Nucleotide Sequence (with vector) for pF1KE1035
Download
>pF1KE1035 4397 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGCAGAGAAC
GATGTGGACAATGAGCTCTTGGACTATGAAGATGATGAGGTGGAGACAGCAGCTGGGGGA
GATGGGGCTGAGGCCCCTGCCAAGAAGGATGTCAAGGGCTCCTATGTCTCCATCCACAGC
TCTGGCTTTCGTGACTTCCTGCTCAAGCCAGAGTTGCTCCGGGCCATTGTCGACTGTGGC
TTTGAGCATCCGTCAGAAGTCCAGCATGAGTGCATCCCTCAGGCCATTCTGGGAATGGAT
GTCCTGTGCCAGGCCAAGTCGGGCATGGGAAAGACAGCAGTGTTTGTCTTGGCCACACTG
CAACAGCTGGAGCCAGTTACTGGGCAGGTGTCTGTGCTGGTGATGTGTCACACTCGGGAG
TTGGCTTTTCAGATCAGCAAGGAATATGAGCGCTTCTCTAAATACATGCCCAATGTCAAG
GTTGCTGTTTTTTTTGGTGGTCTGTCTATCAAGAAGGATGAAGAGGTGCTGAAGAAGAAC
TGCCCGCATATCGTCGTGGGGACTCCAGGCCGTATCCTAGCCCTGGCTCGAAATAAGAGC
CTCAACCTCAAACACATTAAACACTTTATTTTGGATGAATGTGATAAGATGCTTGAACAG
CTCGACATGCGTCGGGATGTCCAGGAAATTTTTCGCATGACCCCCCACGAGAAGCAGGTC
ATGATGTTCAGTGCTACCTTGAGCAAAGAGATCCGTCCAGTCTGCCGCAAGTTCATGCAA
GATCCAATGGAGATCTTCGTGGATGATGAGACGAAGTTGACGCTGCATGGGTTGCAGCAG
TACTACGTGAAACTGAAGGACAACGAGAAGAACCGGAAGCTCTTTGACCTTCTGGATGTC
CTTGAGTTCAACCAGGTGGTGATCTTTGTGAAGTCTGTGCAGCGGTGCATTGCCTTGGCC
CAGCTACTAGTGGAGCAGAACTTCCCAGCCATTGCCATCCACCGTGGGATGCCCCAGGAG
GAGAGGCTTTCTCGGTATCAGCAGTTTAAAGATTTTCAACGACGAATTCTTGTGGCTACC
AACCTATTTGGCCGAGGCATGGACATCGAGCGGGTGAACATTGCTTTTAATTATGACATG
CCTGAGGATTCTGACACCTACCTGCATCGGGTGGCCAGAGCAGGCCGGTTTGGCACCAAG
GGCTTGGCTATCACATTTGTGTCCGATGAGAATGATGCCAAGATCCTCAATGATGTGCAG
GATCGCTTTGAGGTCAATATTAGTGAGCTGCCTGATGAGATAGACATCTCCTCCTACATT
GAACAGACACGGGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACC
TGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGC
TGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGG
TTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTC
TAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTC
CCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACT
GGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCG
TGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAA
GTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGAT
CAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCT
CCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGC
TCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACC
GACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCC
ACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGG
CTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAG
AAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGC
CCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGT
CTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTC
GCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCC
TGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGG
CTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAG
CTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCG
CAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCG
AAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTT
ATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGC
CAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGA
GCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATA
CCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTAC
CGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTG
TAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCC
CGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAG
ACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGT
AGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGT
ATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTG
ATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTAC
GCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCA
GTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCAC
CTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGAT
GGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACC
CTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTT
CGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAG
CGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCG
AGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAG
CCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGG
CAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGC
CGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAAC
GAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTC
TCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAG
GGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCC
TGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCA
AATATGTATCCGCTCAT



 Length: 1284 bp
Length: 1284 bp Restriction map B
Restriction map B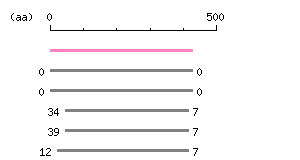

 more Linker info
more Linker info
{kind=link}