Nucleotide Sequence (with vector) for pF1KE1048
Download
>pF1KE1048 4304 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGCTCTGCTC
CGAGGTGTGTTTGTAGTTGCTGCTAAGCGAACGCCCTTTGGAGCTTACGGAGGCCTTCTG
AAAGACTTCACTGCTACTGACTTGTCTGAATTTGCTGCCAAGGCTGCCTTGTCTGCTGGC
AAAGTCTCACCTGAAACAGTTGACAGTGTGATTATGGGCAATGTCCTGCAGAGTTCTTCA
GATGCTATATATTTGGCAAGGCATGTTGGTTTGCGTGTGGGAATCCCAAAGGAGACCCCA
GCTCTCACGATTAATAGGCTCTGTGGTTCTGGTTTTCAGTCCATTGTGAATGGATGTCAG
GAAATTTGTGTTAAAGAAGCTGAAGTTGTTTTATGTGGAGGAACCGAAAGCATGAGCCAA
GCTCCCTACTGTGTCAGAAATGTGCGTTTTGGAACCAAGCTTGGATCAGATATCAAGCTG
GAAGATTCTTTATGGGTATCATTAACAGATCAGCATGTCCAGCTCCCCATGGCAATGACT
GCAGAGAATCTTGCTGTAAAACACAAAATAAGCAGAGAAGAATGTGACAAATATGCCCTG
CAGTCACAGCAGAGATGGAAAGCTGCTAATGATGCTGGCTACTTTAATGATGAAATGGCA
CCAATTGAAGTGAAGACAAAGAAAGGAAAACAGACAATGCAGGTAGACGAGCATGCTCGG
CCCCAAACCACCCTGGAACAGTTACAGAAACTTCCTCCAGTATTCAAGAAAGATGGAACT
GTTACTGCAGGGAATGCATCGGGTGTAGCTGATGGTGCTGGAGCTGTTATCATAGCTAGT
GAAGATGCTGTTAAGAAACATAACTTCACACCACTGGCAAGAATTGTGGGCTACTTTGTA
TCTGGATGTGATCCCTCTATCATGGGTATTGGTCCTGTCCCTGCTATCAGTGGGGCACTG
AAGAAAGCAGGACTGAGTCTTAAGGACATGGATTTGGTAGAGGTGAATGAAGCTTTTGCT
CCCCAGTACTTGGCTGTTGAGAGGAGTTTGGATCTTGACATAAGTAAAACCAATGTGAAT
GGAGGAGCCATTGCTTTGGGTCACCCACTGGGAGGATCTGGATCAAGAATTACTGCACAC
CTGGTTCACGAATTAAGGCGTCGAGGTGGAAAATATGCCGTTGGATCAGCTTGCATTGGA
GGTGGCCAAGGTATTGCTGTCATCATTCAGAGCACAGCCGTTTAAACGAATTCGAGCTCG
GTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAA
AGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCT
TGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTC
GCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTAC
CTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCAT
CCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCC
CTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCC
TCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATC
TGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTT
GAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTAT
GACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAG
GGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGAC
GAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGAC
GTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTC
CTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGG
CTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAG
CGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCAT
CAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAG
GATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGC
TTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCG
TTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTG
CTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAG
TTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGTATC
AGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAA
CATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTT
TTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTG
GCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCG
CTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAG
CGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTC
CAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAA
CTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGG
TAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCC
TAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTAC
CTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGG
TTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTT
GATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGT
CATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAAC
GCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGA
TTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAAT
TTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCT
GCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCC
ACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTC
CGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGG
TCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCC
GAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGT
AGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTT
TTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATT
TGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCA
GGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTC
TTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 1191 bp
Length: 1191 bp Restriction map B
Restriction map B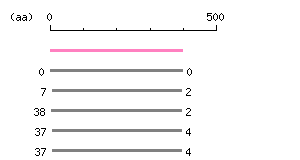

 more Linker info
more Linker info
{kind=link}