


-
SpecieshumanProduct IDFXC22342Cloning SiteSgfI-PmeIGenBank AccessionGeneKIEE2359SymbolHTR4
Alias : 5-HT4, 5-HT4RDescription5-hydroxytryptamine (serotonin) receptor 4, G protein-coupled, transcript variant aOriginal Clone IDcp00766 Length: 1161 bp
Length: 1161 bp
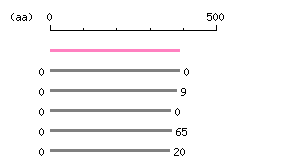
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 387 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
Entry Exp ID% symbol CCDS34270.1 5.1e-114 100.0 HTR4 CCDS4291.1 3.5e-105 95.8 HTR4 CCDS34273.2 4.2e-105 99.7 HTR4 CCDS34272.1 6.3e-105 99.2 HTR4 CCDS34271.1 1.4e-104 100.0 HTR4
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR001520 2 19 PR01059 5-Hydroxytryptamine 4 receptor IPR000276 21 45 PR00237 GPCR IPR001520 44 55 PR01059 5-Hydroxytryptamine 4 receptor IPR000276 55 76 PR00237 GPCR IPR001520 76 92 PR01059 5-Hydroxytryptamine 4 receptor IPR000276 100 122 PR00237 GPCR IPR001520 119 134 PR01059 5-Hydroxytryptamine 4 receptor IPR000276 137 158 PR00237 GPCR IPR001520 153 166 PR01059 5-Hydroxytryptamine 4 receptor IPR001520 168 192 PR01059 5-Hydroxytryptamine 4 receptor IPR000276 193 216 PR00237 GPCR IPR001520 218 234 PR01059 5-Hydroxytryptamine 4 receptor IPR001520 234 253 PR01059 5-Hydroxytryptamine 4 receptor IPR000276 257 281 PR00237 GPCR IPR001520 282 297 PR01059 5-Hydroxytryptamine 4 receptor IPR000276 294 320 PR00237 GPCR IPR001520 321 337 PR01059 5-Hydroxytryptamine 4 receptor IPR001520 337 359 PR01059 5-Hydroxytryptamine 4 receptor HMMPfam IPR000276 36 312 PF00001 GPCR ProfileScan IPR017452 36 312 PS50262 GPCR
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 21 VLLTFLSTVILMAILGNLLVMVA 43 PRIMARY 23 2 57 YFIVSLAFADLLVSVLVMPFGAI 79 PRIMARY 23 3 90 EVFCLVRTSLDVLLTTASIFHLC 112 PRIMARY 23 4 135 PLRIALMLGGCWVIPTFISFLPI 157 PRIMARY 23 5 194 ITCSVVAFYIPFLLMVLAYYRI 215 PRIMARY 22 6 259 KTLCIIMGCFCLCWAPFFVTNIV 281 PRIMARY 23 7 291 GQVWTAFLWLGYINSGLNPFLYA 313 SECONDARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_001035259 387 602164 100.0 100.0 NP_000861 388 602164 95.8 98.2 NP_001035262 360 602164 99.7 93.0 NP_001035263 428 602164 99.2 93.8 NP_955525 378 602164 100.0 92.5 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KE2359 Download>KIEE2359 1161 bp ATGGACAAACTTGATGCTAATGTGAGTTCTGAGGAGGGTTTCGGGTCAGTGGAGAAGGTG GTGCTGCTCACGTTTCTCTCGACGGTTATCCTGATGGCCATCTTGGGGAACCTGCTGGTG ATGGTGGCTGTGTGCTGGGACAGGCAGCTCAGGAAAATAAAAACAAATTATTTCATTGTA TCTCTTGCTTTTGCGGATCTGCTGGTTTCGGTGCTGGTGATGCCCTTTGGTGCCATTGAG CTGGTTCAAGACATCTGGATTTATGGGGAGGTGTTTTGTCTTGTTCGGACATCTCTGGAC GTCCTGCTCACAACGGCATCGATTTTTCACCTGTGCTGCATTTCTCTGGATAGGTATTAC GCCATCTGCTGCCAGCCTTTGGTCTATAGGAACAAGATGACCCCTCTGCGCATCGCATTA ATGCTGGGAGGCTGCTGGGTCATCCCCACGTTTATTTCTTTTCTCCCTATAATGCAAGGC TGGAATAACATTGGCATAATTGATTTGATAGAAAAGAGGAAGTTCAACCAGAACTCTAAC TCTACGTACTGTGTCTTCATGGTCAACAAGCCCTACGCCATCACCTGCTCTGTGGTGGCC TTCTACATCCCATTTCTCCTCATGGTGCTGGCCTATTACCGCATCTATGTCACAGCTAAG GAGCATGCCCATCAGATCCAGATGTTACAACGGGCAGGAGCCTCCTCCGAGAGCAGGCCT CAGTCGGCAGACCAGCATAGCACTCATCGCATGAGGACAGAGACCAAAGCAGCCAAGACC CTGTGCATCATCATGGGTTGCTTCTGCCTCTGCTGGGCACCATTCTTTGTCACCAATATT GTGGATCCTTTCATAGACTACACTGTCCCTGGGCAGGTGTGGACTGCTTTCCTCTGGCTC GGCTATATCAATTCCGGGTTGAACCCTTTTCTCTACGCCTTCTTGAATAAGTCTTTTAGA CGTGCCTTCCTCATCATCCTCTGCTGTGATGATGAGCGCTACCGAAGACCTTCCATTCTG GGCCAGACTGTCCCTTGTTCAACCACAACCATTAATGGATCCACACATGTACTAAGGTAC ACCGTTCTGCACAGGGGACATCATCAGGAACTCGAGAAACTGCCCATACACAATGACCCA GAATCCCTGGAATCATGCTTC
Cloned ORF protein sequence for pF1KE2359 Download>KIEE2359 387 aa MDKLDANVSSEEGFGSVEKVVLLTFLSTVILMAILGNLLVMVAVCWDRQLRKIKTNYFIV SLAFADLLVSVLVMPFGAIELVQDIWIYGEVFCLVRTSLDVLLTTASIFHLCCISLDRYY AICCQPLVYRNKMTPLRIALMLGGCWVIPTFISFLPIMQGWNNIGIIDLIEKRKFNQNSN STYCVFMVNKPYAITCSVVAFYIPFLLMVLAYYRIYVTAKEHAHQIQMLQRAGASSESRP QSADQHSTHRMRTETKAAKTLCIIMGCFCLCWAPFFVTNIVDPFIDYTVPGQVWTAFLWL GYINSGLNPFLYAFLNKSFRRAFLIILCCDDERYRRPSILGQTVPCSTTTINGSTHVLRY TVLHRGHHQELEKLPIHNDPESLESCF
Nucleotide Sequence (with vector) for pF1KE2359 Download>pF1KE2359 4274 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGACAAACTT GATGCTAATGTGAGTTCTGAGGAGGGTTTCGGGTCAGTGGAGAAGGTGGTGCTGCTCACG TTTCTCTCGACGGTTATCCTGATGGCCATCTTGGGGAACCTGCTGGTGATGGTGGCTGTG TGCTGGGACAGGCAGCTCAGGAAAATAAAAACAAATTATTTCATTGTATCTCTTGCTTTT GCGGATCTGCTGGTTTCGGTGCTGGTGATGCCCTTTGGTGCCATTGAGCTGGTTCAAGAC ATCTGGATTTATGGGGAGGTGTTTTGTCTTGTTCGGACATCTCTGGACGTCCTGCTCACA ACGGCATCGATTTTTCACCTGTGCTGCATTTCTCTGGATAGGTATTACGCCATCTGCTGC CAGCCTTTGGTCTATAGGAACAAGATGACCCCTCTGCGCATCGCATTAATGCTGGGAGGC TGCTGGGTCATCCCCACGTTTATTTCTTTTCTCCCTATAATGCAAGGCTGGAATAACATT GGCATAATTGATTTGATAGAAAAGAGGAAGTTCAACCAGAACTCTAACTCTACGTACTGT GTCTTCATGGTCAACAAGCCCTACGCCATCACCTGCTCTGTGGTGGCCTTCTACATCCCA TTTCTCCTCATGGTGCTGGCCTATTACCGCATCTATGTCACAGCTAAGGAGCATGCCCAT CAGATCCAGATGTTACAACGGGCAGGAGCCTCCTCCGAGAGCAGGCCTCAGTCGGCAGAC CAGCATAGCACTCATCGCATGAGGACAGAGACCAAAGCAGCCAAGACCCTGTGCATCATC ATGGGTTGCTTCTGCCTCTGCTGGGCACCATTCTTTGTCACCAATATTGTGGATCCTTTC ATAGACTACACTGTCCCTGGGCAGGTGTGGACTGCTTTCCTCTGGCTCGGCTATATCAAT TCCGGGTTGAACCCTTTTCTCTACGCCTTCTTGAATAAGTCTTTTAGACGTGCCTTCCTC ATCATCCTCTGCTGTGATGATGAGCGCTACCGAAGACCTTCCATTCTGGGCCAGACTGTC CCTTGTTCAACCACAACCATTAATGGATCCACACATGTACTAAGGTACACCGTTCTGCAC AGGGGACATCATCAGGAACTCGAGAAACTGCCCATACACAATGACCCAGAATCCCTGGAA TCATGCTTCGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGC AGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGC CACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTT TTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAG CTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCT TGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGC TTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGA GCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTA AACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAA GAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCG GCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCT GATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGAC CTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACG ACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTG CTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAA GTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCA TTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTT GTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCC AGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGC TTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTG GGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTT GGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAG CGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAA TGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATC CACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAG GAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCA TCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCA GGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGG ATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAG GTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGT TCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACA CGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGG CGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATT TGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATC CGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCG CAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTG GAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTA GATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGT GAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTC TGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGG GTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGG TGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGA TAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCT GATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAG TAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGA TGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAA AGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCC TGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGT GGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGA CGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAAT ATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}