


-
SpecieshumanProduct IDFXC10755Cloning SiteSgfI-PmeIGeneKIEE0084SymbolKCNQ3
Alias : BFNC2, EBN2, KV7.3Descriptionpotassium channel, voltage gated KQT-like subfamily Q, member 3, transcript variant 1Original Clone IDoc00784 Length: 2616 bp
Length: 2616 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 872 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
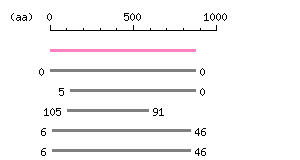
Entry Exp ID% symbol CCDS34943.1 0 100.0 KCNQ3 CCDS56554.1 1.9e-207 99.7 KCNQ3 CCDS7736.1 8.7e-48 43.8 KCNQ1 CCDS4976.1 2.8e-39 43.5 KCNQ5 CCDS55035.1 7.2e-36 40.0 KCNQ5
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR003948 83 96 PR01462 Potassium channel IPR003948 134 145 PR01462 Potassium channel IPR003091 158 181 PR00169 Voltage-dependent potassium channel IPR003937 166 185 PR01459 Potassium channel IPR003937 186 205 PR01459 Potassium channel IPR003948 209 218 PR01462 Potassium channel IPR003091 231 257 PR00169 Voltage-dependent potassium channel IPR003937 247 266 PR01459 Potassium channel IPR003091 260 283 PR00169 Voltage-dependent potassium channel IPR003948 286 299 PR01462 Potassium channel IPR003091 300 322 PR00169 Voltage-dependent potassium channel IPR003091 329 355 PR00169 Voltage-dependent potassium channel IPR003948 463 475 PR01462 Potassium channel IPR003948 577 594 PR01462 Potassium channel IPR003948 682 701 PR01462 Potassium channel IPR003948 729 745 PR01462 Potassium channel IPR003948 755 770 PR01462 Potassium channel HMMPfam IPR005821 159 350 PF00520 Ion transport IPR013821 449 659 PF03520 Potassium channel IPR020969 770 866 PF11956 Ankyrin-G binding site
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 123 LLYHALVFLIVLGCLILAVLTTF 145 PRIMARY 23 2 156 LLLLETFAIFIFGAEFALRIWAA 178 SECONDARY 23 3 197 PLCMLDIFVLIASVPVVAVGNQG 219 PRIMARY 23 4 263 TAWYIGFLTLILSSFLVYLVEKD 285 PRIMARY 23 5 300 FETYADALWWGLITLATIGYGDK 322 SECONDARY 23 6 333 AATFSLIGVSFFALPAGILGSGL 355 SECONDARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_004510 872 121201,602232 100.0 100.0 NP_001191753 752 121201,602232 99.7 85.7 XP_011515328 752 121201,602232 100.0 85.2 XP_016868889 798 121201,602232 100.0 85.2 NP_062816 932 607357 43.5 95.3 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KE0084 Download>KIEE0084 2616 bp ATGGGGCTCAAGGCGCGCAGGGCGGCGGGGGCGGCTGGCGGCGGCGGCGACGGGGGCGGC GGAGGCGGCGGGGCGGCTAACCCAGCCGGAGGGGACGCGGCGGCGGCCGGCGACGAGGAG CGGAAAGTGGGGCTGGCGCCCGGCGACGTGGAGCAAGTCACCTTGGCGCTCGGGGCCGGA GCCGACAAAGACGGGACCCTGCTGCTGGAGGGCGGCGGCCGCGACGAGGGGCAGCGGAGG ACCCCGCAGGGCATCGGGCTCCTGGCCAAGACCCCGCTGAGCCGCCCAGTCAAGAGAAAC AACGCCAAGTACCGGCGCATCCAAACTTTGATCTACGACGCCCTGGAGAGACCGCGGGGC TGGGCGCTGCTTTACCACGCGTTGGTGTTCCTGATTGTCCTGGGGTGCTTGATTCTGGCT GTCCTGACCACATTCAAGGAGTATGAGACTGTCTCGGGAGACTGGCTTCTGTTACTGGAG ACATTTGCTATTTTCATCTTTGGAGCCGAGTTTGCTTTGAGGATCTGGGCTGCTGGATGT TGCTGCCGATACAAAGGCTGGCGGGGCCGACTGAAGTTTGCCAGGAAGCCCCTGTGCATG TTGGACATCTTTGTGCTGATTGCCTCTGTGCCAGTGGTTGCTGTGGGAAACCAAGGCAAT GTTCTGGCCACCTCCCTGCGAAGCCTGCGCTTCCTGCAGATCCTGCGCATGCTGCGGATG GACCGGAGAGGTGGCACCTGGAAGCTTCTGGGCTCAGCCATCTGTGCCCACAGCAAAGAA CTCATCACGGCCTGGTACATCGGTTTCCTGACACTCATCCTTTCTTCATTTCTTGTCTAC CTGGTTGAGAAAGACGTCCCAGAGGTGGATGCACAAGGAGAGGAGATGAAAGAGGAGTTT GAGACCTATGCAGATGCCCTGTGGTGGGGCCTGATCACACTGGCCACCATTGGCTATGGA GACAAGACACCCAAAACGTGGGAAGGCCGTCTGATTGCCGCCACCTTTTCCTTAATTGGC GTCTCCTTTTTTGCCCTTCCAGCGGGCATCCTGGGGTCCGGGCTGGCCCTCAAGGTGCAG GAGCAACACCGTCAGAAGCACTTTGAGAAAAGGAGGAAGCCAGCTGCTGAGCTCATTCAG GCTGCCTGGAGGTATTATGCTACCAACCCCAACAGGATTGACCTGGTGGCGACATGGAGA TTTTATGAATCAGTCGTCTCTTTTCCTTTCTTCAGGAAAGAACAGCTGGAGGCAGCATCC AGCCAAAAGCTGGGTCTCTTGGATCGGGTTCGCCTTTCTAATCCTCGTGGTAGCAATACT AAAGGAAAGCTATTTACCCCTCTGAATGTAGATGCCATAGAAGAAAGTCCTTCTAAAGAA CCAAAGCCTGTTGGCTTAAACAATAAAGAGCGTTTCCGCACGGCCTTCCGCATGAAAGCC TACGCTTTCTGGCAGAGTTCTGAAGATGCCGGGACAGGTGACCCCATGGCGGAAGACAGG GGCTATGGGAATGACTTCCCCATCGAAGACATGATCCCCACCCTGAAGGCCGCCATCCGA GCCGTCAGAATTCTACAATTCCGTCTCTATAAAAAAAAATTCAAGGAGACTTTGAGGCCT TACGATGTGAAGGATGTGATTGAGCAGTATTCTGCCGGGCATCTCGACATGCTTTCCAGG ATAAAGTACCTTCAGACGAGAATAGATATGATTTTCACCCCTGGACCTCCCTCCACGCCA AAACACAAGAAGTCTCAGAAAGGGTCAGCATTCACCTTCCCATCCCAGCAATCTCCCAGG AATGAACCATATGTAGCCAGACCATCCACATCAGAAATCGAAGACCAAAGCATGATGGGG AAGTTTGTAAAAGTTGAAAGACAGGTTCAGGACATGGGGAAGAAGCTGGACTTCCTCGTG GATATGCACATGCAACACATGGAACGGTTGCAGGTGCAGGTCACGGAGTATTACCCAACC AAGGGCACCTCCTCGCCAGCTGAAGCAGAGAAGAAGGAGGACAACAGGTATTCCGATTTG AAAACCATCATCTGCAACTATTCTGAGACAGGCCCCCCGGAACCACCCTACAGCTTCCAC CAGGTGACCATTGACAAAGTCAGCCCCTATGGGTTTTTTGCACATGACCCTGTGAACCTG CCCCGAGGGGGACCCAGTTCTGGAAAGGTTCAGGCAACTCCTCCTTCCTCAGCAACAACG TATGTGGAGAGGCCCACGGTCCTGCCTATCTTGACTCTTCTCGACTCCCGAGTGAGCTGC CACTCCCAGGCTGACCTGCAGGGCCCCTACTCGGACCGAATCTCCCCCCGGCAGAGACGT AGCATCACGCGAGACAGTGACACACCTCTGTCCCTGATGTCGGTCAACCACGAGGAGCTG GAGAGGTCTCCAAGTGGCTTCAGCATCTCCCAGGACAGAGATGATTATGTGTTCGGCCCC AATGGGGGGTCGAGCTGGATGAGGGAGAAGCGGTACCTCGCCGAGGGTGAGACGGACACA GACACGGACCCCTTCACGCCCAGCGGCTCCATGCCTCTGTCGTCCACAGGGGATGGGATT TCTGATTCAGTATGGACCCCTTCCAATAAGCCCATT
Cloned ORF protein sequence for pF1KE0084 Download>KIEE0084 872 aa MGLKARRAAGAAGGGGDGGGGGGGAANPAGGDAAAAGDEERKVGLAPGDVEQVTLALGAG ADKDGTLLLEGGGRDEGQRRTPQGIGLLAKTPLSRPVKRNNAKYRRIQTLIYDALERPRG WALLYHALVFLIVLGCLILAVLTTFKEYETVSGDWLLLLETFAIFIFGAEFALRIWAAGC CCRYKGWRGRLKFARKPLCMLDIFVLIASVPVVAVGNQGNVLATSLRSLRFLQILRMLRM DRRGGTWKLLGSAICAHSKELITAWYIGFLTLILSSFLVYLVEKDVPEVDAQGEEMKEEF ETYADALWWGLITLATIGYGDKTPKTWEGRLIAATFSLIGVSFFALPAGILGSGLALKVQ EQHRQKHFEKRRKPAAELIQAAWRYYATNPNRIDLVATWRFYESVVSFPFFRKEQLEAAS SQKLGLLDRVRLSNPRGSNTKGKLFTPLNVDAIEESPSKEPKPVGLNNKERFRTAFRMKA YAFWQSSEDAGTGDPMAEDRGYGNDFPIEDMIPTLKAAIRAVRILQFRLYKKKFKETLRP YDVKDVIEQYSAGHLDMLSRIKYLQTRIDMIFTPGPPSTPKHKKSQKGSAFTFPSQQSPR NEPYVARPSTSEIEDQSMMGKFVKVERQVQDMGKKLDFLVDMHMQHMERLQVQVTEYYPT KGTSSPAEAEKKEDNRYSDLKTIICNYSETGPPEPPYSFHQVTIDKVSPYGFFAHDPVNL PRGGPSSGKVQATPPSSATTYVERPTVLPILTLLDSRVSCHSQADLQGPYSDRISPRQRR SITRDSDTPLSLMSVNHEELERSPSGFSISQDRDDYVFGPNGGSSWMREKRYLAEGETDT DTDPFTPSGSMPLSSTGDGISDSVWTPSNKPI
Nucleotide Sequence (with vector) for pF1KE0084 Download>pF1KE0084 5729 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGGGCTCAAG GCGCGCAGGGCGGCGGGGGCGGCTGGCGGCGGCGGCGACGGGGGCGGCGGAGGCGGCGGG GCGGCTAACCCAGCCGGAGGGGACGCGGCGGCGGCCGGCGACGAGGAGCGGAAAGTGGGG CTGGCGCCCGGCGACGTGGAGCAAGTCACCTTGGCGCTCGGGGCCGGAGCCGACAAAGAC GGGACCCTGCTGCTGGAGGGCGGCGGCCGCGACGAGGGGCAGCGGAGGACCCCGCAGGGC ATCGGGCTCCTGGCCAAGACCCCGCTGAGCCGCCCAGTCAAGAGAAACAACGCCAAGTAC CGGCGCATCCAAACTTTGATCTACGACGCCCTGGAGAGACCGCGGGGCTGGGCGCTGCTT TACCACGCGTTGGTGTTCCTGATTGTCCTGGGGTGCTTGATTCTGGCTGTCCTGACCACA TTCAAGGAGTATGAGACTGTCTCGGGAGACTGGCTTCTGTTACTGGAGACATTTGCTATT TTCATCTTTGGAGCCGAGTTTGCTTTGAGGATCTGGGCTGCTGGATGTTGCTGCCGATAC AAAGGCTGGCGGGGCCGACTGAAGTTTGCCAGGAAGCCCCTGTGCATGTTGGACATCTTT GTGCTGATTGCCTCTGTGCCAGTGGTTGCTGTGGGAAACCAAGGCAATGTTCTGGCCACC TCCCTGCGAAGCCTGCGCTTCCTGCAGATCCTGCGCATGCTGCGGATGGACCGGAGAGGT GGCACCTGGAAGCTTCTGGGCTCAGCCATCTGTGCCCACAGCAAAGAACTCATCACGGCC TGGTACATCGGTTTCCTGACACTCATCCTTTCTTCATTTCTTGTCTACCTGGTTGAGAAA GACGTCCCAGAGGTGGATGCACAAGGAGAGGAGATGAAAGAGGAGTTTGAGACCTATGCA GATGCCCTGTGGTGGGGCCTGATCACACTGGCCACCATTGGCTATGGAGACAAGACACCC AAAACGTGGGAAGGCCGTCTGATTGCCGCCACCTTTTCCTTAATTGGCGTCTCCTTTTTT GCCCTTCCAGCGGGCATCCTGGGGTCCGGGCTGGCCCTCAAGGTGCAGGAGCAACACCGT CAGAAGCACTTTGAGAAAAGGAGGAAGCCAGCTGCTGAGCTCATTCAGGCTGCCTGGAGG TATTATGCTACCAACCCCAACAGGATTGACCTGGTGGCGACATGGAGATTTTATGAATCA GTCGTCTCTTTTCCTTTCTTCAGGAAAGAACAGCTGGAGGCAGCATCCAGCCAAAAGCTG GGTCTCTTGGATCGGGTTCGCCTTTCTAATCCTCGTGGTAGCAATACTAAAGGAAAGCTA TTTACCCCTCTGAATGTAGATGCCATAGAAGAAAGTCCTTCTAAAGAACCAAAGCCTGTT GGCTTAAACAATAAAGAGCGTTTCCGCACGGCCTTCCGCATGAAAGCCTACGCTTTCTGG CAGAGTTCTGAAGATGCCGGGACAGGTGACCCCATGGCGGAAGACAGGGGCTATGGGAAT GACTTCCCCATCGAAGACATGATCCCCACCCTGAAGGCCGCCATCCGAGCCGTCAGAATT CTACAATTCCGTCTCTATAAAAAAAAATTCAAGGAGACTTTGAGGCCTTACGATGTGAAG GATGTGATTGAGCAGTATTCTGCCGGGCATCTCGACATGCTTTCCAGGATAAAGTACCTT CAGACGAGAATAGATATGATTTTCACCCCTGGACCTCCCTCCACGCCAAAACACAAGAAG TCTCAGAAAGGGTCAGCATTCACCTTCCCATCCCAGCAATCTCCCAGGAATGAACCATAT GTAGCCAGACCATCCACATCAGAAATCGAAGACCAAAGCATGATGGGGAAGTTTGTAAAA GTTGAAAGACAGGTTCAGGACATGGGGAAGAAGCTGGACTTCCTCGTGGATATGCACATG CAACACATGGAACGGTTGCAGGTGCAGGTCACGGAGTATTACCCAACCAAGGGCACCTCC TCGCCAGCTGAAGCAGAGAAGAAGGAGGACAACAGGTATTCCGATTTGAAAACCATCATC TGCAACTATTCTGAGACAGGCCCCCCGGAACCACCCTACAGCTTCCACCAGGTGACCATT GACAAAGTCAGCCCCTATGGGTTTTTTGCACATGACCCTGTGAACCTGCCCCGAGGGGGA CCCAGTTCTGGAAAGGTTCAGGCAACTCCTCCTTCCTCAGCAACAACGTATGTGGAGAGG CCCACGGTCCTGCCTATCTTGACTCTTCTCGACTCCCGAGTGAGCTGCCACTCCCAGGCT GACCTGCAGGGCCCCTACTCGGACCGAATCTCCCCCCGGCAGAGACGTAGCATCACGCGA GACAGTGACACACCTCTGTCCCTGATGTCGGTCAACCACGAGGAGCTGGAGAGGTCTCCA AGTGGCTTCAGCATCTCCCAGGACAGAGATGATTATGTGTTCGGCCCCAATGGGGGGTCG AGCTGGATGAGGGAGAAGCGGTACCTCGCCGAGGGTGAGACGGACACAGACACGGACCCC TTCACGCCCAGCGGCTCCATGCCTCTGTCGTCCACAGGGGATGGGATTTCTGATTCAGTA TGGACCCCTTCCAATAAGCCCATTGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCT CTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGC TGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACG GGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAA AACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGC GCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCG TTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTG CTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGG AAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGA TCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTG CACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAG ACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTT TTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTA TCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCG GGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTT GCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGAT CCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGG ATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCA GCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACT CATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATC GACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGAT ATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCC GCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGA CTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGC GGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGG CCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCG CCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGG ACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGAC CCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCA TAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGT GCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTC CAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAG AGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACAC TAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGT TGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAA GCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGG GTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAA AAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCC CTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAAT GTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATT GCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTG AACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCC TCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCG AGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAA TTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAA ACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGC ATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGT CGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGC AACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGC AGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTC TAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}