


-
SpecieshumanProduct IDFXC03524Cloning SiteSgfI-PmeIGeneKIBB0408SymbolZBTB17
Alias : MIZ-1, ZNF151, ZNF60, pHZ-67Descriptionzinc finger and BTB domain containing 17, transcript variant 2Original Clone IDcs01908 Length: 2409 bp
Length: 2409 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 803 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
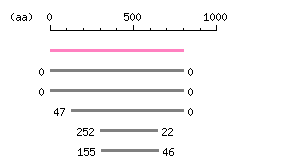
Entry Exp ID% symbol CCDS165.1 5e-162 100.0 ZBTB17 CCDS72712.1 2.7e-161 99.1 ZBTB17 CCDS55576.1 8.2e-136 99.7 ZBTB17 CCDS59372.1 7.8e-34 49.6 ZNF726 CCDS2719.1 4e-32 46.2 ZNF502
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition HMMPfam IPR013069 14 110 PF00651 BTB/POZ IPR007087 306 328 PF00096 Zinc finger IPR007087 390 412 PF00096 Zinc finger IPR007087 418 440 PF00096 Zinc finger IPR007087 475 496 PF00096 Zinc finger IPR007087 558 580 PF00096 Zinc finger HMMSmart IPR000210 24 116 SM00225 BTB/POZ-like IPR015880 306 328 SM00355 Zinc finger IPR015880 334 356 SM00355 Zinc finger IPR015880 362 384 SM00355 Zinc finger IPR015880 390 412 SM00355 Zinc finger IPR015880 418 440 SM00355 Zinc finger IPR015880 446 468 SM00355 Zinc finger IPR015880 474 496 SM00355 Zinc finger IPR015880 502 524 SM00355 Zinc finger IPR015880 530 552 SM00355 Zinc finger IPR015880 558 580 SM00355 Zinc finger IPR015880 586 608 SM00355 Zinc finger IPR015880 614 637 SM00355 Zinc finger IPR015880 717 739 SM00355 Zinc finger ProfileScan IPR000210 24 86 PS50097 BTB/POZ-like IPR007087 306 333 PS50157 Zinc finger IPR007087 334 361 PS50157 Zinc finger IPR007087 362 389 PS50157 Zinc finger IPR007087 390 417 PS50157 Zinc finger IPR007087 418 445 PS50157 Zinc finger IPR007087 446 473 PS50157 Zinc finger IPR007087 474 501 PS50157 Zinc finger IPR007087 502 529 PS50157 Zinc finger IPR007087 530 557 PS50157 Zinc finger IPR007087 558 585 PS50157 Zinc finger IPR007087 586 613 PS50157 Zinc finger IPR007087 614 642 PS50157 Zinc finger IPR007087 717 744 PS50157 Zinc finger
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_003434 803 604084 100.0 100.0 NP_001274532 810 604084 99.1 100.0 NP_001311066 727 604084 100.0 90.5 NP_001274533 727 604084 100.0 90.5 XP_011540387 734 604084 99.0 90.5 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KB0408 Download>KIBB0408 2409 bp ATGGACTTTCCCCAGCACAGCCAGCATGTCTTGGAACAGCTGAACCAGCAGCGGCAGCTG GGGCTTCTCTGTGACTGCACCTTTGTGGTGGACGGTGTTCACTTTAAGGCTCATAAAGCA GTGCTGGCGGCCTGCAGCGAGTACTTCAAGATGCTCTTCGTGGACCAGAAGGACGTGGTG CACCTGGACATCAGTAACGCGGCAGGCCTGGGGCAGGTGCTGGAGTTTATGTACACGGCC AAGCTGAGCCTGAGCCCTGAGAACGTGGATGATGTGCTGGCCGTGGCCACTTTCCTCCAA ATGCAGGACATCATCACGGCCTGCCATGCCCTCAAGTCACTTGCTGAGCCGGCTACCAGC CCTGGGGGAAATGCGGAGGCCTTGGCCACAGAAGGAGGGGACAAGAGAGCCAAAGAGGAG AAGGTGGCCACCAGCACGCTGAGCAGGCTGGAGCAGGCAGGACGCAGCACACCCATAGGC CCCAGCAGGGACCTCAAGGAGGAGCGCGGCGGTCAGGCCCAGAGTGCGGCCAGCGGTGCA GAGCAGACAGAGAAAGCCGATGCGCCCCGGGAGCCGCCGCCTGTGGAGCTCAAGCCAGAC CCCACGAGTGGCATGGCTGCTGCAGAAGCTGAGGCCGCTTTGTCCGAGAGCTCGGAGCAA GAAATGGAGGTGGAGCCCGCCCGGAAAGGGGAAGAGGAGCAAAAGGAGCAAGAGGAGCAA GAGGAGGAGGGCGCAGGGCCAGCTGAGGTCAAGGAGGAGGGTTCCCAGCTGGAGAACGGA GAGGCCCCCGAGGAGAACGAGAATGAGGAGTCAGCGGGCACAGACTCGGGGCAGGAGCTC GGCTCCGAGGCCCGGGGCCTGCGCTCAGGCACCTACGGCGACCGCACGGAGTCCAAGGCC TACGGCTCCGTCATCCACAAGTGCGAGGACTGTGGGAAGGAGTTCACGCACACGGGGAAC TTCAAGCGGCACATCCGCATCCACACGGGGGAGAAGCCCTTCTCGTGCCGGGAGTGCAGC AAGGCCTTTTCCGACCCGGCCGCGTGCAAGGCCCATGAGAAGACGCACAGCCCTCTGAAG CCCTACGGCTGCGAGGAGTGCGGGAAGAGCTACCGCCTCATCAGCCTGCTGAACCTGCAC AAGAAGCGGCACTCGGGCGAGGCGCGCTACCGCTGCGAGGACTGCGGCAAGCTCTTCACC ACCTCGGGCAACCTCAAGCGCCACCAGCTGGTGCACAGCGGCGAGAAGCCCTACCAGTGC GACTACTGCGGCCGCTCCTTCTCCGACCCCACTTCCAAGATGCGCCACCTGGAGACCCAC GACACGGACAAGGAGCACAAGTGCCCACACTGCGACAAGAAGTTCAACCAGGTAGGGAAC CTGAAGGCCCACCTGAAGATCCACATCGCTGACGGGCCCCTCAAGTGCCGAGAGTGTGGG AAGCAGTTCACCACCTCAGGGAACCTGAAGCGGCACCTTCGGATCCACAGCGGGGAGAAG CCCTACGTGTGCATCCACTGCCAGCGACAGTTTGCAGACCCCGGCGCTCTGCAGCGGCAC GTCCGCATTCACACAGGTGAGAAGCCATGCCAGTGTGTGATGTGCGGTAAGGCCTTCACC CAGGCCAGCTCCCTCATCGCCCACGTGCGCCAGCACACCGGGGAGAAGCCCTACGTCTGC GAGCGCTGCGGCAAGAGATTCGTCCAGTCCAGCCAGTTGGCCAATCATATTCGCCACCAC GACAACATCCGCCCACACAAGTGCAGCGTGTGCAGCAAGGCCTTCGTGAACGTGGGGGAC CTGTCCAAGCACATCATCATTCACACTGGAGAGAAGCCTTACCTGTGTGATAAGTGTGGG CGTGGCTTCAACCGGGTAGACAACCTGCGCTCCCACGTGAAGACCGTGCACCAGGGCAAG GCAGGCATCAAGATCCTGGAGCCCGAGGAGGGCAGTGAGGTCAGCGTGGTCACTGTGGAT GACATGGTCACGCTGGCTACCGAGGCACTGGCAGCGACAGCCGTCACTCAGCTCACAGTG GTGCCGGTGGGAGCTGCAGTGACAGCCGATGAGACGGAAGTCCTGAAGGCCGAGATCAGC AAAGCTGTGAAGCAAGTGCAGGAAGAAGACCCCAACACTCACATCCTCTACGCCTGTGAC TCCTGTGGGGACAAGTTTCTGGATGCCAACAGCCTGGCTCAGCATGTGCGAATCCACACA GCCCAGGCACTGGTCATGTTCCAGACAGACGCGGACTTCTATCAGCAGTATGGGCCAGGT GGCACGTGGCCTGCCGGGCAGGTGCTGCAGGCTGGGGAGCTGGTCTTCCGCCCTCGCGAC GGGGCTGAGGGCCAGCCCGCACTGGCAGAGACCTCCCCTACAGCTCCTGAATGTCCCCCG CCTGCCGAG
Cloned ORF protein sequence for pF1KB0408 Download>KIBB0408 803 aa MDFPQHSQHVLEQLNQQRQLGLLCDCTFVVDGVHFKAHKAVLAACSEYFKMLFVDQKDVV HLDISNAAGLGQVLEFMYTAKLSLSPENVDDVLAVATFLQMQDIITACHALKSLAEPATS PGGNAEALATEGGDKRAKEEKVATSTLSRLEQAGRSTPIGPSRDLKEERGGQAQSAASGA EQTEKADAPREPPPVELKPDPTSGMAAAEAEAALSESSEQEMEVEPARKGEEEQKEQEEQ EEEGAGPAEVKEEGSQLENGEAPEENENEESAGTDSGQELGSEARGLRSGTYGDRTESKA YGSVIHKCEDCGKEFTHTGNFKRHIRIHTGEKPFSCRECSKAFSDPAACKAHEKTHSPLK PYGCEECGKSYRLISLLNLHKKRHSGEARYRCEDCGKLFTTSGNLKRHQLVHSGEKPYQC DYCGRSFSDPTSKMRHLETHDTDKEHKCPHCDKKFNQVGNLKAHLKIHIADGPLKCRECG KQFTTSGNLKRHLRIHSGEKPYVCIHCQRQFADPGALQRHVRIHTGEKPCQCVMCGKAFT QASSLIAHVRQHTGEKPYVCERCGKRFVQSSQLANHIRHHDNIRPHKCSVCSKAFVNVGD LSKHIIIHTGEKPYLCDKCGRGFNRVDNLRSHVKTVHQGKAGIKILEPEEGSEVSVVTVD DMVTLATEALAATAVTQLTVVPVGAAVTADETEVLKAEISKAVKQVQEEDPNTHILYACD SCGDKFLDANSLAQHVRIHTAQALVMFQTDADFYQQYGPGGTWPAGQVLQAGELVFRPRD GAEGQPALAETSPTAPECPPPAE
Nucleotide Sequence (with vector) for pF1KB0408 Download>pF1KB0408 5522 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGACTTTCCC CAGCACAGCCAGCATGTCTTGGAACAGCTGAACCAGCAGCGGCAGCTGGGGCTTCTCTGT GACTGCACCTTTGTGGTGGACGGTGTTCACTTTAAGGCTCATAAAGCAGTGCTGGCGGCC TGCAGCGAGTACTTCAAGATGCTCTTCGTGGACCAGAAGGACGTGGTGCACCTGGACATC AGTAACGCGGCAGGCCTGGGGCAGGTGCTGGAGTTTATGTACACGGCCAAGCTGAGCCTG AGCCCTGAGAACGTGGATGATGTGCTGGCCGTGGCCACTTTCCTCCAAATGCAGGACATC ATCACGGCCTGCCATGCCCTCAAGTCACTTGCTGAGCCGGCTACCAGCCCTGGGGGAAAT GCGGAGGCCTTGGCCACAGAAGGAGGGGACAAGAGAGCCAAAGAGGAGAAGGTGGCCACC AGCACGCTGAGCAGGCTGGAGCAGGCAGGACGCAGCACACCCATAGGCCCCAGCAGGGAC CTCAAGGAGGAGCGCGGCGGTCAGGCCCAGAGTGCGGCCAGCGGTGCAGAGCAGACAGAG AAAGCCGATGCGCCCCGGGAGCCGCCGCCTGTGGAGCTCAAGCCAGACCCCACGAGTGGC ATGGCTGCTGCAGAAGCTGAGGCCGCTTTGTCCGAGAGCTCGGAGCAAGAAATGGAGGTG GAGCCCGCCCGGAAAGGGGAAGAGGAGCAAAAGGAGCAAGAGGAGCAAGAGGAGGAGGGC GCAGGGCCAGCTGAGGTCAAGGAGGAGGGTTCCCAGCTGGAGAACGGAGAGGCCCCCGAG GAGAACGAGAATGAGGAGTCAGCGGGCACAGACTCGGGGCAGGAGCTCGGCTCCGAGGCC CGGGGCCTGCGCTCAGGCACCTACGGCGACCGCACGGAGTCCAAGGCCTACGGCTCCGTC ATCCACAAGTGCGAGGACTGTGGGAAGGAGTTCACGCACACGGGGAACTTCAAGCGGCAC ATCCGCATCCACACGGGGGAGAAGCCCTTCTCGTGCCGGGAGTGCAGCAAGGCCTTTTCC GACCCGGCCGCGTGCAAGGCCCATGAGAAGACGCACAGCCCTCTGAAGCCCTACGGCTGC GAGGAGTGCGGGAAGAGCTACCGCCTCATCAGCCTGCTGAACCTGCACAAGAAGCGGCAC TCGGGCGAGGCGCGCTACCGCTGCGAGGACTGCGGCAAGCTCTTCACCACCTCGGGCAAC CTCAAGCGCCACCAGCTGGTGCACAGCGGCGAGAAGCCCTACCAGTGCGACTACTGCGGC CGCTCCTTCTCCGACCCCACTTCCAAGATGCGCCACCTGGAGACCCACGACACGGACAAG GAGCACAAGTGCCCACACTGCGACAAGAAGTTCAACCAGGTAGGGAACCTGAAGGCCCAC CTGAAGATCCACATCGCTGACGGGCCCCTCAAGTGCCGAGAGTGTGGGAAGCAGTTCACC ACCTCAGGGAACCTGAAGCGGCACCTTCGGATCCACAGCGGGGAGAAGCCCTACGTGTGC ATCCACTGCCAGCGACAGTTTGCAGACCCCGGCGCTCTGCAGCGGCACGTCCGCATTCAC ACAGGTGAGAAGCCATGCCAGTGTGTGATGTGCGGTAAGGCCTTCACCCAGGCCAGCTCC CTCATCGCCCACGTGCGCCAGCACACCGGGGAGAAGCCCTACGTCTGCGAGCGCTGCGGC AAGAGATTCGTCCAGTCCAGCCAGTTGGCCAATCATATTCGCCACCACGACAACATCCGC CCACACAAGTGCAGCGTGTGCAGCAAGGCCTTCGTGAACGTGGGGGACCTGTCCAAGCAC ATCATCATTCACACTGGAGAGAAGCCTTACCTGTGTGATAAGTGTGGGCGTGGCTTCAAC CGGGTAGACAACCTGCGCTCCCACGTGAAGACCGTGCACCAGGGCAAGGCAGGCATCAAG ATCCTGGAGCCCGAGGAGGGCAGTGAGGTCAGCGTGGTCACTGTGGATGACATGGTCACG CTGGCTACCGAGGCACTGGCAGCGACAGCCGTCACTCAGCTCACAGTGGTGCCGGTGGGA GCTGCAGTGACAGCCGATGAGACGGAAGTCCTGAAGGCCGAGATCAGCAAAGCTGTGAAG CAAGTGCAGGAAGAAGACCCCAACACTCACATCCTCTACGCCTGTGACTCCTGTGGGGAC AAGTTTCTGGATGCCAACAGCCTGGCTCAGCATGTGCGAATCCACACAGCCCAGGCACTG GTCATGTTCCAGACAGACGCGGACTTCTATCAGCAGTATGGGCCAGGTGGCACGTGGCCT GCCGGGCAGGTGCTGCAGGCTGGGGAGCTGGTCTTCCGCCCTCGCGACGGGGCTGAGGGC CAGCCCGCACTGGCAGAGACCTCCCCTACAGCTCCTGAATGTCCCCCGCCTGCCGAGGTT TAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGC TGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCA ATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGG AGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGT AAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGC CCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTT CCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAA TTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCT TTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGA CGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTG GAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTG TTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCC CTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCT TGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAA GTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATG GCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAA GCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGAT GATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCG CGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATC ATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGAC CGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGG GCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTC TATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAG CGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGG GGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAA GGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCG ACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCC TGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGC CTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTC GGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCG CTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCC ACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGA GTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGC TCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAAC CACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGG ATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTC ACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATA GTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAA AATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGG TATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGC CATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTA AGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTA CTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAA ATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGT CCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGG GTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGA AAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAA ATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGAC GCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTT TTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTC AT
 more Linker info
more Linker info
{kind=link}