Nucleotide Sequence (with vector) for pF1KE1042
Download
>pF1KE1042 4616 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGCTGCAGCT
AGCGTGACCCCCCCTGGCTCCCTGGAGTTGCTACAGCCCGGCTTCTCCAAGACCCTCCTG
GGGACCAAGCTGGAAGCCAAGTACCTGTGCTCCGCCTGCAGAAACGTCCTCCGCAGGCCC
TTCCAGGCGCAGTGTGGCCACCGGTACTGCTCCTTCTGCCTGGCCAGCATCCTCAGCTCT
GGGCCTCAGAACTGTGCTGCCTGTGTTCACGAGGGCATATATGAAGAAGGCATTTCTATT
TTAGAAAGCAGTTCGGCCTTCCCAGATAATGCTGCCCGCAGGGAGGTGGAGAGCCTGCCG
GCCGTCTGTCCCAGTGATGGATGCACCTGGAAGGGGACCCTGAAAGAATACGAGAGCTGC
CACGAAGGCCGCTGCCCGCTCATGCTGACCGAATGTCCCGCGTGCAAAGGCCTGGTCCGC
CTTGGTGAAAAGGAGCGCCACCTGGAGCACGAGTGCCCGGAGAGAAGCCTGAGCTGCCGG
CATTGCCGGGCACCCTGCTGCGGAGCAGACGTGAAGGCGCACCACGAGGTCTGCCCCAAG
TTCCCCTTAACTTGTGACGGCTGCGGCAAGAAGAAGATCCCCCGGGAGAAGTTTCAGGAC
CACGTCAAGACTTGTGGCAAGTGTCGAGTCCCTTGCAGATTCCACGCCATCGGCTGCCTC
GAGACGGTAGAGGGTGAGAAACAGCAGGAGCACGAGGTGCAGTGGCTGCGGGAGCACCTG
GCCATGCTACTGAGCTCGGTGCTGGAGGCAAAGCCCCTCTTGGGAGACCAGAGCCACGCG
GGGTCAGAGCTCCTGCAGAGGTGCGAGAGCCTGGAGAAGAAGACGGCCACTTTTGAGAAC
ATTGTCTGCGTCCTGAACCGGGAGGTGGAGAGGGTGGCCATGACTGCCGAGGCCTGCAGC
CGGCAGCACCGGCTGGACCAAGACAAGATTGAAGCCCTGAGTAGCAAGGTGCAGCAGCTG
GAGAGGAGCATTGGCCTCAAGGACCTGGCGATGGCTGACTTGGAGCAGAAGGTCTTGGAG
ATGGAGGCATCCACCTACGATGGGGTCTTCATCTGGAAGATCTCAGACTTCGCCAGGAAG
CGCCAGGAAGCTGTGGCTGGCCGCATACCCGCCATCTTCTCCCCAGCCTTCTACACCAGC
AGGTACGGCTACAAGATGTGTCTGCGTATCTACCTGAACGGCGACGGCACCGGGCGAGGA
ACACACCTGTCCCTCTTCTTTGTGGTGATGAAGGGCCCGAATGACGCCCTGCTGCGGTGG
CCCTTCAACCAGAAGGTGACCTTAATGCTGCTCGACCAGAATAACCGGGAGCACGTGATT
GACGCCTTCAGGCCCGACGTGACTTCATCCTCTTTTCAGAGGCCAGTCAACGACATGAAC
ATCGCAAGCGGCTGCCCCCTCTTCTGCCCCGTCTCCAAGATGGAGGCAAAGAATTCCTAC
GTGCGGGACGATGCCATCTTCATCAAGGCCATTGTGGACCTGACAGGGCTCGTTTAAACG
AATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCC
GGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACT
AGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAAC
TATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCC
ACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTA
GCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTT
CCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCA
GCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTG
CCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCG
TTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGG
CTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGG
CTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAAT
GAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCA
GCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCG
GGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGAT
GCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAA
CATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTG
GACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATG
CCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTG
GAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTAT
CAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGAC
CGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGC
CTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGC
CCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAA
CGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGC
GTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTC
AAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAG
CTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCT
CCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTA
GGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGC
CTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGC
AGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTT
GAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCT
GAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGC
TGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCA
AGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTA
AGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGG
AAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGC
AGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCA
TACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTT
TACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGAT
TATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGG
CCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGA
ACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACC
TGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCC
CCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACT
GGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGC
CGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGC
CATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGT
TTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 1503 bp
Length: 1503 bp Restriction map B
Restriction map B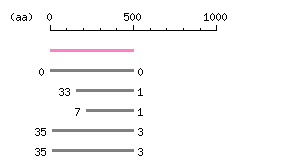

 more Linker info
more Linker info
{kind=link}