


-
SpecieshumanProduct IDFXC11613Cloning SiteSgfI-PmeIGeneKIBB3158SymbolPCDH20
Alias : PCDH13Descriptionprotocadherin 20Original Clone IDfj12189 Length: 2772 bp
Length: 2772 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 924 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
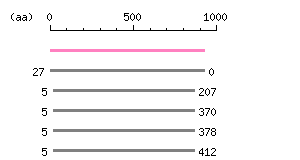
Entry Exp ID% symbol CCDS9442.2 0 100.0 PCDH20 CCDS81769.1 9.1e-128 43.3 PCDH9 CCDS81770.1 1e-127 43.3 PCDH9 CCDS9443.1 1e-127 43.3 PCDH9 CCDS9444.1 1.1e-127 43.3 PCDH9
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR002126 342 361 PR00205 Cadherin IPR002126 508 537 PR00205 Cadherin IPR002126 577 589 PR00205 Cadherin IPR002126 591 610 PR00205 Cadherin IPR002126 610 623 PR00205 Cadherin IPR002126 663 689 PR00205 Cadherin IPR002126 697 714 PR00205 Cadherin HMMPfam IPR002126 189 283 PF00028 Cadherin IPR002126 299 374 PF00028 Cadherin IPR002126 515 603 PF00028 Cadherin IPR002126 617 705 PF00028 Cadherin IPR002126 730 816 PF00028 Cadherin HMMSmart IPR002126 205 291 SM00112 Cadherin IPR002126 315 397 SM00112 Cadherin IPR002126 427 506 SM00112 Cadherin IPR002126 530 610 SM00112 Cadherin IPR002126 634 713 SM00112 Cadherin IPR002126 740 824 SM00112 Cadherin ProfileScan IPR002126 37 182 PS50268 Cadherin IPR002126 183 293 PS50268 Cadherin IPR002126 294 508 PS50268 Cadherin IPR002126 509 612 PS50268 Cadherin IPR002126 613 715 PS50268 Cadherin IPR002126 719 836 PS50268 Cadherin
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 14 RNLPHLFLFFLFVGPFSCLGSYS 36 SECONDARY 23 2 861 PTLVALSVISLGSITLVTGMGIY 883 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_073754 951 614449 100.0 100.0 XP_016876197 951 614449 100.0 100.0 XP_005266465 1019 603581 43.3 91.8 XP_016876110 1019 603581 43.3 91.8 NP_001305303 1032 603581 43.3 91.8 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KB3158 Download>KIBB3158 2772 bp ATGGGGCGTCTACATCGTCCCAGGAGCAGCACCAGCTACAGGAACCTGCCGCATCTGTTT CTGTTTTTCCTCTTCGTGGGACCCTTCAGCTGCCTCGGGAGTTACAGCCGGGCCACCGAG CTTCTGTACAGCCTAAACGAGGGACTACCCGCGGGGGTGCTCATCGGCAGCCTGGCCGAG GACCTGCGGCTGCTGCCCAGGTCTGCAGGGAGGCCGGACCCGCAGTCGCAGCTGCCAGAG CGCACCGGTGCTGAGTGGAACCCCCCTCTCTCCTTCAGCCTGGCCTCCCGGGGACTGAGT GGCCAGTACGTGACCCTAGACAACCGCTCTGGGGAGCTGCACACTTCAGCTCAGGAGATC GACAGGGAGGCCCTGTGTGTTGAAGGGGGTGGAGGGACTGCGTGGAGCGGCAGCGTTTCC ATCTCCTCCTCTCCTTCTGACTCTTGTCTTTTGCTGCTGGATGTGCTTGTCCTGCCTCAG GAATACTTCAGGTTTGTGAAGGTGAAGATCGCCATCAGAGACATCAATGACAACGCCCCG CAGTTCCCTGTTTCCCAGATCTCGGTGTGGGTCCCGGAAAATGCACCTGTAAACACCCGA CTGGCCATAGAGCATCCTGCTGTGGACCCAGATGTAGGCATTAATGGGGTACAGACCTAT CGCTTACTGGACTACCATGGTATGTTCACCCTGGACGTGGAGGAGAATGAGAATGGGGAG CGCACCCCCTACCTAATTGTCATGGGTGCTTTGGACAGGGAAACCCAGGACCAGTATGTG AGCATCATCATAGCTGAGGATGGTGGGTCTCCACCACTTTTGGGCAGTGCCACTCTCACC ATTGGCATCAGTGACATTAATGACAATTGCCCTCTCTTCACAGACTCACAAATCAATGTC ACTGTGTATGGGAATGCTACAGTGGGCACCCCAATTGCAGCTGTCCAGGCTGTGGATAAA GACTTGGGGACCAATGCTCAAATTACTTATTCTTACAGTCAGAAAGTTCCACAAGCATCT AAGGATTTATTTCACCTGGATGAAAACACTGGAGTCATTAAACTTTTCAGTAAGATTGGA GGAAGTGTTCTGGAGTCCCACAAGCTCACCATCCTTGCTAATGGACCAGGCTGCATCCCT GCTGTAATCACTGCTCTTGTGTCCATTATTAAAGTTATTTTCAGACCCCCTGAAATTGTC CCTCGTTACATAGCAAACGAGATAGATGGTGTTGTTTATCTGAAAGAACTGGAACCCGTT AACACTCCCATTGCGTTTTTCACCATAAGAGATCCAGAAGGTAAATACAAGGTTAACTGC TACCTGGATGGTGAAGGGCCGTTTAGGTTATCACCTTACAAACCATACAATAATGAATAT TTACTAGAGACCACAAAACCTATGGACTATGAGCTACAGCAGTTCTATGAAGTAGCTGTG GTGGCTTGGAACTCTGAGGGATTTCATGTCAAAAGGGTCATTAAAGTGCAACTTTTAGAT GACAATGATAATGCTCCAATTTTCCTTCAACCCTTAATAGAACTAACCATCGAAGAGAAC AACTCACCCAATGCCTTTTTGACTAAGCTGTATGCTACAGATGCCGACAGCGAGGAGAGA GGCCAAGTTTCATATTTTCTGGGACCTGATGCTCCATCATATTTTTCCTTAGACAGTGTC ACAGGAATTCTGACAGTTTCTACTCAGCTGGACCGAGAAGAGAAAGAAAAGTACAGATAC ACTGTCAGAGCTGTTGACTGTGGGAAGCCACCCAGAGAATCAGTAGCCACTGTGGCCCTC ACAGTGTTGGATAAAAATGACAACAGTCCTCGGTTTATCAACAAGGACTTCAGCTTTTTT GTGCCTGAAAACTTTCCAGGCTATGGTGAGATTGGAGTAATTAGTGTAACAGATGCTGAC GCTGGACGAAATGGATGGGTCGCCCTCTCTGTGGTGAACCAGAGTGATATTTTTGTCATA GATACAGGAAAGGGTATGCTGAGGGCTAAAGTCTCTTTGGACAGAGAGCAGCAAAGCTCC TATACTTTGTGGGTTGAAGCTGTTGATGGGGGTGAGCCTGCCCTCTCCTCTACAGCAAAA ATCACAATTCTCCTTCTAGATATCAATGACAACCCTCCTCTTGTTTTGTTTCCTCAGTCT AATATGTCTTATCTGTTAGTACTGCCTTCTACTCTGCCAGGCTCCCCGGTTACAGAAGTC TATGCTGTCGACAAAGACACAGGCATGAATGCTGTCATAGCTTACAGCATCATAGGGAGA AGAGGTCCTAGGCCTGAGTCCTTCAGGATTGACCCTAAAACTGGCAACATTACTTTGGAA GAGGCATTGCTGCAGACAGATTATGGGCTCCATCGCTTACTGGTGAAAGTGAGTGATCAT GGTTATCCCGAGCCTCTCCACTCCACAGTCATGGTGAACCTATTTGTCAATGACACTGTC AGTAATGAGAGTTACATTGAGAGTCTTTTAAGAAAAGAACCAGAGATTAATATAGAGGAG AAAGAACCACAAATCTCAATAGAACCGACTCATAGGAAGGTAGAATCTGTGTCTTGTATG CCCACCTTAGTAGCTCTGTCTGTAATAAGCTTGGGTTCCATCACACTGGTCACAGGGATG GGCATATACATCTGTTTAAGGAAAGGGGAAAAGCATCCCAGGGAAGATGAAAATTTGGAA GTACAGATTCCACTGAAAGGAAAAATTGACTTGCATATGCGAGAGAGAAAGCCAATGGAT ATTTCTAATATT
Cloned ORF protein sequence for pF1KB3158 Download>KIBB3158 924 aa MGRLHRPRSSTSYRNLPHLFLFFLFVGPFSCLGSYSRATELLYSLNEGLPAGVLIGSLAE DLRLLPRSAGRPDPQSQLPERTGAEWNPPLSFSLASRGLSGQYVTLDNRSGELHTSAQEI DREALCVEGGGGTAWSGSVSISSSPSDSCLLLLDVLVLPQEYFRFVKVKIAIRDINDNAP QFPVSQISVWVPENAPVNTRLAIEHPAVDPDVGINGVQTYRLLDYHGMFTLDVEENENGE RTPYLIVMGALDRETQDQYVSIIIAEDGGSPPLLGSATLTIGISDINDNCPLFTDSQINV TVYGNATVGTPIAAVQAVDKDLGTNAQITYSYSQKVPQASKDLFHLDENTGVIKLFSKIG GSVLESHKLTILANGPGCIPAVITALVSIIKVIFRPPEIVPRYIANEIDGVVYLKELEPV NTPIAFFTIRDPEGKYKVNCYLDGEGPFRLSPYKPYNNEYLLETTKPMDYELQQFYEVAV VAWNSEGFHVKRVIKVQLLDDNDNAPIFLQPLIELTIEENNSPNAFLTKLYATDADSEER GQVSYFLGPDAPSYFSLDSVTGILTVSTQLDREEKEKYRYTVRAVDCGKPPRESVATVAL TVLDKNDNSPRFINKDFSFFVPENFPGYGEIGVISVTDADAGRNGWVALSVVNQSDIFVI DTGKGMLRAKVSLDREQQSSYTLWVEAVDGGEPALSSTAKITILLLDINDNPPLVLFPQS NMSYLLVLPSTLPGSPVTEVYAVDKDTGMNAVIAYSIIGRRGPRPESFRIDPKTGNITLE EALLQTDYGLHRLLVKVSDHGYPEPLHSTVMVNLFVNDTVSNESYIESLLRKEPEINIEE KEPQISIEPTHRKVESVSCMPTLVALSVISLGSITLVTGMGIYICLRKGEKHPREDENLE VQIPLKGKIDLHMRERKPMDISNI
Nucleotide Sequence (with vector) for pF1KB3158 Download>pF1KB3158 5885 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGGGCGTCTA CATCGTCCCAGGAGCAGCACCAGCTACAGGAACCTGCCGCATCTGTTTCTGTTTTTCCTC TTCGTGGGACCCTTCAGCTGCCTCGGGAGTTACAGCCGGGCCACCGAGCTTCTGTACAGC CTAAACGAGGGACTACCCGCGGGGGTGCTCATCGGCAGCCTGGCCGAGGACCTGCGGCTG CTGCCCAGGTCTGCAGGGAGGCCGGACCCGCAGTCGCAGCTGCCAGAGCGCACCGGTGCT GAGTGGAACCCCCCTCTCTCCTTCAGCCTGGCCTCCCGGGGACTGAGTGGCCAGTACGTG ACCCTAGACAACCGCTCTGGGGAGCTGCACACTTCAGCTCAGGAGATCGACAGGGAGGCC CTGTGTGTTGAAGGGGGTGGAGGGACTGCGTGGAGCGGCAGCGTTTCCATCTCCTCCTCT CCTTCTGACTCTTGTCTTTTGCTGCTGGATGTGCTTGTCCTGCCTCAGGAATACTTCAGG TTTGTGAAGGTGAAGATCGCCATCAGAGACATCAATGACAACGCCCCGCAGTTCCCTGTT TCCCAGATCTCGGTGTGGGTCCCGGAAAATGCACCTGTAAACACCCGACTGGCCATAGAG CATCCTGCTGTGGACCCAGATGTAGGCATTAATGGGGTACAGACCTATCGCTTACTGGAC TACCATGGTATGTTCACCCTGGACGTGGAGGAGAATGAGAATGGGGAGCGCACCCCCTAC CTAATTGTCATGGGTGCTTTGGACAGGGAAACCCAGGACCAGTATGTGAGCATCATCATA GCTGAGGATGGTGGGTCTCCACCACTTTTGGGCAGTGCCACTCTCACCATTGGCATCAGT GACATTAATGACAATTGCCCTCTCTTCACAGACTCACAAATCAATGTCACTGTGTATGGG AATGCTACAGTGGGCACCCCAATTGCAGCTGTCCAGGCTGTGGATAAAGACTTGGGGACC AATGCTCAAATTACTTATTCTTACAGTCAGAAAGTTCCACAAGCATCTAAGGATTTATTT CACCTGGATGAAAACACTGGAGTCATTAAACTTTTCAGTAAGATTGGAGGAAGTGTTCTG GAGTCCCACAAGCTCACCATCCTTGCTAATGGACCAGGCTGCATCCCTGCTGTAATCACT GCTCTTGTGTCCATTATTAAAGTTATTTTCAGACCCCCTGAAATTGTCCCTCGTTACATA GCAAACGAGATAGATGGTGTTGTTTATCTGAAAGAACTGGAACCCGTTAACACTCCCATT GCGTTTTTCACCATAAGAGATCCAGAAGGTAAATACAAGGTTAACTGCTACCTGGATGGT GAAGGGCCGTTTAGGTTATCACCTTACAAACCATACAATAATGAATATTTACTAGAGACC ACAAAACCTATGGACTATGAGCTACAGCAGTTCTATGAAGTAGCTGTGGTGGCTTGGAAC TCTGAGGGATTTCATGTCAAAAGGGTCATTAAAGTGCAACTTTTAGATGACAATGATAAT GCTCCAATTTTCCTTCAACCCTTAATAGAACTAACCATCGAAGAGAACAACTCACCCAAT GCCTTTTTGACTAAGCTGTATGCTACAGATGCCGACAGCGAGGAGAGAGGCCAAGTTTCA TATTTTCTGGGACCTGATGCTCCATCATATTTTTCCTTAGACAGTGTCACAGGAATTCTG ACAGTTTCTACTCAGCTGGACCGAGAAGAGAAAGAAAAGTACAGATACACTGTCAGAGCT GTTGACTGTGGGAAGCCACCCAGAGAATCAGTAGCCACTGTGGCCCTCACAGTGTTGGAT AAAAATGACAACAGTCCTCGGTTTATCAACAAGGACTTCAGCTTTTTTGTGCCTGAAAAC TTTCCAGGCTATGGTGAGATTGGAGTAATTAGTGTAACAGATGCTGACGCTGGACGAAAT GGATGGGTCGCCCTCTCTGTGGTGAACCAGAGTGATATTTTTGTCATAGATACAGGAAAG GGTATGCTGAGGGCTAAAGTCTCTTTGGACAGAGAGCAGCAAAGCTCCTATACTTTGTGG GTTGAAGCTGTTGATGGGGGTGAGCCTGCCCTCTCCTCTACAGCAAAAATCACAATTCTC CTTCTAGATATCAATGACAACCCTCCTCTTGTTTTGTTTCCTCAGTCTAATATGTCTTAT CTGTTAGTACTGCCTTCTACTCTGCCAGGCTCCCCGGTTACAGAAGTCTATGCTGTCGAC AAAGACACAGGCATGAATGCTGTCATAGCTTACAGCATCATAGGGAGAAGAGGTCCTAGG CCTGAGTCCTTCAGGATTGACCCTAAAACTGGCAACATTACTTTGGAAGAGGCATTGCTG CAGACAGATTATGGGCTCCATCGCTTACTGGTGAAAGTGAGTGATCATGGTTATCCCGAG CCTCTCCACTCCACAGTCATGGTGAACCTATTTGTCAATGACACTGTCAGTAATGAGAGT TACATTGAGAGTCTTTTAAGAAAAGAACCAGAGATTAATATAGAGGAGAAAGAACCACAA ATCTCAATAGAACCGACTCATAGGAAGGTAGAATCTGTGTCTTGTATGCCCACCTTAGTA GCTCTGTCTGTAATAAGCTTGGGTTCCATCACACTGGTCACAGGGATGGGCATATACATC TGTTTAAGGAAAGGGGAAAAGCATCCCAGGGAAGATGAAAATTTGGAAGTACAGATTCCA CTGAAAGGAAAAATTGACTTGCATATGCGAGAGAGAAAGCCAATGGATATTTCTAATATT GTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCA AGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGA GCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAA AGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCA TGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGAT AGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGT GTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAA GAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATG GCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGA TGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGG GTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCC GTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGT GCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTT CCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGC GAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATC ATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCAC CAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAG GATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAG GCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAAT ATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCG GACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAA TGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCC TTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACC AAGCGACGCCCAACCGGACTATAAAAGGATCTAGGTGAAGATCCTTTTTGATAATCTCAT GACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGAT CAAAGGATCTTCTTGAAATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAA ACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAA GGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTT AGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTT ACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATA GTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTT GGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCAC GCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGA GCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCG CCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAA AAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACAT GTTCTTTCCTGCGTTATCCCCTGATTCTGTGGATAACCGTATTACCGCCTTTGAGTGAGC TGATACCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATG AAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCAT AGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGT TGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAA TTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCA GTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGAT TAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGT GGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGT GGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGT CGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGA CAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAG GACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCC TTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCG CTCAT
 more Linker info
more Linker info
{kind=link}