCAAGAAGCTCAAGGCCATCCTG
ACACAGCAGATGAGCCCCAGCAGCCTGTCAGCCCTGCTGTCCAGGCAGGTGCCCCCAGAC
CCTGTGCAGGTGGAGGAGAAGCTGTTGCCCCAACCTGTGATCCAGCATGACATGGAGGCC
GAGAAGCAGCTGATCCGGGAGGAGTATGAAGAGCGCCTGGCCCGGCTGAAAGCCGACTAT
AAGGCCGAGCAGGAGTCTCGGGCCAGGCTGGAGGAAGACATCACTGCCATGCGCAACTCA
TATGACGTCAGGCTGTCCACGCTGGAGGAGAACCTGCGGAAGGAGACAGAGGCTGTCCTG
CAGGTGGGAGTCCTCTACAAGGCTGAGGTCATGTCCAGGGCTGAGTTTGCCAGCAGCGCT
GAGTACCCGCCTGCTTTTCAGTATGAGACAGTGGTGAAACCCAAGGTCTTCTCCACGACT
GACACTCTGCCCAGTGACGATGTCTCCAAGACTCAGGTTTCCTCCAGGTTTGCGGAGCTG
CCCAAGGTGGAACCCTCCAAATCTGAGATTTCTCTGGGCTCCAGTGAGTCATCCTCGCTC
GAAGAAACCTCTGTGTCCGAGGCTTTCCCTGGGCCTGAGGAGCCCTCCAACGTGGAGGTC
TCCATGCCCACTGAGGAGTCCAGGAGCAGATACTTCCTGGATGAGTGCCTCGGGCAGGAG
GCCGCTGGGCACCTGCTGGGGGAACAGAACTACCTCCCGCAAGAGGAGCCGCAGGAGGTG
CCCCTGCAGGGGTTACTAGGCCTGCAGGACCCGTTTGCCGAGGTGGAAGCCAAGCTGGCC
AGACTCTCCTCCACCGTGGCCAGGACAGATGCACCCCAGGCAGACGTCCCCAAGGTCCCT
GTGCAGGTCCCTGCGCCGACAGACCTGCTGGAGCCCAGTGATGCCAGGCCCGAAGCCGAG
GCGGCTGATGACTTCCCGCCCAGGCCTGAGGTAGATCTGGCCTCGGAAGTGGCCTTAGAG
GTGGTGCGGACAGCAGAGCCTGGCGTGTGGTTGGAGGCTCAGGCCCCGGTGGCCCTGGTG
GCTCAGCCTGAGCCCCTGCCGGCCACAGCTGGTGTGAAGAGGGAGAGCGTGGGCATGGAG
GTGGCAGTGCTGACTGATGACCCGCTGCCCGTTGTGGACCAGCAGCAGGTGCTGGCCCGT
CTGCAGCTGTTGGAGCAGCAGGTTGTGGGTGGAGAGCAGGCCAAGAACAAGGACCTGAAG
GAGAAGCACAAGCGGCGCAAGCGCTACGCAGACGAGCGCAGGAAGCAGCTGGTGGCTGCC
CTGCAGAACTCGGATGAGGACAGCGGGGACTGGGTGCTGCTTAACGTCTACGACTCCATC
CAGGAGGAAGTGCGGGCCAAGAGCAAGCTGCTGGAGAAGATGCAGAGGAAGCTTCGGGCA
GCAGAGGTGGAGATCAAAGATCTGCAGTCCGAGTTTCAGCTGGAGAAGATCGATTACTTG
GCCACCATCCGCCGGCAGGAGCGTGACTCCATGCTCTTGCAGCAGCTCCTGGAGCAGGTG
CAGCCCCTGATTCGCAGGGACTGTAACTACAGCAACCTGGAGAAGATTCTGCGTGAGTCC
TGCTGGGACGAAGATAACGGCTTCTGGAAGATCCCACATCCCGTCATCACAAAAACCAGC
CTCCCAGTAGCAGTTTCAACTGGGCCACAGAACAAACCAGCCCGCAAAACCTCTGCAGCA
GACAATGGCGAGCCGAACATGGAGGAGGACCGCTACAGGCTCATGCTCAGTCGGAGCAAC
AGTGAAAACATTGCCAGCAACTACTTCCGATCTAAGTGGGCCAGCCAGATCCTCAGCACA
GACGCCAGGAAGAGCCTCACACATCACAACTCGCCACCAGGCCTCAGCTGCCCACTCAGC
AACAACTCTGCCATCCCACCCACCCAGGCCCCTGAAATGCCCCAGCCCCGGCCCTTCCGC
CTCGAGTCCCTCGACATCCCTTTCACCAAGGCCAAGCGTAAGAAAAGCAAAAGCAACTTT
GGCAGTGAGCCTCTGGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCG
ACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGC
TGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAG
GGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCA
GTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTT
TTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGG
ACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCA
GCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGC
AAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCT
GATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGT
TCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGC
TGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAG
ACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTG
GCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGAC
TGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCC
GAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACC
TGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCC
GGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTG
TTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGAT
GCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGC
CGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAA
GAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGAT
TCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGT
TCGAAATGACCGACCAAGCGACGCCCAACCGGACTATAAAAGGATCTAGGTGAAGATCCT
TTTTGATAATCTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGA
CCCCGTAGAAAAGATCAAAGGATCTTCTTGAAATCCTTTTTTTCTGCGCGTAATCTGCTG
CTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACC
AACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCT
AGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGC
TCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTT
GGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTG
CACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCT
ATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAG
GGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAG
TCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGG
GCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTG
GCCTTTTGCTCACATGTTCTTTCCTGCGTTATCCCCTGATTCTGTGGATAACCGTATTAC
CGCCTTTGAGTGAGCTGATACCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGG
GATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGT
ACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTT
TTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTT
TAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCA
TCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTT
CAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGG
CGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAG
CGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAA
AACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACG
CTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCG
GAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCA
TCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACAT
TCAAATATGTATCCGCTCAT



 Length: 3087 bp
Length: 3087 bp Restriction map B
Restriction map B
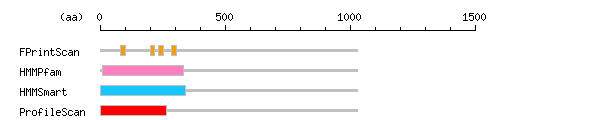
 more Linker info
more Linker info
{kind=link}