


-
SpecieshumanProduct IDFXC23022Cloning SiteSgfI-PmeIGenBank AccessionGeneKIEE3342SymbolEPHB4
Alias : CMAVM2, HFASD, HTK, LMPHM7, MYK1, TYRO11DescriptionEPH receptor B4Original Clone IDcp93342 Length: 2961 bp
Length: 2961 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 987 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
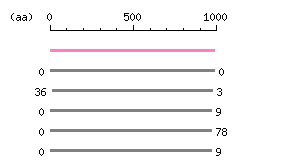
Entry Exp ID% symbol CCDS5706.1 1.2e-203 100.0 EPHB4 CCDS3268.1 1.3e-115 60.1 EPHB3 CCDS229.2 2.3e-110 56.0 EPHB2 CCDS81279.1 2.4e-110 56.0 EPHB2 CCDS230.1 2.5e-110 56.1 EPHB2
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR001245 693 706 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 730 748 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 782 792 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 801 823 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 845 867 PR00109 Serine-threonine/tyrosine-protein kinase HMMPfam IPR001090 17 197 PF01404 Ephrin receptor IPR011641 263 299 PF07699 Tyrosine-protein kinase ephrin type A/B receptor-like IPR003961 325 412 PF00041 Fibronectin IPR003961 435 518 PF00041 Fibronectin IPR001245 616 874 PF07714 Serine-threonine/tyrosine-protein kinase IPR021129 907 969 PF00536 Sterile alpha motif HMMSmart IPR001090 17 197 SM00615 Ephrin receptor IPR003961 324 413 SM00060 Fibronectin IPR003961 434 516 SM00060 Fibronectin IPR002290 615 878 SM00220 Serine/threonine-protein kinase domain IPR020635 615 874 SM00219 Tyrosine-protein kinase IPR001660 904 971 SM00454 Sterile alpha motif domain ProfileScan IPR003961 323 428 PS50853 Fibronectin IPR003961 434 526 PS50853 Fibronectin IPR000719 615 899 PS50011 Protein kinase IPR001660 907 971 PS50105 Sterile alpha motif domain
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 1 MELRVLLCWASLAAALEETLLNT 23 PRIMARY 23 2 539 ALIAGTAVVGVVLVLVVIVVAVL 561 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_004435 987 600011 100.0 100.0 NP_004434 998 601839 60.1 97.6 NP_059145 986 600997,603688 56.0 98.4 NP_001296122 1055 600997,603688 56.0 98.4 NP_004433 987 600997,603688 56.1 98.4 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KE3342 Download>KIEE3342 2961 bp ATGGAGCTCCGGGTGCTGCTCTGCTGGGCTTCGTTGGCCGCAGCTTTGGAAGAGACCCTG CTGAACACAAAATTGGAAACTGCTGATCTGAAGTGGGTGACATTCCCTCAGGTGGACGGG CAGTGGGAGGAACTGAGCGGCCTGGATGAGGAACAGCACAGCGTGCGCACCTACGAAGTG TGTGACGTGCAGCGTGCCCCGGGCCAGGCCCACTGGCTTCGCACAGGTTGGGTCCCACGG CGGGGCGCCGTCCACGTGTACGCCACGCTGCGCTTCACCATGCTCGAGTGCCTGTCCCTG CCTCGGGCTGGGCGCTCCTGCAAGGAGACCTTCACCGTCTTCTACTATGAGAGCGATGCG GACACGGCCACGGCCCTCACGCCAGCCTGGATGGAGAACCCCTACATCAAGGTGGACACG GTGGCCGCGGAGCATCTCACCCGGAAGCGCCCTGGGGCCGAGGCCACCGGGAAGGTGAAT GTCAAGACGCTGCGTCTGGGACCGCTCAGCAAGGCTGGCTTCTACCTGGCCTTCCAGGAC CAGGGTGCCTGCATGGCCCTGCTATCCCTGCACCTCTTCTACAAAAAGTGCGCCCAGCTG ACTGTGAACCTGACTCGATTCCCGGAGACTGTGCCTCGGGAGCTGGTTGTGCCCGTGGCC GGTAGCTGCGTGGTGGATGCCGTCCCCGCCCCTGGCCCCAGCCCCAGCCTCTACTGCCGT GAGGATGGCCAGTGGGCCGAACAGCCGGTCACGGGCTGCAGCTGTGCTCCGGGGTTCGAG GCAGCTGAGGGGAACACCAAGTGCCGAGCCTGTGCCCAGGGCACCTTCAAGCCCCTGTCA GGAGAAGGGTCCTGCCAGCCATGCCCAGCCAATAGCCACTCTAACACCATTGGATCAGCC GTCTGCCAGTGCCGCGTCGGGTACTTCCGGGCACGCACAGACCCCCGGGGTGCACCCTGC ACCACCCCTCCTTCGGCTCCGCGGAGCGTGGTTTCCCGCCTGAACGGCTCCTCCCTGCAC CTGGAATGGAGTGCCCCCCTGGAGTCTGGTGGCCGAGAGGACCTCACCTACGCCCTCCGC TGCCGGGAGTGCCGACCCGGAGGCTCCTGTGCGCCCTGCGGGGGAGACCTGACTTTTGAC CCCGGCCCCCGGGACCTGGTGGAGCCCTGGGTGGTGGTTCGAGGGCTACGTCCTGACTTC ACCTATACCTTTGAGGTCACTGCATTGAACGGGGTATCCTCCTTAGCCACGGGGCCCGTC CCATTTGAGCCTGTCAATGTCACCACTGACCGAGAGGTACCTCCTGCAGTGTCCGACATC CGGGTGACGCGGTCCTCACCCAGCAGCTTGAGCCTGGCCTGGGCTGTTCCCCGGGCACCC AGTGGGGCTGTGCTGGACTACGAGGTCAAATACCATGAGAAGGGCGCCGAGGGTCCCAGC AGCGTGCGGTTCCTGAAGACGTCAGAAAACCGGGCAGAGCTGCGGGGGCTGAAGCGGGGA GCCAGCTACCTGGTGCAGGTACGGGCGCGCTCTGAGGCCGGCTACGGGCCCTTCGGCCAG GAACATCACAGCCAGACCCAACTGGATGAGAGCGAGGGCTGGCGGGAGCAGCTGGCCCTG ATTGCGGGCACGGCAGTCGTGGGTGTGGTCCTGGTCCTGGTGGTCATTGTGGTCGCAGTT CTCTGCCTCAGGAAGCAGAGCAATGGGAGAGAAGCAGAATATTCGGACAAACACGGACAG TATCTCATCGGGCATGGTACTAAGGTCTACATCGACCCCTTCACTTATGAAGACCCTAAT GAGGCTGTGAGGGAATTTGCAAAAGAGATCGATGTCTCCTACGTCAAGATTGAAGAGGTG ATTGGTGCAGGTGAGTTTGGCGAGGTGTGCCGGGGGCGGCTCAAGGCCCCAGGGAAGAAG GAGAGCTGTGTGGCAATCAAGACCCTGAAGGGTGGCTACACGGAGCGGCAGCGGCGTGAG TTTCTGAGCGAGGCCTCCATCATGGGCCAGTTCGAGCACCCCAATATCATCCGCCTGGAG GGCGTGGTCACCAACAGCATGCCCGTCATGATTCTCACAGAGTTCATGGAGAACGGCGCC CTGGACTCCTTCCTGCGGCTAAACGACGGACAGTTCACAGTCATCCAGCTCGTGGGCATG CTGCGGGGCATCGCCTCGGGCATGCGGTACCTTGCCGAGATGAGCTACGTCCACCGAGAC CTGGCTGCTCGCAACATCCTAGTCAACAGCAACCTCGTCTGCAAAGTGTCTGACTTTGGC CTTTCCCGATTCCTGGAGGAGAACTCTTCCGATCCCACCTACACGAGCTCCCTGGGAGGA AAGATTCCCATCCGATGGACTGCCCCGGAGGCCATTGCCTTCCGGAAGTTCACTTCCGCC AGTGATGCCTGGAGTTACGGGATTGTGATGTGGGAGGTGATGTCATTTGGGGAGAGGCCG TACTGGGACATGAGCAATCAGGACGTGATCAATGCCATTGAACAGGACTACCGGCTGCCC CCGCCCCCAGACTGTCCCACCTCCCTCCACCAGCTCATGCTGGACTGTTGGCAGAAAGAC CGGAATGCCCGGCCCCGCTTCCCCCAGGTGGTCAGCGCCCTGGACAAGATGATCCGGAAC CCCGCCAGCCTCAAAATCGTGGCCCGGGAGAATGGCGGGGCCTCACACCCTCTCCTGGAC CAGCGGCAGCCTCACTACTCAGCTTTTGGCTCTGTGGGCGAGTGGCTTCGGGCCATCAAA ATGGGAAGATACGAAGAAAGTTTCGCAGCCGCTGGCTTTGGCTCCTTCGAGCTGGTCAGC CAGATCTCTGCTGAGGACCTGCTCCGAATCGGAGTCACTCTGGCGGGACACCAGAAGAAA ATCTTGGCCAGTGTCCAGCACATGAAGTCCCAGGCCAAGCCGGGAACCCCGGGTGGGACA GGAGGACCGGCCCCGCAGTAC
Cloned ORF protein sequence for pF1KE3342 Download>KIEE3342 987 aa MELRVLLCWASLAAALEETLLNTKLETADLKWVTFPQVDGQWEELSGLDEEQHSVRTYEV CDVQRAPGQAHWLRTGWVPRRGAVHVYATLRFTMLECLSLPRAGRSCKETFTVFYYESDA DTATALTPAWMENPYIKVDTVAAEHLTRKRPGAEATGKVNVKTLRLGPLSKAGFYLAFQD QGACMALLSLHLFYKKCAQLTVNLTRFPETVPRELVVPVAGSCVVDAVPAPGPSPSLYCR EDGQWAEQPVTGCSCAPGFEAAEGNTKCRACAQGTFKPLSGEGSCQPCPANSHSNTIGSA VCQCRVGYFRARTDPRGAPCTTPPSAPRSVVSRLNGSSLHLEWSAPLESGGREDLTYALR CRECRPGGSCAPCGGDLTFDPGPRDLVEPWVVVRGLRPDFTYTFEVTALNGVSSLATGPV PFEPVNVTTDREVPPAVSDIRVTRSSPSSLSLAWAVPRAPSGAVLDYEVKYHEKGAEGPS SVRFLKTSENRAELRGLKRGASYLVQVRARSEAGYGPFGQEHHSQTQLDESEGWREQLAL IAGTAVVGVVLVLVVIVVAVLCLRKQSNGREAEYSDKHGQYLIGHGTKVYIDPFTYEDPN EAVREFAKEIDVSYVKIEEVIGAGEFGEVCRGRLKAPGKKESCVAIKTLKGGYTERQRRE FLSEASIMGQFEHPNIIRLEGVVTNSMPVMILTEFMENGALDSFLRLNDGQFTVIQLVGM LRGIASGMRYLAEMSYVHRDLAARNILVNSNLVCKVSDFGLSRFLEENSSDPTYTSSLGG KIPIRWTAPEAIAFRKFTSASDAWSYGIVMWEVMSFGERPYWDMSNQDVINAIEQDYRLP PPPDCPTSLHQLMLDCWQKDRNARPRFPQVVSALDKMIRNPASLKIVARENGGASHPLLD QRQPHYSAFGSVGEWLRAIKMGRYEESFAAAGFGSFELVSQISAEDLLRIGVTLAGHQKK ILASVQHMKSQAKPGTPGGTGGPAPQY
Nucleotide Sequence (with vector) for pF1KE3342 Download>pF1KE3342 6074 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGAGCTCCGG GTGCTGCTCTGCTGGGCTTCGTTGGCCGCAGCTTTGGAAGAGACCCTGCTGAACACAAAA TTGGAAACTGCTGATCTGAAGTGGGTGACATTCCCTCAGGTGGACGGGCAGTGGGAGGAA CTGAGCGGCCTGGATGAGGAACAGCACAGCGTGCGCACCTACGAAGTGTGTGACGTGCAG CGTGCCCCGGGCCAGGCCCACTGGCTTCGCACAGGTTGGGTCCCACGGCGGGGCGCCGTC CACGTGTACGCCACGCTGCGCTTCACCATGCTCGAGTGCCTGTCCCTGCCTCGGGCTGGG CGCTCCTGCAAGGAGACCTTCACCGTCTTCTACTATGAGAGCGATGCGGACACGGCCACG GCCCTCACGCCAGCCTGGATGGAGAACCCCTACATCAAGGTGGACACGGTGGCCGCGGAG CATCTCACCCGGAAGCGCCCTGGGGCCGAGGCCACCGGGAAGGTGAATGTCAAGACGCTG CGTCTGGGACCGCTCAGCAAGGCTGGCTTCTACCTGGCCTTCCAGGACCAGGGTGCCTGC ATGGCCCTGCTATCCCTGCACCTCTTCTACAAAAAGTGCGCCCAGCTGACTGTGAACCTG ACTCGATTCCCGGAGACTGTGCCTCGGGAGCTGGTTGTGCCCGTGGCCGGTAGCTGCGTG GTGGATGCCGTCCCCGCCCCTGGCCCCAGCCCCAGCCTCTACTGCCGTGAGGATGGCCAG TGGGCCGAACAGCCGGTCACGGGCTGCAGCTGTGCTCCGGGGTTCGAGGCAGCTGAGGGG AACACCAAGTGCCGAGCCTGTGCCCAGGGCACCTTCAAGCCCCTGTCAGGAGAAGGGTCC TGCCAGCCATGCCCAGCCAATAGCCACTCTAACACCATTGGATCAGCCGTCTGCCAGTGC CGCGTCGGGTACTTCCGGGCACGCACAGACCCCCGGGGTGCACCCTGCACCACCCCTCCT TCGGCTCCGCGGAGCGTGGTTTCCCGCCTGAACGGCTCCTCCCTGCACCTGGAATGGAGT GCCCCCCTGGAGTCTGGTGGCCGAGAGGACCTCACCTACGCCCTCCGCTGCCGGGAGTGC CGACCCGGAGGCTCCTGTGCGCCCTGCGGGGGAGACCTGACTTTTGACCCCGGCCCCCGG GACCTGGTGGAGCCCTGGGTGGTGGTTCGAGGGCTACGTCCTGACTTCACCTATACCTTT GAGGTCACTGCATTGAACGGGGTATCCTCCTTAGCCACGGGGCCCGTCCCATTTGAGCCT GTCAATGTCACCACTGACCGAGAGGTACCTCCTGCAGTGTCCGACATCCGGGTGACGCGG TCCTCACCCAGCAGCTTGAGCCTGGCCTGGGCTGTTCCCCGGGCACCCAGTGGGGCTGTG CTGGACTACGAGGTCAAATACCATGAGAAGGGCGCCGAGGGTCCCAGCAGCGTGCGGTTC CTGAAGACGTCAGAAAACCGGGCAGAGCTGCGGGGGCTGAAGCGGGGAGCCAGCTACCTG GTGCAGGTACGGGCGCGCTCTGAGGCCGGCTACGGGCCCTTCGGCCAGGAACATCACAGC CAGACCCAACTGGATGAGAGCGAGGGCTGGCGGGAGCAGCTGGCCCTGATTGCGGGCACG GCAGTCGTGGGTGTGGTCCTGGTCCTGGTGGTCATTGTGGTCGCAGTTCTCTGCCTCAGG AAGCAGAGCAATGGGAGAGAAGCAGAATATTCGGACAAACACGGACAGTATCTCATCGGG CATGGTACTAAGGTCTACATCGACCCCTTCACTTATGAAGACCCTAATGAGGCTGTGAGG GAATTTGCAAAAGAGATCGATGTCTCCTACGTCAAGATTGAAGAGGTGATTGGTGCAGGT GAGTTTGGCGAGGTGTGCCGGGGGCGGCTCAAGGCCCCAGGGAAGAAGGAGAGCTGTGTG GCAATCAAGACCCTGAAGGGTGGCTACACGGAGCGGCAGCGGCGTGAGTTTCTGAGCGAG GCCTCCATCATGGGCCAGTTCGAGCACCCCAATATCATCCGCCTGGAGGGCGTGGTCACC AACAGCATGCCCGTCATGATTCTCACAGAGTTCATGGAGAACGGCGCCCTGGACTCCTTC CTGCGGCTAAACGACGGACAGTTCACAGTCATCCAGCTCGTGGGCATGCTGCGGGGCATC GCCTCGGGCATGCGGTACCTTGCCGAGATGAGCTACGTCCACCGAGACCTGGCTGCTCGC AACATCCTAGTCAACAGCAACCTCGTCTGCAAAGTGTCTGACTTTGGCCTTTCCCGATTC CTGGAGGAGAACTCTTCCGATCCCACCTACACGAGCTCCCTGGGAGGAAAGATTCCCATC CGATGGACTGCCCCGGAGGCCATTGCCTTCCGGAAGTTCACTTCCGCCAGTGATGCCTGG AGTTACGGGATTGTGATGTGGGAGGTGATGTCATTTGGGGAGAGGCCGTACTGGGACATG AGCAATCAGGACGTGATCAATGCCATTGAACAGGACTACCGGCTGCCCCCGCCCCCAGAC TGTCCCACCTCCCTCCACCAGCTCATGCTGGACTGTTGGCAGAAAGACCGGAATGCCCGG CCCCGCTTCCCCCAGGTGGTCAGCGCCCTGGACAAGATGATCCGGAACCCCGCCAGCCTC AAAATCGTGGCCCGGGAGAATGGCGGGGCCTCACACCCTCTCCTGGACCAGCGGCAGCCT CACTACTCAGCTTTTGGCTCTGTGGGCGAGTGGCTTCGGGCCATCAAAATGGGAAGATAC GAAGAAAGTTTCGCAGCCGCTGGCTTTGGCTCCTTCGAGCTGGTCAGCCAGATCTCTGCT GAGGACCTGCTCCGAATCGGAGTCACTCTGGCGGGACACCAGAAGAAAATCTTGGCCAGT GTCCAGCACATGAAGTCCCAGGCCAAGCCGGGAACCCCGGGTGGGACAGGAGGACCGGCC CCGCAGTACGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGC AGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGC CACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTT TTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAG CTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCT TGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGC TTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGA GCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTA AACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAA GAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCG GCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCT GATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGAC CTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACG ACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTG CTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAA GTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCA TTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTT GTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCC AGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGC TTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTG GGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTT GGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAG CGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAA TGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATC CACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAG GAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCA TCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCA GGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGG ATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAG GTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGT TCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACA CGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGG CGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATT TGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATC CGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCG CAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTG GAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTA GATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGT GAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTC TGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGG GTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGG TGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGA TAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCT GATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAG TAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGA TGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAA AGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCC TGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGT GGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGA CGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAAT ATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}