Nucleotide Sequence (with vector) for pF1KE0433
Download
>pF1KE0433 4355 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGTCCAAAAAA
ATCAGTGGCGGTTCTGTGGTAGAGATGCAAGGAGATGAAATGACACGAATCATTTGGGAA
TTGATTAAAGAGAAACTCATTATTCCCTACGTGGAATTGGATCTACATAGCTATGATTTA
GGCATAGAGAATCGTGATGCCACCAACGACCAAGTCACCAAGGATGCTGCAGAAGCTATA
AAGAAGCATAATGTTGGCGTCAAATGTGCCACTATCACTCCTGATGAGAAGAGGGTTGAG
GAGTTCAAGTTGAAACAAATGTGGAAATCACCAAATGGCACCATACGAAATATTCTGGGT
GGCACGGTCTTCAGAGAAGCCATTATCTGCAAAAATATCCCCCGGCTTGTGAGTGGATGG
GTAGAACCTATCATCATAGGTCGTCATGCTTATGGGGATCAATACAGAGCAACTGATTTT
GTTGTTCCTGGGCCTGGAAAAGTAGAGATAACCTACACACCAAGTGACGGAACCCAAAAG
GTGACATACCTGGTACATAACTTTGAAGAAGGTGGTGGTGTTGCCATGGGGATGTATAAT
CAAGATAAGTCAATTGAAGATTTTGCACACAGTTCCTTCCAAATGGCTCTGTCTAAGGGT
TGGCCTTTGTATCTGAGCACCAAAAACACTATTCTGAAGAAATATGATGGGCGTTTTAAA
GACATCTTTCAGGAGATATATGACAAGCAGTACAAGTCCCAGTTTGAAGCTCAAAAGATC
TGGTATGAGCATAGGCTCATCGACGACATGGTGGCCCAAGCTATGAAATCAGAGGGAGGC
TTCATCTGGGCCTGTAAAAACTATGATGGTGACGTGCAGTCGGACTCTGTGGCCCAAGGG
TATGGCTCTCTCGGCATGATGACCAGCGTGCTGGTTTGTCCAGATGGCAAGACAGTAGAA
GCAGAGGCTGCCCACGGGACTGTAACCCGTCACTACCGCATGTACCAGAAAGGACAGGAG
ACGTCCACCAATCCCATTGCTTCCATTTTTGCCTGGACCAGAGGGTTAGCCCACAGAGCA
AAGCTTGATAACAATAAAGAGCTTGCCTTCTTTGCAAATGCTTTGGAAGAAGTCTCTATT
GAGACAATTGAGGCTGGCTTCATGACCAAGGACTTGGCTGCTTGCATTAAAGGTTTACCC
AATGTGCAACGTTCTGACTACTTGAATACATTTGAGTTCATGGATAAACTTGGAGAAAAC
TTGAAGATCAAACTAGCTCAGGCCAAACTTGTTTAAACGAATTCGAGCTCGGTACCCGGG
GATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAA
GGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTC
TAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGT
CCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCT
CTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCA
GCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCC
TGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAG
GTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGC
AGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGAT
GGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCA
CAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCG
GTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCG
CGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACT
GAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCT
CACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACG
CTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGC
ACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTC
GCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTC
GTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGA
TTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACC
CGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGT
ATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGA
GCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTC
AAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGC
AAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAG
GCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCC
GACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGT
TCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCT
TTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGG
CTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCT
TGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGAT
TAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGG
CTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAA
AAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGT
TTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTC
TACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATT
ATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGG
ATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGG
GGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGC
GCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATC
GCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGT
CTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGA
GGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAA
ACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGA
AGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTG
CCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTT
GTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTG
CGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAA
TTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTA
TTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 1242 bp
Length: 1242 bp Restriction map B
Restriction map B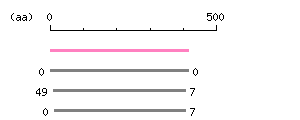

 more Linker info
more Linker info
{kind=link}