Nucleotide Sequence (with vector) for pF1KE0932
Download
>pF1KE0932 4346 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGAAAGGATG
AGTGACTCTGCAGATAAGCCAATTGACAATGATGCAGAAGGGGTCTGGAGCCCCGACATC
GAGCAAAGCTTTCAGGAGGCCCTGGCTATCTATCCACCATGTGGGAGGAGGAAAATCATC
TTATCAGACGAAGGCAAAATGTATGGTAGGAATGAATTGATAGCCAGATACATCAAACTC
AGGACAGGCAAGACGAGGACCAGAAAACAGGTGTCTAGTCACATTCAGGTTCTTGCCAGA
AGGAAATCTCGTGATTTTCATTCCAAGCTAAAGGATCAGACTGCAAAGGATAAGGCCCTG
CAGCACATGGCGGCCATGTCCTCAGCCCAGATCGTCTCGGCCACTGCCATTCATAACAAG
CTGGGGCTGCCTGGGATTCCACGCCCGACCTTCCCAGGGGCGCCGGGGTTCTGGCCGGGA
ATGATTCAAACAGGGCAGCCAGGATCCTCACAAGATGTCAAGCCTTTTGTGCAGCAGGCC
TACCCCATCCAGCCAGCGGTCACAGCCCCCATTCCAGGGTTTGAGCCTGCATCGGCCCCA
GCTCCCTCAGTCCCTGCCTGGCAAGGTCGCTCCATTGGCACAACCAAGCTTCGCCTGGTG
GAATTTTCAGCTTTTCTCGAGCAGCAGCGAGACCCAGACTCGTACAACAAACACCTCTTC
GTGCACATTGGGCATGCCAACCATTCTTACAGTGACCCATTGCTTGAATCAGTGGACATT
CGTCAGATTTATGACAAATTTCCTGAAAAGAAAGGTGGCTTAAAGGAACTGTTTGGAAAG
GGCCCTCAAAATGCCTTCTTCCTCGTAAAATTCTGGGCTGATTTAAACTGCAATATTCAA
GATGATGCTGGGGCTTTTTATGGTGTAACCAGTCAGTACGAGAGTTCTGAAAATATGACA
GTCACCTGTTCCACCAAAGTTTGCTCCTTTGGGAAGCAAGTAGTAGAAAAAGTAGAGACG
GAGTATGCAAGGTTTGAGAATGGCCGATTTGTATACCGAATAAACCGCTCCCCAATGTGT
GAATATATGATCAACTTCATCCACAAGCTCAAACACTTACCAGAGAAATATATGATGAAC
AGTGTTTTGGAAAACTTCACAATTTTATTGGTGGTAACAAACAGGGATACACAAGAAACT
CTACTCTGCATGGCCTGTGTGTTTGAAGTTTCAAATAGTGAACACGGAGCACAACATCAT
ATTTACAGGCTTGTAAAGGACGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTA
GAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGA
GTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGT
CTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAAC
CGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCT
TGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTT
CTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTT
GCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAG
CCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCA
AGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCAC
GCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACA
ATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTT
GTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCG
TGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGA
AGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCT
CCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCG
GCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATG
GAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCC
GAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCAT
GGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGAC
TGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATT
GCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCT
CCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTC
TGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGT
AATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCA
GCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCC
CCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACT
ATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCT
GCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAG
CTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCA
CGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAA
CCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGC
GAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAG
AAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGG
TAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCA
GCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTC
TGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAG
GATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTT
CGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTG
GCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCG
GCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAAC
GCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCG
TAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGA
TCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTT
GCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACG
CCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATC
AAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGG
TGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAAC
GGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGA
AGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAA
ATACATTCAAATATGTATCCGCTCAT



 Length: 1233 bp
Length: 1233 bp Restriction map B
Restriction map B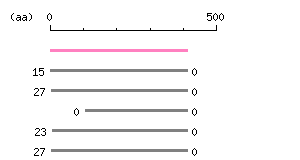
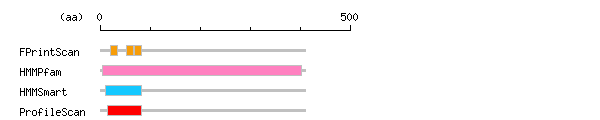
 more Linker info
more Linker info
{kind=link}