Nucleotide Sequence (with vector) for pF1KE1050
Download
>pF1KE1050 4541 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGTCGGGGCCC
ACCTGGCTGCCCCCGAAGCAGCCGGAGCCCGCCAGAGCCCCTCAGGGGAGGGCGATCCCC
CGCGGCACCCCGGGGCCACCACCGGCCCACGGAGCAGCACTCCAGCCCCACCCCAGGGTC
AATTTTTGCCCCCTTCCATCTGAGCAGTGTTACCAGGCCCCAGGGGGACCGGAGGATCGG
GGGCCGGCGTGGGTGGGGTCCCATGGAGTACTCCAGCACACGCAGGGGCTCCCTGCAGAC
AGGGGGGGCCTTCGCCCTGGAAGCCTGGACGCCGAGATAGACTTGCTGAGCAGCACGCTG
GCCGAGCTGAATGGGGGTCGGGGTCATGCGTCACGGCGACCAGACCGACAGGCATATGAG
CCCCCGCCACCTCCTGCCTACCGCACGGGCTCCCTGAAGCCAAATCCAGCCTCGCCGCTC
CCAGCGTCTCCCTATGGGGGCCCCACTCCAGCCTCTTACACTACCGCCAGCACCCCGGCT
GGCCCAGCCTTCCCCGTGCAAGTGAAGGTGGCACAGCCAGTGAGGGGCTGCGGCCCACCC
AGGCGGGGAGCCTCTCAGGCCTCTGGGCCCCTCCCGGGCCCCCACTTTCCTCTCCCAGGC
CGAGGTGAAGTCTGGGGGCCTGGCTATAGGAGCCAGAGAGAGCCAGGGCCAGGGGCCAAA
GAGGAAGCTGCTGGGGTCTCTGGCCCTGCAGGAAGAGGAAGAGGAGGCGAGCACGGGCCC
CAGGTGCCCCTGAGCCAGCCTCCAGAGGATGAGCTGGATAGGCTGACGAAGAAGCTGGTT
CACGACATGAACCACCCGCCCAGCGGGGAGTACTTTGGCCAGTGTGGTGGCTGCGGAGAA
GATGTGGTTGGGGATGGGGCTGGGGTTGTGGCCCTTGATCGCGTCTTTCACGTGGGCTGC
TTTGTATGTTCTACATGCCGGGCCCAGCTTCGCGGCCAGCATTTCTACGCCGTGGAGAGG
AGGGCATATTGCGAGGGCTGCTACGTGGCCACCCTGGAGAAATGTGCCACGTGCTCCCAG
CCCATCCTGGACCGGATCCTGCGGGCTATGGGGAAGGCCTACCACCCTGGCTGCTTCACC
TGCGTGGTGTGTCACCGCGGCCTCGACGGCATCCCCTTCACAGTGGATGCTACGAGCCAG
ATCCACTGCATTGAGGACTTTCACAGGAAGTTTGCCCCAAGATGCTCAGTGTGCGGTGGG
GCCATAATGCCTGAGCCAGGTCAGGAGGAGACTGTGAGAATTGTTGCTCTGGATCGAAGT
TTTCACATTGGCTGTTACAAGTGCGAGGAGTGTGGGCTGCTGCTCTCCTCTGAGGGCGAG
TGTCAGGGCTGCTACCCGCTGGATGGGCACATCTTGTGCAAGGCCTGCAGCGCCTGGCGC
ATCCAGGAGCTCTCAGCCACCGTCACCACTGACTGCGTTTAAACGAATTCGAGCTCGGTA
CCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGC
CCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGG
GGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCT
TGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTG
CTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCG
GGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTT
GCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCT
GGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGA
TGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAA
CAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGAC
TGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGG
CGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAG
GCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTT
GTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTG
TCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTG
CATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGA
GCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAG
GGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGAT
CTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTT
TCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTG
GCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTT
TACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTC
TTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGC
TCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACAT
GTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTT
CCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCG
AAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTC
TCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGT
GGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAA
GCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTA
TCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAA
CAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAA
CTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTT
CGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTT
TTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGAT
CTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCAT
GAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCA
CGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTA
AGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTA
TCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCC
GTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACT
TACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGG
CGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCT
GATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAA
CTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGG
GAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTA
TCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGA
ACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGC
ATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTT
TGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 1428 bp
Length: 1428 bp Restriction map B
Restriction map B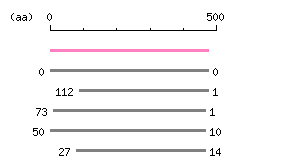

 more Linker info
more Linker info
{kind=link}