


-
SpecieshumanProduct IDFXC09682Cloning SiteSgfI-PmeIGeneKIEE1065SymbolSCUBE1Descriptionsignal peptide, CUB domain, EGF-like 1Original Clone IDcp01524
 Length: 2964 bp
Length: 2964 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 988 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)

Entry Exp ID% symbol CCDS14048.1 0 100.0 SCUBE1 CCDS81553.1 2.5e-125 64.3 SCUBE2 CCDS4800.1 2.2e-104 66.0 SCUBE3 CCDS7797.2 3.1e-62 62.3 SCUBE2 CCDS53599.1 8.6e-44 54.4 SCUBE2
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]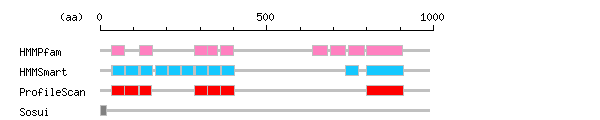 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition HMMPfam IPR013091 33 72 PF07645 EGF calcium-binding IPR013091 117 156 PF07645 EGF calcium-binding IPR013091 282 321 PF07645 EGF calcium-binding IPR013091 323 353 PF07645 EGF calcium-binding IPR013091 362 399 PF07645 EGF calcium-binding IPR011641 636 683 PF07699 Tyrosine-protein kinase ephrin type A/B receptor-like IPR011641 690 737 PF07699 Tyrosine-protein kinase ephrin type A/B receptor-like IPR011641 746 793 PF07699 Tyrosine-protein kinase ephrin type A/B receptor-like IPR000859 798 907 PF00431 CUB HMMSmart IPR001881 33 73 SM00179 EGF-like calcium-binding IPR006210 36 73 SM00181 Epidermal growth factor-like IPR001881 74 116 SM00179 EGF-like calcium-binding IPR006210 77 116 SM00181 Epidermal growth factor-like IPR001881 117 157 SM00179 EGF-like calcium-binding IPR006210 120 157 SM00181 Epidermal growth factor-like IPR006210 165 203 SM00181 Epidermal growth factor-like IPR006210 205 242 SM00181 Epidermal growth factor-like IPR006210 244 281 SM00181 Epidermal growth factor-like IPR001881 245 281 SM00179 EGF-like calcium-binding IPR001881 282 322 SM00179 EGF-like calcium-binding IPR006210 285 322 SM00181 Epidermal growth factor-like IPR001881 323 361 SM00179 EGF-like calcium-binding IPR006210 326 361 SM00181 Epidermal growth factor-like IPR001881 362 402 SM00179 EGF-like calcium-binding IPR006210 365 402 SM00181 Epidermal growth factor-like IPR006210 736 774 SM00181 Epidermal growth factor-like IPR000859 798 910 SM00042 CUB ProfileScan IPR000742 33 73 PS50026 Epidermal growth factor-like IPR000742 74 116 PS50026 Epidermal growth factor-like IPR000742 117 153 PS50026 Epidermal growth factor-like IPR000742 282 322 PS50026 Epidermal growth factor-like IPR000742 323 361 PS50026 Epidermal growth factor-like IPR000742 362 402 PS50026 Epidermal growth factor-like IPR000859 798 910 PS01180 CUB
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 1 MGAAAVRWHLCVLLALGT 18 PRIMARY 18
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_766638 988 611746 100.0 100.0 XP_005261809 1018 611746 97.1 100.0 XP_011528692 912 611746 96.7 89.3 XP_011528691 912 611746 96.7 89.3 NP_001317128 999 611747 64.3 98.2 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KE1065 Download>KIEE1065 2964 bp ATGGGCGCGGCGGCCGTGCGCTGGCACTTGTGCGTGCTGCTGGCCCTGGGCACACGCGGG CGGCTGGCCGGGGGCAGCGGGCTCCCAGGGTCAGTCGACGTGGATGAGTGCTCAGAGGGC ACAGATGACTGCCACATCGATGCCATCTGTCAGAACACGCCCAAGTCCTACAAATGCCTC TGCAAGCCAGGCTACAAGGGGGAAGGCAAGCAGTGTGAAGACATTGACGAGTGTGAGAAT GACTACTACAATGGGGGCTGTGTCCACGAGTGCATCAACATCCCGGGGAACTACAGGTGT ACCTGCTTTGATGGCTTCATGCTGGCACACGATGGACACAACTGCCTGGATGTGGACGAG TGTCAGGACAATAATGGTGGCTGCCAGCAGATCTGCGTCAATGCCATGGGCAGCTACGAG TGTCAGTGCCACAGTGGCTTCTTCCTTAGTGACAACCAGCATACCTGCATCCACCGCTCC AATGAGGGTATGAACTGCATGAACAAAGACCATGGCTGTGCCCACATCTGCCGGGAGACG CCCAAAGGTGGGGTGGCCTGCGACTGCAGGCCCGGCTTTGACCTTGCCCAAAACCAGAAG GACTGCACACTAACCTGTAATTATGGAAACGGAGGCTGCCAGCACAGCTGTGAGGACACA GACACAGGCCCCACGTGTGGTTGCCACCAGAAGTACGCCCTCCACTCAGACGGTCGCACG TGCATCGAGACGTGCGCAGTCAATAACGGAGGCTGCGACCGGACATGCAAGGACACAGCC ACTGGCGTGCGATGCAGCTGCCCCGTTGGATTCACACTGCAGCCGGACGGGAAGACATGC AAAGACATCAACGAGTGCCTGGTCAACAACGGAGGCTGCGACCACTTCTGCCGCAACACC GTGGGCAGCTTCGAGTGCGGCTGCCGGAAGGGCTACAAGCTGCTCACCGACGAGCGCACC TGCCAGGACATCGACGAGTGCTCCTTCGAGCGGACCTGTGACCACATCTGCATCAACTCC CCGGGCAGCTTCCAGTGCCTGTGTCACCGCGGCTACATCCTCTACGGGACAACCCACTGC GGAGATGTGGACGAGTGCAGCATGAGCAACGGGAGCTGTGACCAGGGCTGCGTCAACACC AAGGGCAGCTACGAGTGCGTCTGTCCCCCGGGGAGGCGGCTCCACTGGAACGGGAAGGAT TGCGTGGAGACAGGCAAGTGTCTTTCTCGCGCCAAGACCTCCCCCCGGGCCCAGCTGTCC TGCAGCAAGGCAGGCGGTGTGGAGAGCTGCTTCCTTTCCTGCCCGGCTCACACACTCTTC GTGCCAGACTCGGAAAATAGCTACGTCCTGAGCTGCGGAGTTCCAGGGCCGCAGGGCAAG GCGCTGCAGAAACGCAACGGCACCAGCTCTGGCCTCGGGCCCAGCTGCTCAGATGCCCCC ACCACCCCCATCAAACAGAAGGCCCGCTTCAAGATCCGAGATGCCAAGTGCCACCTCCGG CCCCACAGCCAGGCACGAGCAAAGGAGACCGCCAGGCAGCCGCTGCTGGACCACTGCCAT GTGACTTTCGTGACCCTCAAGTGTGACTCCTCCAAGAAGAGGCGCCGTGGCCGCAAGTCC CCATCCAAGGAGGTGTCCCACATCACAGCAGAGTTTGAGATCGAGACAAAGATGGAAGAG GCCTCAGACACATGCGAAGCGGACTGCTTGCGGAAGCGAGCAGAACAGAGCCTGCAGGCC GCCATCAAGACCCTGCGCAAGTCCATCGGCCGGCAGCAGTTCTATGTCCAGGTCTCAGGC ACTGAGTACGAGGTAGCCCAGAGGCCAGCCAAGGCGCTGGAGGGGCAGGGGGCATGTGGC GCAGGCCAGGTGCTACAGGACAGCAAATGCGTTGCCTGTGGGCCTGGCACCCACTTCGGT GGTGAGCTCGGCCAGTGTGTGTCATGTATGCCAGGAACATACCAGGACATGGAAGGCCAG CTCAGTTGCACACCGTGCCCCAGCAGCGACGGGCTTGGTCTGCCTGGTGCCCGCAACGTG TCGGAATGTGGAGGCCAGTGTTCTCCAGGCTTCTTCTCGGCCGATGGCTTCAAGCCCTGC CAGGCCTGCCCCGTGGGCACGTACCAGCCTGAGCCCGGGCGCACCGGCTGCTTCCCCTGT GGAGGGGGTTTGCTCACCAAACACGAAGGCACCACCTCCTTCCAGGACTGCGAGGCTAAA GTGCACTGCTCCCCCGGCCACCACTACAACACCACCACCCACCGCTGCATCCGCTGCCCC GTCGGCACCTACCAGCCCGAGTTTGGCCAGAACCACTGCATCACCTGTCCGGGCAACACC AGCACAGACTTCGATGGCTCCACCAACGTCACACACTGCAAAAACCAGCACTGCGGCGGC GAGCTTGGTGACTACACCGGCTACATCGAGTCCCCCAACTACCCTGGCGACTACCCAGCC AACGCTGAATGCGTCTGGCACATCGCGCCTCCCCCAAAGCGCAGGATCCTCATCGTGGTC CCTGAGATCTTCCTGCCCATCGAGGATGAGTGCGGCGATGTTCTGGTCATGAGGAAGAGT GCCTCTCCCACGTCCATCACCACCTATGAGACCTGCCAGACCTACGAGAGGCCCATCGCC TTCACCTCCCGCTCCCGCAAGCTCTGGATCCAGTTCAAATCCAATGAAGGCAACAGCGGC AAAGGCTTCCAAGTGCCCTATGTCACCTACGATGAGGACTACCAGCAACTCATAGAGGAC ATCGTGCGCGATGGGCGCCTGTACGCCTCGGAGAACCACCAGGAAATTTTGAAAGACAAG AAGCTGATCAAGGCCCTCTTCGACGTGCTGGCGCATCCCCAGAACTACTTCAAGTACACA GCCCAGGAATCCAAGGAGATGTTCCCACGGTCCTTCATCAAACTGCTGCGCTCCAAAGTG TCTCGGTTCCTGCGGCCCTACAAA
Cloned ORF protein sequence for pF1KE1065 Download>KIEE1065 988 aa MGAAAVRWHLCVLLALGTRGRLAGGSGLPGSVDVDECSEGTDDCHIDAICQNTPKSYKCL CKPGYKGEGKQCEDIDECENDYYNGGCVHECINIPGNYRCTCFDGFMLAHDGHNCLDVDE CQDNNGGCQQICVNAMGSYECQCHSGFFLSDNQHTCIHRSNEGMNCMNKDHGCAHICRET PKGGVACDCRPGFDLAQNQKDCTLTCNYGNGGCQHSCEDTDTGPTCGCHQKYALHSDGRT CIETCAVNNGGCDRTCKDTATGVRCSCPVGFTLQPDGKTCKDINECLVNNGGCDHFCRNT VGSFECGCRKGYKLLTDERTCQDIDECSFERTCDHICINSPGSFQCLCHRGYILYGTTHC GDVDECSMSNGSCDQGCVNTKGSYECVCPPGRRLHWNGKDCVETGKCLSRAKTSPRAQLS CSKAGGVESCFLSCPAHTLFVPDSENSYVLSCGVPGPQGKALQKRNGTSSGLGPSCSDAP TTPIKQKARFKIRDAKCHLRPHSQARAKETARQPLLDHCHVTFVTLKCDSSKKRRRGRKS PSKEVSHITAEFEIETKMEEASDTCEADCLRKRAEQSLQAAIKTLRKSIGRQQFYVQVSG TEYEVAQRPAKALEGQGACGAGQVLQDSKCVACGPGTHFGGELGQCVSCMPGTYQDMEGQ LSCTPCPSSDGLGLPGARNVSECGGQCSPGFFSADGFKPCQACPVGTYQPEPGRTGCFPC GGGLLTKHEGTTSFQDCEAKVHCSPGHHYNTTTHRCIRCPVGTYQPEFGQNHCITCPGNT STDFDGSTNVTHCKNQHCGGELGDYTGYIESPNYPGDYPANAECVWHIAPPPKRRILIVV PEIFLPIEDECGDVLVMRKSASPTSITTYETCQTYERPIAFTSRSRKLWIQFKSNEGNSG KGFQVPYVTYDEDYQQLIEDIVRDGRLYASENHQEILKDKKLIKALFDVLAHPQNYFKYT AQESKEMFPRSFIKLLRSKVSRFLRPYK
Nucleotide Sequence (with vector) for pF1KE1065 Download>pF1KE1065 6077 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGGCGCGGCG GCCGTGCGCTGGCACTTGTGCGTGCTGCTGGCCCTGGGCACACGCGGGCGGCTGGCCGGG GGCAGCGGGCTCCCAGGGTCAGTCGACGTGGATGAGTGCTCAGAGGGCACAGATGACTGC CACATCGATGCCATCTGTCAGAACACGCCCAAGTCCTACAAATGCCTCTGCAAGCCAGGC TACAAGGGGGAAGGCAAGCAGTGTGAAGACATTGACGAGTGTGAGAATGACTACTACAAT GGGGGCTGTGTCCACGAGTGCATCAACATCCCGGGGAACTACAGGTGTACCTGCTTTGAT GGCTTCATGCTGGCACACGATGGACACAACTGCCTGGATGTGGACGAGTGTCAGGACAAT AATGGTGGCTGCCAGCAGATCTGCGTCAATGCCATGGGCAGCTACGAGTGTCAGTGCCAC AGTGGCTTCTTCCTTAGTGACAACCAGCATACCTGCATCCACCGCTCCAATGAGGGTATG AACTGCATGAACAAAGACCATGGCTGTGCCCACATCTGCCGGGAGACGCCCAAAGGTGGG GTGGCCTGCGACTGCAGGCCCGGCTTTGACCTTGCCCAAAACCAGAAGGACTGCACACTA ACCTGTAATTATGGAAACGGAGGCTGCCAGCACAGCTGTGAGGACACAGACACAGGCCCC ACGTGTGGTTGCCACCAGAAGTACGCCCTCCACTCAGACGGTCGCACGTGCATCGAGACG TGCGCAGTCAATAACGGAGGCTGCGACCGGACATGCAAGGACACAGCCACTGGCGTGCGA TGCAGCTGCCCCGTTGGATTCACACTGCAGCCGGACGGGAAGACATGCAAAGACATCAAC GAGTGCCTGGTCAACAACGGAGGCTGCGACCACTTCTGCCGCAACACCGTGGGCAGCTTC GAGTGCGGCTGCCGGAAGGGCTACAAGCTGCTCACCGACGAGCGCACCTGCCAGGACATC GACGAGTGCTCCTTCGAGCGGACCTGTGACCACATCTGCATCAACTCCCCGGGCAGCTTC CAGTGCCTGTGTCACCGCGGCTACATCCTCTACGGGACAACCCACTGCGGAGATGTGGAC GAGTGCAGCATGAGCAACGGGAGCTGTGACCAGGGCTGCGTCAACACCAAGGGCAGCTAC GAGTGCGTCTGTCCCCCGGGGAGGCGGCTCCACTGGAACGGGAAGGATTGCGTGGAGACA GGCAAGTGTCTTTCTCGCGCCAAGACCTCCCCCCGGGCCCAGCTGTCCTGCAGCAAGGCA GGCGGTGTGGAGAGCTGCTTCCTTTCCTGCCCGGCTCACACACTCTTCGTGCCAGACTCG GAAAATAGCTACGTCCTGAGCTGCGGAGTTCCAGGGCCGCAGGGCAAGGCGCTGCAGAAA CGCAACGGCACCAGCTCTGGCCTCGGGCCCAGCTGCTCAGATGCCCCCACCACCCCCATC AAACAGAAGGCCCGCTTCAAGATCCGAGATGCCAAGTGCCACCTCCGGCCCCACAGCCAG GCACGAGCAAAGGAGACCGCCAGGCAGCCGCTGCTGGACCACTGCCATGTGACTTTCGTG ACCCTCAAGTGTGACTCCTCCAAGAAGAGGCGCCGTGGCCGCAAGTCCCCATCCAAGGAG GTGTCCCACATCACAGCAGAGTTTGAGATCGAGACAAAGATGGAAGAGGCCTCAGACACA TGCGAAGCGGACTGCTTGCGGAAGCGAGCAGAACAGAGCCTGCAGGCCGCCATCAAGACC CTGCGCAAGTCCATCGGCCGGCAGCAGTTCTATGTCCAGGTCTCAGGCACTGAGTACGAG GTAGCCCAGAGGCCAGCCAAGGCGCTGGAGGGGCAGGGGGCATGTGGCGCAGGCCAGGTG CTACAGGACAGCAAATGCGTTGCCTGTGGGCCTGGCACCCACTTCGGTGGTGAGCTCGGC CAGTGTGTGTCATGTATGCCAGGAACATACCAGGACATGGAAGGCCAGCTCAGTTGCACA CCGTGCCCCAGCAGCGACGGGCTTGGTCTGCCTGGTGCCCGCAACGTGTCGGAATGTGGA GGCCAGTGTTCTCCAGGCTTCTTCTCGGCCGATGGCTTCAAGCCCTGCCAGGCCTGCCCC GTGGGCACGTACCAGCCTGAGCCCGGGCGCACCGGCTGCTTCCCCTGTGGAGGGGGTTTG CTCACCAAACACGAAGGCACCACCTCCTTCCAGGACTGCGAGGCTAAAGTGCACTGCTCC CCCGGCCACCACTACAACACCACCACCCACCGCTGCATCCGCTGCCCCGTCGGCACCTAC CAGCCCGAGTTTGGCCAGAACCACTGCATCACCTGTCCGGGCAACACCAGCACAGACTTC GATGGCTCCACCAACGTCACACACTGCAAAAACCAGCACTGCGGCGGCGAGCTTGGTGAC TACACCGGCTACATCGAGTCCCCCAACTACCCTGGCGACTACCCAGCCAACGCTGAATGC GTCTGGCACATCGCGCCTCCCCCAAAGCGCAGGATCCTCATCGTGGTCCCTGAGATCTTC CTGCCCATCGAGGATGAGTGCGGCGATGTTCTGGTCATGAGGAAGAGTGCCTCTCCCACG TCCATCACCACCTATGAGACCTGCCAGACCTACGAGAGGCCCATCGCCTTCACCTCCCGC TCCCGCAAGCTCTGGATCCAGTTCAAATCCAATGAAGGCAACAGCGGCAAAGGCTTCCAA GTGCCCTATGTCACCTACGATGAGGACTACCAGCAACTCATAGAGGACATCGTGCGCGAT GGGCGCCTGTACGCCTCGGAGAACCACCAGGAAATTTTGAAAGACAAGAAGCTGATCAAG GCCCTCTTCGACGTGCTGGCGCATCCCCAGAACTACTTCAAGTACACAGCCCAGGAATCC AAGGAGATGTTCCCACGGTCCTTCATCAAACTGCTGCGCTCCAAAGTGTCTCGGTTCCTG CGGCCCTACAAAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACC TGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGC TGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGG TTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTC TAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTC CCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACT GGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCG TGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAA GTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGAT CAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCT CCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGC TCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACC GACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCC ACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGG CTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAG AAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGC CCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGT CTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTC GCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCC TGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGG CTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAG CTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCG CAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCG AAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTT ATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGC CAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGA GCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATA CCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTAC CGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTG TAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCC CGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAG ACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGT AGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGT ATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTG ATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTAC GCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCA GTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCAC CTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGAT GGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACC CTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTT CGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAG CGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCG AGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAG CCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGG CAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGC CGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAAC GAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTC TCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAG GGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCC TGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCA AATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}