


-
SpecieshumanProduct IDFXC11631Cloning SiteSgfI-PmeIGeneKIBB5551SymbolPOR
Alias : CPR, CYPOR, P450RDescriptioncytochrome p450 oxidoreductaseOriginal Clone IDef04264 Length: 2040 bp
Length: 2040 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 680 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)

Entry Exp ID% symbol CCDS5579.1 0 100.0 POR CCDS48061.1 7.9e-65 32.6 NDOR1 CCDS7036.1 3.6e-60 33.1 NDOR1 CCDS11223.1 1.9e-58 31.8 NOS2 CCDS5912.1 7.5e-46 29.6 NOS3
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]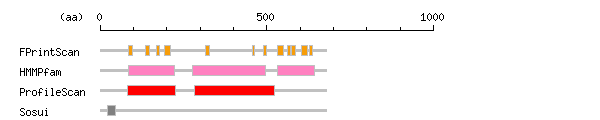 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR001094 84 97 PR00369 Flavodoxin IPR001094 137 148 PR00369 Flavodoxin IPR001094 168 178 PR00369 Flavodoxin IPR001094 192 211 PR00369 Flavodoxin IPR001709 317 327 PR00371 Flavoprotein pyridine nucleotide cytochrome reductase IPR001709 457 464 PR00371 Flavoprotein pyridine nucleotide cytochrome reductase IPR001709 491 500 PR00371 Flavoprotein pyridine nucleotide cytochrome reductase IPR001709 532 551 PR00371 Flavoprotein pyridine nucleotide cytochrome reductase IPR001709 561 570 PR00371 Flavoprotein pyridine nucleotide cytochrome reductase IPR001709 574 585 PR00371 Flavoprotein pyridine nucleotide cytochrome reductase IPR001709 605 621 PR00371 Flavoprotein pyridine nucleotide cytochrome reductase IPR001709 628 636 PR00371 Flavoprotein pyridine nucleotide cytochrome reductase HMMPfam IPR008254 85 222 PF00258 Flavodoxin/nitric oxide synthase IPR003097 277 496 PF00667 FAD-binding IPR001433 533 644 PF00175 Oxidoreductase FAD/NAD(P)-binding ProfileScan IPR008254 83 227 PS50902 Flavodoxin/nitric oxide synthase IPR017927 282 524 PS51384 Ferredoxin reductase-type FAD-binding domain
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 23 VSLFSMTDMILFSLIVGLLTYWF 45 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_000932 680 124015,201750,207410,613571 100.0 100.0 NP_001137498 606 606073 32.6 87.9 NP_055249 597 606073 33.1 87.9 XP_011523164 931 145500,163730,611162 31.8 92.9 XP_011523162 1152 145500,163730,611162 31.8 92.9 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KB5551 Download>KIBB5551 2040 bp ATGATCAACATGGGAGACTCCCACGTGGACACCAGCTCCACCGTGTCCGAGGCGGTGGCC GAAGAAGTATCTCTTTTCAGCATGACGGACATGATTCTGTTTTCGCTCATCGTGGGTCTC CTAACCTACTGGTTCCTCTTCAGAAAGAAAAAAGAAGAAGTCCCCGAGTTCACCAAAATT CAGACATTGACCTCCTCTGTCAGAGAGAGCAGCTTTGTGGAAAAGATGAAGAAAACGGGG AGGAACATCATCGTGTTCTACGGCTCCCAGACGGGGACTGCAGAGGAGTTTGCCAACCGC CTGTCCAAGGACGCCCACCGCTACGGGATGCGAGGCATGTCAGCGGACCCTGAGGAGTAT GACCTGGCCGACCTGAGCAGCCTGCCGGAGATCGACAACGCCCTGGTGGTTTTCTGCATG GCCACCTACGGTGAGGGAGACCCCACCGACAATGCCCAGGACTTCTACGACTGGCTGCAG GAGACAGACGTGGATCTCTCTGGGGTCAAGTTCGCGGTGTTTGGTCTTGGGAACAAGACC TACGAGCACTTCAATGCCATGGGCAAGTACGTGGACAAGCGGCTGGAGCAGCTCGGCGCC CAGCGCATCTTTGAGCTGGGGTTGGGCGACGACGATGGGAACTTGGAGGAGGACTTCATC ACCTGGCGAGAGCAGTTCTGGCCGGCCGTGTGTGAACACTTTGGGGTGGAAGCCACTGGC GAGGAGTCCAGCATTCGCCAGTACGAGCTTGTGGTCCACACCGACATAGATGCGGCCAAG GTGTACATGGGGGAGATGGGCCGGCTGAAGAGCTACGAGAACCAGAAGCCCCCCTTTGAT GCCAAGAATCCGTTCCTGGCTGCAGTCACCACCAACCGGAAGCTGAACCAGGGAACCGAG CGCCACCTCATGCACCTGGAATTGGACATCTCGGACTCCAAAATCAGGTATGAATCTGGG GACCACGTGGCTGTGTACCCAGCCAACGACTCTGCTCTCGTCAACCAGCTGGGCAAAATC CTGGGTGCCGACCTGGACGTCGTCATGTCCCTGAACAACCTGGATGAGGAGTCCAACAAG AAGCACCCATTCCCGTGCCCTACGTCCTACCGCACGGCCCTCACCTACTACCTGGACATC ACCAACCCGCCGCGTACCAACGTGCTGTACGAGCTGGCGCAGTACGCCTCGGAGCCCTCG GAGCAGGAGCTGCTGCGCAAGATGGCCTCCTCCTCCGGCGAGGGCAAGGAGCTGTACCTG AGCTGGGTGGTGGAGGCCCGGAGGCACATCCTGGCCATCCTGCAGGACTGCCCGTCCCTG CGGCCCCCCATCGACCACCTGTGTGAGCTGCTGCCGCGCCTGCAGGCCCGCTACTACTCC ATCGCCTCATCCTCCAAGGTCCACCCCAACTCTGTGCACATCTGTGCGGTGGTTGTGGAG TACGAGACCAAGGCCGGCCGCATCAACAAGGGCGTGGCCACCAACTGGCTGCGGGCCAAG GAGCCTGCCGGGGAGAACGGCGGCCGTGCGCTGGTGCCCATGTTCGTGCGCAAGTCCCAG TTCCGCCTGCCCTTCAAGGCCACCACGCCTGTCATCATGGTGGGCCCCGGCACCGGGGTG GCACCCTTCATAGGCTTCATCCAGGAGCGGGCCTGGCTGCGACAGCAGGGCAAGGAGGTG GGGGAGACGCTGCTGTACTACGGCTGCCGCCGCTCGGATGAGGACTACCTGTACCGGGAG GAGCTGGCGCAGTTCCACAGGGACGGTGCGCTCACCCAGCTCAACGTGGCCTTCTCCCGG GAGCAGTCCCACAAGGTCTACGTCCAGCACCTGCTAAAGCAAGACCGAGAGCACCTGTGG AAGTTGATCGAAGGCGGTGCCCACATCTACGTCTGTGGGGATGCACGGAACATGGCCAGG GATGTGCAGAACACCTTCTACGACATCGTGGCTGAGCTCGGGGCCATGGAGCACGCGCAG GCGGTGGACTACATCAAGAAACTGATGACCAAGGGCCGCTACTCCCTGGACGTGTGGAGC
Cloned ORF protein sequence for pF1KB5551 Download>KIBB5551 680 aa MINMGDSHVDTSSTVSEAVAEEVSLFSMTDMILFSLIVGLLTYWFLFRKKKEEVPEFTKI QTLTSSVRESSFVEKMKKTGRNIIVFYGSQTGTAEEFANRLSKDAHRYGMRGMSADPEEY DLADLSSLPEIDNALVVFCMATYGEGDPTDNAQDFYDWLQETDVDLSGVKFAVFGLGNKT YEHFNAMGKYVDKRLEQLGAQRIFELGLGDDDGNLEEDFITWREQFWPAVCEHFGVEATG EESSIRQYELVVHTDIDAAKVYMGEMGRLKSYENQKPPFDAKNPFLAAVTTNRKLNQGTE RHLMHLELDISDSKIRYESGDHVAVYPANDSALVNQLGKILGADLDVVMSLNNLDEESNK KHPFPCPTSYRTALTYYLDITNPPRTNVLYELAQYASEPSEQELLRKMASSSGEGKELYL SWVVEARRHILAILQDCPSLRPPIDHLCELLPRLQARYYSIASSSKVHPNSVHICAVVVE YETKAGRINKGVATNWLRAKEPAGENGGRALVPMFVRKSQFRLPFKATTPVIMVGPGTGV APFIGFIQERAWLRQQGKEVGETLLYYGCRRSDEDYLYREELAQFHRDGALTQLNVAFSR EQSHKVYVQHLLKQDREHLWKLIEGGAHIYVCGDARNMARDVQNTFYDIVAELGAMEHAQ AVDYIKKLMTKGRYSLDVWS
Nucleotide Sequence (with vector) for pF1KB5551 Download>pF1KB5551 5153 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGATCAACATG GGAGACTCCCACGTGGACACCAGCTCCACCGTGTCCGAGGCGGTGGCCGAAGAAGTATCT CTTTTCAGCATGACGGACATGATTCTGTTTTCGCTCATCGTGGGTCTCCTAACCTACTGG TTCCTCTTCAGAAAGAAAAAAGAAGAAGTCCCCGAGTTCACCAAAATTCAGACATTGACC TCCTCTGTCAGAGAGAGCAGCTTTGTGGAAAAGATGAAGAAAACGGGGAGGAACATCATC GTGTTCTACGGCTCCCAGACGGGGACTGCAGAGGAGTTTGCCAACCGCCTGTCCAAGGAC GCCCACCGCTACGGGATGCGAGGCATGTCAGCGGACCCTGAGGAGTATGACCTGGCCGAC CTGAGCAGCCTGCCGGAGATCGACAACGCCCTGGTGGTTTTCTGCATGGCCACCTACGGT GAGGGAGACCCCACCGACAATGCCCAGGACTTCTACGACTGGCTGCAGGAGACAGACGTG GATCTCTCTGGGGTCAAGTTCGCGGTGTTTGGTCTTGGGAACAAGACCTACGAGCACTTC AATGCCATGGGCAAGTACGTGGACAAGCGGCTGGAGCAGCTCGGCGCCCAGCGCATCTTT GAGCTGGGGTTGGGCGACGACGATGGGAACTTGGAGGAGGACTTCATCACCTGGCGAGAG CAGTTCTGGCCGGCCGTGTGTGAACACTTTGGGGTGGAAGCCACTGGCGAGGAGTCCAGC ATTCGCCAGTACGAGCTTGTGGTCCACACCGACATAGATGCGGCCAAGGTGTACATGGGG GAGATGGGCCGGCTGAAGAGCTACGAGAACCAGAAGCCCCCCTTTGATGCCAAGAATCCG TTCCTGGCTGCAGTCACCACCAACCGGAAGCTGAACCAGGGAACCGAGCGCCACCTCATG CACCTGGAATTGGACATCTCGGACTCCAAAATCAGGTATGAATCTGGGGACCACGTGGCT GTGTACCCAGCCAACGACTCTGCTCTCGTCAACCAGCTGGGCAAAATCCTGGGTGCCGAC CTGGACGTCGTCATGTCCCTGAACAACCTGGATGAGGAGTCCAACAAGAAGCACCCATTC CCGTGCCCTACGTCCTACCGCACGGCCCTCACCTACTACCTGGACATCACCAACCCGCCG CGTACCAACGTGCTGTACGAGCTGGCGCAGTACGCCTCGGAGCCCTCGGAGCAGGAGCTG CTGCGCAAGATGGCCTCCTCCTCCGGCGAGGGCAAGGAGCTGTACCTGAGCTGGGTGGTG GAGGCCCGGAGGCACATCCTGGCCATCCTGCAGGACTGCCCGTCCCTGCGGCCCCCCATC GACCACCTGTGTGAGCTGCTGCCGCGCCTGCAGGCCCGCTACTACTCCATCGCCTCATCC TCCAAGGTCCACCCCAACTCTGTGCACATCTGTGCGGTGGTTGTGGAGTACGAGACCAAG GCCGGCCGCATCAACAAGGGCGTGGCCACCAACTGGCTGCGGGCCAAGGAGCCTGCCGGG GAGAACGGCGGCCGTGCGCTGGTGCCCATGTTCGTGCGCAAGTCCCAGTTCCGCCTGCCC TTCAAGGCCACCACGCCTGTCATCATGGTGGGCCCCGGCACCGGGGTGGCACCCTTCATA GGCTTCATCCAGGAGCGGGCCTGGCTGCGACAGCAGGGCAAGGAGGTGGGGGAGACGCTG CTGTACTACGGCTGCCGCCGCTCGGATGAGGACTACCTGTACCGGGAGGAGCTGGCGCAG TTCCACAGGGACGGTGCGCTCACCCAGCTCAACGTGGCCTTCTCCCGGGAGCAGTCCCAC AAGGTCTACGTCCAGCACCTGCTAAAGCAAGACCGAGAGCACCTGTGGAAGTTGATCGAA GGCGGTGCCCACATCTACGTCTGTGGGGATGCACGGAACATGGCCAGGGATGTGCAGAAC ACCTTCTACGACATCGTGGCTGAGCTCGGGGCCATGGAGCACGCGCAGGCGGTGGACTAC ATCAAGAAACTGATGACCAAGGGCCGCTACTCCCTGGACGTGTGGAGCGTTTAAACGAAT TCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGC TGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGC ATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTAT ATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACT GCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCT GACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCT TTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCT GGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCG CCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTT CGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTA TTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTG TCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAA CTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCT GTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGG CAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCA ATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACAT CGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGAC GAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCG GATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAA AATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAG GACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGC TTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTT CTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCA ACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGC AGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTT GCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAG TCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTC CCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCC TTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGT CGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTT ATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGC AGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAA GTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAA GCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGG TAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGA AGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGG GATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAA TACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGC TTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATAC GGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTAC CTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTAT GGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCA CGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACG CAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGA CCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCA TGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGG CCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGG GAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCAT AAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTC TACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}