


-
SpecieshumanProduct IDFXC07732Cloning SiteSgfI-PmeIGeneKIBB8986SymbolCX3CR1
Alias : CCRL1, CMKBRL1, CMKDR1, GPR13, GPRV28, V28Descriptionchemokine (C-X3-C motif) receptor 1, transcript variant 1Original Clone IDcp01021 Length: 1161 bp
Length: 1161 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 387 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)

Entry Exp ID% symbol CCDS54571.1 6.8e-116 99.2 CX3CR1 CCDS43069.1 3.1e-106 99.4 CX3CR1 CCDS2656.1 9.9e-40 42.3 CCR4 CCDS2684.1 2.9e-39 39.7 CCR8 CCDS46813.1 8.9e-39 47.2 CCR2
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]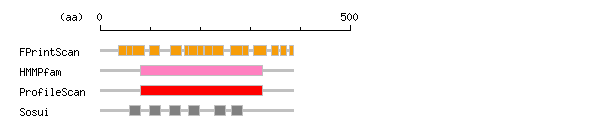 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR005387 36 52 PR01562 CX3C chemokine fractalkine receptor IPR005387 53 69 PR01562 CX3C chemokine fractalkine receptor IPR000276 65 89 PR00237 GPCR IPR000276 98 119 PR00237 GPCR IPR000276 141 163 PR00237 GPCR IPR005387 168 178 PR01562 CX3C chemokine fractalkine receptor IPR000276 177 198 PR00237 GPCR IPR005387 195 206 PR01562 CX3C chemokine fractalkine receptor IPR005387 208 226 PR01562 CX3C chemokine fractalkine receptor IPR000276 224 247 PR00237 GPCR IPR000276 261 285 PR00237 GPCR IPR005387 284 297 PR01562 CX3C chemokine fractalkine receptor IPR000276 307 333 PR00237 GPCR IPR005387 342 357 PR01562 CX3C chemokine fractalkine receptor IPR005387 360 372 PR01562 CX3C chemokine fractalkine receptor IPR005387 378 387 PR01562 CX3C chemokine fractalkine receptor HMMPfam IPR000276 80 325 PF00001 GPCR ProfileScan IPR017452 80 325 PS50262 GPCR
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 59 VVFGTVFLSIFYSVIFAIGLVGN 81 PRIMARY 23 2 98 TDIYLLNLALSDLLFVATLPFWT 120 SECONDARY 23 3 139 AFFFIGFFGSIFFITVISIDRYL 161 SECONDARY 23 4 177 HGVTISLGVWAAAILVAAPQFMF 199 SECONDARY 23 5 229 FLGFLLPLLIMSYCYFRIIQTLF 251 SECONDARY 23 6 263 KLILLVVIVFFLFWTPYNIMIFL 285 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_001164645 387 601470,607339,609423,613784 99.2 100.0 NP_001328 355 601470,607339,609423,613784 99.4 91.7 NP_001164643 355 601470,607339,609423,613784 99.4 91.7 NP_001164642 355 601470,607339,609423,613784 99.4 91.7 XP_016861176 360 604836 42.3 89.1 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KB8986 Download>KIBB8986 1161 bp ATGAGAGAACCCCTGGAGGCGTTGAAGTTGGCAGACTTGGATTTCAGGAAGAGCTCTCTG GCTTCTGGGTGGAGAATGGCCAGTGGGGCCTTCACCATGGATCAGTTCCCTGAATCAGTG ACAGAAAACTTTGAGTACGATGATTTGGCTGAGGCCTGTTATATTGGGGACATCGTGGTC TTTGGGACTGTGTTCCTGTCCATATTCTACTCCGTCATCTTTGCCATTGGCCTGGTGGGA AATTTGTTGGTAGTGTTTGCCCTCACCAACAGCAAGAAGCCCAAGAGTGTCACCGACATT TACCTCCTGAACCTGGCCTTGTCTGATCTGCTGTTTGTAGCCACTTTGCCCTTCTGGACT CACTATTTGATAAATGAAAAGGGCCTCCACAATGCCATGTGCAAATTCACTACCGCCTTC TTCTTCATCGGCTTTTTTGGAAGCATATTCTTCATCACCGTCATCAGCATTGATAGGTAC CTGGCCATCGTCCTGGCCGCCAACTCCATGAACAACCGGACCGTGCAGCATGGCGTCACC ATCAGCCTAGGCGTCTGGGCAGCAGCCATTTTGGTGGCAGCACCCCAGTTCATGTTCACA AAGCAGAAAGAAAATGAATGCCTTGGTGACTACCCCGAGGTCCTCCAGGAAATCTGGCCC GTGCTCCGCAATGTGGAAACAAATTTTCTTGGCTTCCTACTCCCCCTGCTCATTATGAGT TATTGCTACTTCAGAATCATCCAGACGCTGTTTTCCTGCAAGAACCACAAGAAAGCCAAA GCCATTAAACTGATCCTTCTGGTGGTCATCGTGTTTTTCCTCTTCTGGACACCCTACAAC ATTATGATTTTCCTGGAGACGCTTAAGCTCTATGACTTCTTTCCCAGTTGTGACATGAGG AAGGATCTGAGGCTGGCCCTCAGTGTGACTGAGATGGTTGCATTTAGCCATTGTTGCCTG AATCCTCTCATCTATGCATTTGCTGGGGAGAAGTTCAGAAGATACCTTTACCACCTGTAT GGGAAATGCCTGGCTGTCCTGTGTGGGCGCTCAGTCCACGTTGATTTCTCCTCATCTGAA TCACAAAGGAGCAGGCATGGAAGTGTTCTGAGCAGCAATTTTACTTACCACACGAGTGAT GGAGATGCATTGCTCCTTCTC
Cloned ORF protein sequence for pF1KB8986 Download>KIBB8986 387 aa MREPLEALKLADLDFRKSSLASGWRMASGAFTMDQFPESVTENFEYDDLAEACYIGDIVV FGTVFLSIFYSVIFAIGLVGNLLVVFALTNSKKPKSVTDIYLLNLALSDLLFVATLPFWT HYLINEKGLHNAMCKFTTAFFFIGFFGSIFFITVISIDRYLAIVLAANSMNNRTVQHGVT ISLGVWAAAILVAAPQFMFTKQKENECLGDYPEVLQEIWPVLRNVETNFLGFLLPLLIMS YCYFRIIQTLFSCKNHKKAKAIKLILLVVIVFFLFWTPYNIMIFLETLKLYDFFPSCDMR KDLRLALSVTEMVAFSHCCLNPLIYAFAGEKFRRYLYHLYGKCLAVLCGRSVHVDFSSSE SQRSRHGSVLSSNFTYHTSDGDALLLL
Nucleotide Sequence (with vector) for pF1KB8986 Download>pF1KB8986 4274 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGAGAGAACCC CTGGAGGCGTTGAAGTTGGCAGACTTGGATTTCAGGAAGAGCTCTCTGGCTTCTGGGTGG AGAATGGCCAGTGGGGCCTTCACCATGGATCAGTTCCCTGAATCAGTGACAGAAAACTTT GAGTACGATGATTTGGCTGAGGCCTGTTATATTGGGGACATCGTGGTCTTTGGGACTGTG TTCCTGTCCATATTCTACTCCGTCATCTTTGCCATTGGCCTGGTGGGAAATTTGTTGGTA GTGTTTGCCCTCACCAACAGCAAGAAGCCCAAGAGTGTCACCGACATTTACCTCCTGAAC CTGGCCTTGTCTGATCTGCTGTTTGTAGCCACTTTGCCCTTCTGGACTCACTATTTGATA AATGAAAAGGGCCTCCACAATGCCATGTGCAAATTCACTACCGCCTTCTTCTTCATCGGC TTTTTTGGAAGCATATTCTTCATCACCGTCATCAGCATTGATAGGTACCTGGCCATCGTC CTGGCCGCCAACTCCATGAACAACCGGACCGTGCAGCATGGCGTCACCATCAGCCTAGGC GTCTGGGCAGCAGCCATTTTGGTGGCAGCACCCCAGTTCATGTTCACAAAGCAGAAAGAA AATGAATGCCTTGGTGACTACCCCGAGGTCCTCCAGGAAATCTGGCCCGTGCTCCGCAAT GTGGAAACAAATTTTCTTGGCTTCCTACTCCCCCTGCTCATTATGAGTTATTGCTACTTC AGAATCATCCAGACGCTGTTTTCCTGCAAGAACCACAAGAAAGCCAAAGCCATTAAACTG ATCCTTCTGGTGGTCATCGTGTTTTTCCTCTTCTGGACACCCTACAACATTATGATTTTC CTGGAGACGCTTAAGCTCTATGACTTCTTTCCCAGTTGTGACATGAGGAAGGATCTGAGG CTGGCCCTCAGTGTGACTGAGATGGTTGCATTTAGCCATTGTTGCCTGAATCCTCTCATC TATGCATTTGCTGGGGAGAAGTTCAGAAGATACCTTTACCACCTGTATGGGAAATGCCTG GCTGTCCTGTGTGGGCGCTCAGTCCACGTTGATTTCTCCTCATCTGAATCACAAAGGAGC AGGCATGGAAGTGTTCTGAGCAGCAATTTTACTTACCACACGAGTGATGGAGATGCATTG CTCCTTCTCGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGC AGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGC CACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTT TTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAG CTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCT TGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGC TTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGA GCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTA AACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAA GAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCG GCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCT GATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGAC CTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACG ACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTG CTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAA GTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCA TTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTT GTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCC AGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGC TTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTG GGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTT GGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAG CGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAA TGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATC CACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAG GAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCA TCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCA GGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGG ATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAG GTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGT TCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACA CGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGG CGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATT TGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATC CGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCG CAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTG GAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTA GATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGT GAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTC TGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGG GTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGG TGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGA TAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCT GATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAG TAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGA TGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAA AGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCC TGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGT GGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGA CGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAAT ATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}