


-
SpecieshumanProduct IDFXC01339Cloning SiteSgfI-PmeIGeneKIBB3849SymbolPCDHGB5
Alias : PCDH-GAMMA-B5Descriptionprotocadherin gamma subfamily B, 5, transcript variant 1Original Clone IDaj00333 Length: 2769 bp
Length: 2769 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 923 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)

Entry Exp ID% symbol CCDS75339.1 0 100.0 PCDHGB5 CCDS75340.1 0 100.0 PCDHGB5 CCDS54928.1 0 85.6 PCDHGB4 CCDS54929.1 0 74.2 PCDHGB6 CCDS54923.1 0 74.9 PCDHGB1
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]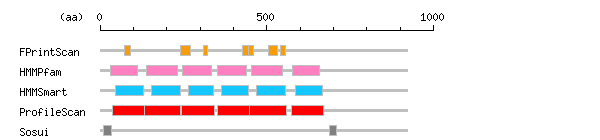 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR002126 73 92 PR00205 Cadherin IPR002126 242 271 PR00205 Cadherin IPR002126 310 322 PR00205 Cadherin IPR002126 427 446 PR00205 Cadherin IPR002126 446 459 PR00205 Cadherin IPR002126 506 532 PR00205 Cadherin IPR002126 540 557 PR00205 Cadherin HMMPfam IPR013164 31 112 PF08266 Cadherin IPR002126 139 233 PF00028 Cadherin IPR002126 247 333 PF00028 Cadherin IPR002126 353 438 PF00028 Cadherin IPR002126 453 548 PF00028 Cadherin IPR002126 578 657 PF00028 Cadherin HMMSmart IPR002126 46 131 SM00112 Cadherin IPR002126 155 240 SM00112 Cadherin IPR002126 264 341 SM00112 Cadherin IPR002126 365 446 SM00112 Cadherin IPR002126 470 556 SM00112 Cadherin IPR002126 587 668 SM00112 Cadherin ProfileScan IPR002126 37 133 PS50268 Cadherin IPR002126 134 242 PS50268 Cadherin IPR002126 243 343 PS50268 Cadherin IPR002126 352 448 PS50268 Cadherin IPR002126 449 558 PS50268 Cadherin IPR002126 574 671 PS50268 Cadherin
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 11 AERLPVLFLFLLSLFCPALCEQI 33 PRIMARY 23 2 687 YLVVALALISVLFLLAVILAVAL 709 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_061748 923 606302 100.0 100.0 NP_115270 818 606302 100.0 86.6 NP_003727 923 603058 85.6 100.0 NP_061749 930 606303 74.2 100.0 NP_061745 927 606299 74.9 98.4 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KB3849 Download>KIBB3849 2769 bp ATGGGGAGCGGCGCCGGGGAGCTGGGCCGGGCTGAGAGGCTGCCAGTGCTCTTTCTCTTC CTGCTGTCTTTGTTCTGCCCGGCGCTCTGTGAGCAGATCCGCTACAGGATTCCCGAGGAA ATGCCCAAGGGCTCCGTAGTGGGGAACCTCGCCACGGACCTGGGGTTCAGCGTCCAGGAG TTACCGACTCGAAAACTGCGCGTCAGTTCGGAGAAGCCTTACTTCACCGTGAGCGCAGAG AGCGGGGAGTTGCTTGTGAGCAGCAGGCTAGACAGGGAGGAGATATGCGGGAAGAAGCCA GCTTGTGCTCTGGAATTTGAGGCTGTTGCTGAAAATCCACTGAACTTTTATCACGTGAAT GTGGAGATCGAGGACATTAATGACCACACGCCAAAATTCACGCAAAATTCCTTTGAGCTG CAAATAAGTGAGTCTGCACAGCCTGGCACAAGATTTATACTAGAAGTAGCAGAAGATGCA GATATTGGCTTAAACTCTCTGCAGAAGTATAAACTCTCTCTTAACCCAAGTTTCTCATTA ATAATTAAGGAGAAACAGGATGGTAGTAAATACCCGGAACTGGCACTGGAGAAAACCTTA GACCGGGAACAACAGAGTTACCATCGTTTAGTCCTGACTGCCTTGGACGGTGGACATCCA CCCCTAAGCGGCACCACTGAGCTCCGGATCCAGGTAACCGACGCCAATGATAATCCCCCG GTATTCAACCGAGACGTGTACAGAGTCAGCCTTCGGGAAAACGTGCCACCAGGCACCACT GTGTTGCAAGTGTCAGCCACTGACCAAGACGAGGGCATCAACTCAGAAATTACTTATTCC TTCTACAGAACCGGGCAAATCTTTAGTCTGAATTCAAAGAGCGGAGAAATTACCACTCAA AAGAAACTGGATTTTGAAGAGACCAAGGAATATTCAATGGTTGTAGAAGGGAGGGATGGT GGTGGACTGGTTGCACAATGTACAGTTGAAATTAATATTCAAGATGAAAATGACAATAGC CCAGAAGTTACATTCCATTCTCTACTTGAAATGATTCTGGAAAACGCGGTGCCTGGAACA CTAATTGCTTTGATCAAAATACATGACCAAGATTCTGGGGAAAATGGGGAGGTTAATTGT CAATTACAAGGCGAAGTCCCTTTTAAGATTATCTCTTCATCCAAAAATTCGTATAAGTTG GTAACAGATGGAACCCTAGACCGAGAGCAAACCCCGGAGTACAATGTCACCATCACAGCC ACAGACAGGGGCAAGCCGCCCCTCTCCTCCAGCATAAGCGTCATCCTACATATCAGAGAC GTCAACGATAACGCTCCGGTTTTCCACCAGGCGTCCTACTTAGTCAGTGTACCCGAAAAC AACCCTCCTGGGGCCTCCATCGCGCAAGTCTGCGCCTCGGACCTGGACTTGGGGTTGAAC GGCCAAGTCTCCTACTCTATCATGGCCAGCGACCTAGAGCCTCTGGCACTGGCCTCTTAC GTGTCCATGAGCGCGCAAAGTGGGGTGGTGTTCGCGCAGCGCGCCTTTGACTACGAGCAG CTGCGCACCTTCGAACTCACACTACAGGCCCGCGACCAGGGCTCGCCTGCGCTCAGCGCA AACGTGAGCCTGCGCGTGTTGGTGGGCGACCGAAACGACAACGCACCGCGGGTGCTGTAC CCCGCGCTGGGTCCCGACGGCTCTGCGCTCTTCGATATGGTGCCGCGCGCTGCAGAGCCC GGCTACCTGGTGACCAAGGTAGTGGCCGTGGACGCAGACTCAGGACACAACGCCTGGCTG TCCTACCACGTGCTGCAGGCTAGCGAGCCCGGGCTCTTCAGCCTGGGGCTGCGCACAGGA GAGGTGCGCACAGCGCGTGCCTTGGGCGACAGGGACGCGGCCCGCCAGCGCCTGCTGGTT GCTGTGCGTGATGGTGGACAGCCGCCACTCTCCGCCACCGCCACGCTGCACTTGGTCTTT GCTGACAGCTTGCAGGAGGTGCTGCCGGATATCACTGACCGCCCTGTACCCTCTGACCCC CAGGCTGAGCTGCAGTTTTACCTAGTGGTGGCCTTGGCCTTGATCTCAGTGCTCTTCCTC CTGGCCGTGATTCTGGCCGTTGCCTTGCGCCTGCGACGCTCCTCCAGCCCTGCCGCCTGG AGCTGCTTCCAACCTGGTCTCTGTGTCAAGTCTGGACCTGTGGTTCCCCCCAACTACAGT CAGGGGACTTTGCCTTATTCCTACAACCTATGTGTTGCACATACAGGAAAGACGGAGTTT AATTTCCTAAAATGTAGTGAGCAATTGAGTTCAGGACAAGACATACTTTGTGGTGATTCA TCTGGGGCCTTATTTCCACTTTGTAATTCCAGCGAGTCGACTTCCCATCCTGAGTTGCAA GCCCCGCCCAACACGGACTGGCGTTTCTCTCAGGCCCAGAGACCCGGCACCAGCGGCTCC CAAAATGGCGATGACACCGGCACCTGGCCCAACAACCAGTTTGACACAGAGATGCTGCAA GCCATGATCTTGGCGTCCGCCAGTGAAGCTGCTGATGGGAGCTCCACCCTGGGAGGGGGT GCCGGCACCATGGGATTGAGCGCCCGCTACGGACCCCAGTTCACCCTGCAGCACGTGCCC GACTACCGCCAGAATGTCTACATCCCAGGCAGCAATGCCACACTGACCAACGCAGCTGGC AAGCGGGATGGCAAGGCCCCAGCAGGTGGCAATGGCAACAAGAAGAAGTCGGGCAAGAAG GAGAAGAAG
Cloned ORF protein sequence for pF1KB3849 Download>KIBB3849 923 aa MGSGAGELGRAERLPVLFLFLLSLFCPALCEQIRYRIPEEMPKGSVVGNLATDLGFSVQE LPTRKLRVSSEKPYFTVSAESGELLVSSRLDREEICGKKPACALEFEAVAENPLNFYHVN VEIEDINDHTPKFTQNSFELQISESAQPGTRFILEVAEDADIGLNSLQKYKLSLNPSFSL IIKEKQDGSKYPELALEKTLDREQQSYHRLVLTALDGGHPPLSGTTELRIQVTDANDNPP VFNRDVYRVSLRENVPPGTTVLQVSATDQDEGINSEITYSFYRTGQIFSLNSKSGEITTQ KKLDFEETKEYSMVVEGRDGGGLVAQCTVEINIQDENDNSPEVTFHSLLEMILENAVPGT LIALIKIHDQDSGENGEVNCQLQGEVPFKIISSSKNSYKLVTDGTLDREQTPEYNVTITA TDRGKPPLSSSISVILHIRDVNDNAPVFHQASYLVSVPENNPPGASIAQVCASDLDLGLN GQVSYSIMASDLEPLALASYVSMSAQSGVVFAQRAFDYEQLRTFELTLQARDQGSPALSA NVSLRVLVGDRNDNAPRVLYPALGPDGSALFDMVPRAAEPGYLVTKVVAVDADSGHNAWL SYHVLQASEPGLFSLGLRTGEVRTARALGDRDAARQRLLVAVRDGGQPPLSATATLHLVF ADSLQEVLPDITDRPVPSDPQAELQFYLVVALALISVLFLLAVILAVALRLRRSSSPAAW SCFQPGLCVKSGPVVPPNYSQGTLPYSYNLCVAHTGKTEFNFLKCSEQLSSGQDILCGDS SGALFPLCNSSESTSHPELQAPPNTDWRFSQAQRPGTSGSQNGDDTGTWPNNQFDTEMLQ AMILASASEAADGSSTLGGGAGTMGLSARYGPQFTLQHVPDYRQNVYIPGSNATLTNAAG KRDGKAPAGGNGNKKKSGKKEKK
Nucleotide Sequence (with vector) for pF1KB3849 Download>pF1KB3849 5882 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGGGAGCGGC GCCGGGGAGCTGGGCCGGGCTGAGAGGCTGCCAGTGCTCTTTCTCTTCCTGCTGTCTTTG TTCTGCCCGGCGCTCTGTGAGCAGATCCGCTACAGGATTCCCGAGGAAATGCCCAAGGGC TCCGTAGTGGGGAACCTCGCCACGGACCTGGGGTTCAGCGTCCAGGAGTTACCGACTCGA AAACTGCGCGTCAGTTCGGAGAAGCCTTACTTCACCGTGAGCGCAGAGAGCGGGGAGTTG CTTGTGAGCAGCAGGCTAGACAGGGAGGAGATATGCGGGAAGAAGCCAGCTTGTGCTCTG GAATTTGAGGCTGTTGCTGAAAATCCACTGAACTTTTATCACGTGAATGTGGAGATCGAG GACATTAATGACCACACGCCAAAATTCACGCAAAATTCCTTTGAGCTGCAAATAAGTGAG TCTGCACAGCCTGGCACAAGATTTATACTAGAAGTAGCAGAAGATGCAGATATTGGCTTA AACTCTCTGCAGAAGTATAAACTCTCTCTTAACCCAAGTTTCTCATTAATAATTAAGGAG AAACAGGATGGTAGTAAATACCCGGAACTGGCACTGGAGAAAACCTTAGACCGGGAACAA CAGAGTTACCATCGTTTAGTCCTGACTGCCTTGGACGGTGGACATCCACCCCTAAGCGGC ACCACTGAGCTCCGGATCCAGGTAACCGACGCCAATGATAATCCCCCGGTATTCAACCGA GACGTGTACAGAGTCAGCCTTCGGGAAAACGTGCCACCAGGCACCACTGTGTTGCAAGTG TCAGCCACTGACCAAGACGAGGGCATCAACTCAGAAATTACTTATTCCTTCTACAGAACC GGGCAAATCTTTAGTCTGAATTCAAAGAGCGGAGAAATTACCACTCAAAAGAAACTGGAT TTTGAAGAGACCAAGGAATATTCAATGGTTGTAGAAGGGAGGGATGGTGGTGGACTGGTT GCACAATGTACAGTTGAAATTAATATTCAAGATGAAAATGACAATAGCCCAGAAGTTACA TTCCATTCTCTACTTGAAATGATTCTGGAAAACGCGGTGCCTGGAACACTAATTGCTTTG ATCAAAATACATGACCAAGATTCTGGGGAAAATGGGGAGGTTAATTGTCAATTACAAGGC GAAGTCCCTTTTAAGATTATCTCTTCATCCAAAAATTCGTATAAGTTGGTAACAGATGGA ACCCTAGACCGAGAGCAAACCCCGGAGTACAATGTCACCATCACAGCCACAGACAGGGGC AAGCCGCCCCTCTCCTCCAGCATAAGCGTCATCCTACATATCAGAGACGTCAACGATAAC GCTCCGGTTTTCCACCAGGCGTCCTACTTAGTCAGTGTACCCGAAAACAACCCTCCTGGG GCCTCCATCGCGCAAGTCTGCGCCTCGGACCTGGACTTGGGGTTGAACGGCCAAGTCTCC TACTCTATCATGGCCAGCGACCTAGAGCCTCTGGCACTGGCCTCTTACGTGTCCATGAGC GCGCAAAGTGGGGTGGTGTTCGCGCAGCGCGCCTTTGACTACGAGCAGCTGCGCACCTTC GAACTCACACTACAGGCCCGCGACCAGGGCTCGCCTGCGCTCAGCGCAAACGTGAGCCTG CGCGTGTTGGTGGGCGACCGAAACGACAACGCACCGCGGGTGCTGTACCCCGCGCTGGGT CCCGACGGCTCTGCGCTCTTCGATATGGTGCCGCGCGCTGCAGAGCCCGGCTACCTGGTG ACCAAGGTAGTGGCCGTGGACGCAGACTCAGGACACAACGCCTGGCTGTCCTACCACGTG CTGCAGGCTAGCGAGCCCGGGCTCTTCAGCCTGGGGCTGCGCACAGGAGAGGTGCGCACA GCGCGTGCCTTGGGCGACAGGGACGCGGCCCGCCAGCGCCTGCTGGTTGCTGTGCGTGAT GGTGGACAGCCGCCACTCTCCGCCACCGCCACGCTGCACTTGGTCTTTGCTGACAGCTTG CAGGAGGTGCTGCCGGATATCACTGACCGCCCTGTACCCTCTGACCCCCAGGCTGAGCTG CAGTTTTACCTAGTGGTGGCCTTGGCCTTGATCTCAGTGCTCTTCCTCCTGGCCGTGATT CTGGCCGTTGCCTTGCGCCTGCGACGCTCCTCCAGCCCTGCCGCCTGGAGCTGCTTCCAA CCTGGTCTCTGTGTCAAGTCTGGACCTGTGGTTCCCCCCAACTACAGTCAGGGGACTTTG CCTTATTCCTACAACCTATGTGTTGCACATACAGGAAAGACGGAGTTTAATTTCCTAAAA TGTAGTGAGCAATTGAGTTCAGGACAAGACATACTTTGTGGTGATTCATCTGGGGCCTTA TTTCCACTTTGTAATTCCAGCGAGTCGACTTCCCATCCTGAGTTGCAAGCCCCGCCCAAC ACGGACTGGCGTTTCTCTCAGGCCCAGAGACCCGGCACCAGCGGCTCCCAAAATGGCGAT GACACCGGCACCTGGCCCAACAACCAGTTTGACACAGAGATGCTGCAAGCCATGATCTTG GCGTCCGCCAGTGAAGCTGCTGATGGGAGCTCCACCCTGGGAGGGGGTGCCGGCACCATG GGATTGAGCGCCCGCTACGGACCCCAGTTCACCCTGCAGCACGTGCCCGACTACCGCCAG AATGTCTACATCCCAGGCAGCAATGCCACACTGACCAACGCAGCTGGCAAGCGGGATGGC AAGGCCCCAGCAGGTGGCAATGGCAACAAGAAGAAGTCGGGCAAGAAGGAGAAGAAGGTT TAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGC TGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCA ATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGG AGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGT AAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGC CCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTT CCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAA TTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCT TTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGA CGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTG GAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTG TTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCC CTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCT TGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAA GTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATG GCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAA GCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGAT GATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCG CGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATC ATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGAC CGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGG GCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTC TATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAG CGACGCCCAACCGGACTATAAAAGGATCTAGGTGAAGATCCTTTTTGATAATCTCATGAC CAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAA AGGATCTTCTTGAAATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACC ACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGT AACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGG CCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACC AGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTT ACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGA GCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCT TCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCG CACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCA CCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAA CGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATGTT CTTTCCTGCGTTATCCCCTGATTCTGTGGATAACCGTATTACCGCCTTTGAGTGAGCTGA TACCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAA AATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGG TATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGC CATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTA AGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTA CTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAA ATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGT CCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGG GTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGA AAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAA ATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGAC GCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTT TTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTC AT
 more Linker info
more Linker info
{kind=link}