Nucleotide Sequence (with vector) for pF1KA0911
Download
>pF1KA0911 6056 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGCTGCGCCGC
CCCGCTCCCGCGCTGGCCCCGGCCGCCCGGCTGCTGCTGGCCGGGCTGCTGTGCGGCGGC
GGGGTCTGGGCCGCGCGAGTTAACAAGCACAAGCCCTGGCTGGAGCCCACCTACCACGGC
ATAGTCACAGAGAACGACAACACCGTGCTCCTCGACCCCCCACTGATCGCGCTGGATAAA
GATGCGCCTCTGCGATTTGCAGAGAGTTTTGAGGTGACAGTCACCAAAGAAGGTGAGATT
TGTGGATTTAAAATTCACGGGCAGAATGTCCCCTTTGATGCAGTGGTAGTGGATAAATCC
ACTGGTGAGGGAGTCATTCGCTCCAAAGAGAAACTGGACTGTGAGCTGCAGAAAGACTAT
TCATTCACCATCCAGGCCTATGATTGTGGGAAGGGACCTGATGGCACCAACGTGAAAAAG
TCTCATAAAGCAACTGTTCATATTCAGGTGAACGACGTGAATGAGTACGCGCCCGTGTTC
AAGGAGAAGTCCTACAAAGCCACGGTCATCGAGGGGAAGCAGTACGACAGCATTTTGAGG
GTGGAGGCCGTGGATGCCGACTGCTCCCCTCAGTTCAGCCAGATTTGCAGCTACGAAATC
ATCACTCCAGACGTGCCCTTTACTGTTGACAAAGATGGTTATATAAAAAACACAGAGAAA
TTAAACTACGGGAAAGAACATCAATATAAGCTGACCGTCACTGCCTATGACTGTGGGAAG
AAAAGAGCCACAGAAGATGTTTTGGTGAAGATCAGCATTAAGCCCACCTGCACCCCTGGG
TGGCAAGGATGGAACAACAGGATTGAGTATGAGCCGGGCACCGGCGCGTTGGCCGTCTTT
CCAAATATCCACCTGGAGACATGTGACGAGCCAGTCGCCTCAGTACAGGCCACAGTGGAG
CTAGAAACCAGCCACATAGGGAAAGGCTGCGACCGAGACACCTACTCAGAGAAGTCCCTC
CACCGGCTCTGTGGTGCGGCCGCGGGCACTGCCGAGCTGCTGCCATCCCCGAGTGGATCC
CTCAACTGGACCATGGGCCTGCCCACCGACAATGGCCACGACAGCGACCAGGTGTTTGAG
TTCAACGGCACCCAGGCAGTGAGGATCCCGGATGGCGTCGTGTCGGTCAGCCCCAAAGAG
CCGTTCACCATCTCGGTGTGGATGAGACATGGGCCATTCGGCAGGAAGAAGGAGACAATT
CTTTGCAGTTCTGATAAAACAGATATGAATCGGCACCACTACTCCCTCTATGTCCACGGG
TGCCGGCTGATCTTCCTCTTCCGTCAGGATCCTTCTGAGGAGAAGAAATACAGACCTGCA
GAGTTCCACTGGAAGTTGAATCAGGTCTGTGATGAGGAATGGCACCACTACGTCCTCAAT
GTAGAATTCCCGAGTGTGACTCTCTATGTGGATGGCACGTCCCACGAGCCCTTCTCTGTG
ACTGAGGATTACCCGCTCCATCCATCCAAGATAGAAACTCAGCTCGTGGTGGGGGCTTGC
TGGCAAGAGTTTTCAGGAGTTGAAAATGACAATGAAACTGAGCCTGTGACTGTGGCCTCT
GCAGGTGGCGACCTGCACATGACCCAGTTTTTCCGAGGCAATCTGGCTGGCTTAACTCTC
CGTTCCGGGAAACTCGCGGATAAGAAGGTGATCGACTGTCTGTATACCTGCAAGGAGGGG
CTGGACCTGCAGGTCCTCGAAGACAGTGGCAGAGGCGTGCAGATCCAAGCACACCCCAGC
CAGTTGGTATTGACCTTGGAGGGAGAAGACCTCGGGGAATTGGATAAGGCCATGCAGCAC
ATCTCGTACCTGAACTCCCGGCAGTTCCCCACGCCCGGAATTCGCAGACTCAAAATCACC
AGCACAATCAAGTGTTTTAACGAGGCCACCTGCATTTCGGTCCCCCCGGTAGATGGCTAC
GTGATGGTTTTACAGCCCGAGGAGCCCAAGATCAGCCTGAGTGGCGTCCACCATTTTGCC
CGAGCAGCTTCTGAATTTGAAAGCTCAGAAGGGGTGTTCCTTTTCCCTGAGCTTCGCATC
ATCAGCACCATCACGAGAGAAGTGGAGCCTGAAGGGGACGGGGCTGAGGACCCCACAGTT
CAAGAATCACTGGTGTCCGAGGAGATCGTGCACGACCTGGATACCTGTGAGGTCACGGTG
GAGGGAGAGGAGCTGAACCACGAGCAGGAGAGCCTGGAGGTGGACATGGCCCGCCTGCAG
CAGAAGGGCATTGAAGTGAGCAGCTCTGAACTGGGCATGACCTTCACAGGCGTGGACACC
ATGGCCAGCTACGAGGAGGTTTTGCACCTGCTGCGCTATCGGAACTGGCATGCCAGGTCC
TTGCTTGACCGGAAGTTTAAGCTCATCTGCTCAGAGCTGAATGGCCGCTACATCAGCAAC
GAATTTAAGGTGGAGGTGAATGTAATCCACACGGCCAACCCCATGGAACACGCCAACCAC
ATGGCTGCCCAGCCACAGTTCGTGCACCCGGAACACCGCTCCTTTGTTGACCTGTCAGGC
CACAACCTGGCCAACCCCCACCCGTTCGCAGTCGTCCCCAGCACTGCGACAGTTGTGATC
GTGGTGTGCGTCAGCTTCCTGGTGTTCATGATTATCCTGGGGGTATTTCGGATCCGGGCC
GCACATCGGCGGACCATGCGGGATCAGGACACCGGGAAGGAGAACGAGATGGACTGGGAC
GACTCTGCCCTGACCATCACCGTCAACCCCATGGAGACCTATGAGGACCAGCACAGCAGT
GAGGAGGAGGAGGAAGAGGAAGAGGAAGAGGAAAGCGAGGACGGCGAAGAAGAGGATGAC
ATCACCAGCGCCGAGTCGGAGAGCAGCGAGGAGGAGGAGGGGGAGCAGGGCGACCCCCAG
AACGCAACCCGGCAGCAGCAGCTGGAGTGGGATGACTCCACCCTCAGCTACGTTTAAACG
AATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCC
GGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACT
AGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAAC
TATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCC
ACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTA
GCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTT
CCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCA
GCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTG
CCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCG
TTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGG
CTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGG
CTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAAT
GAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCA
GCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCG
GGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGAT
GCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAA
CATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTG
GACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATG
CCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTG
GAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTAT
CAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGAC
CGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGC
CTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGC
CCAACCGGACTATAAAAGGATCTAGGTGAAGATCCTTTTTGATAATCTCATGACCAAAAT
CCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATC
TTCTTGAAATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCT
ACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGG
CTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCA
CTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGC
TGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGA
TAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAAC
GACCTACACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGA
AGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAG
GGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTG
ACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAG
CAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATGTTCTTTCC
TGCGTTATCCCCTGATTCTGTGGATAACCGTATTACCGCCTTTGAGTGAGCTGATACCGG
AAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGC
AGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCA
TACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTT
TACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGAT
TATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGG
CCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGA
ACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACC
TGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCC
CCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACT
GGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGC
CGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGC
CATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGT
TTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 2943 bp
Length: 2943 bp Restriction map B
Restriction map B
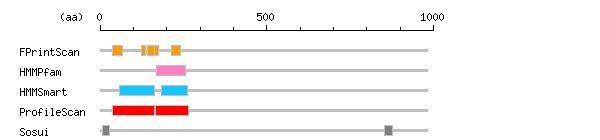
 more Linker info
more Linker info
{kind=link}