


-
SpecieshumanProduct IDFXC31381Cloning SiteSgfI-PmeIGenBank AccessionGeneKIEE2112SymbolTRPC3
Alias : SCA41, TRP3Descriptiontransient receptor potential cation channel subfamily C member 3, transcript variant 1Original Clone IDcs03212 Length: 2763 bp
Length: 2763 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 921 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
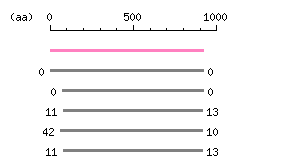
Entry Exp ID% symbol CCDS47130.1 0 100.0 TRPC3 CCDS3725.1 0 100.0 TRPC3 CCDS47267.2 0 81.1 TRPC7 CCDS8311.1 6.8e-200 72.0 TRPC6 CCDS54906.1 1.6e-142 75.4 TRPC7
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]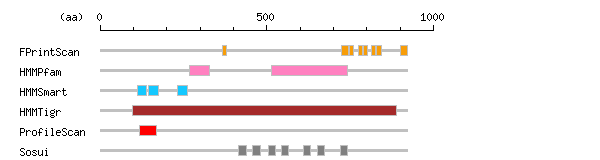 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR005459 366 378 PR01644 Transient receptor potential channel IPR002153 725 746 PR01097 Transient receptor potential channel IPR002153 747 760 PR01097 Transient receptor potential channel IPR002153 775 788 PR01097 Transient receptor potential channel IPR005459 789 803 PR01644 Transient receptor potential channel IPR005459 815 826 PR01644 Transient receptor potential channel IPR005459 829 845 PR01644 Transient receptor potential channel IPR005459 900 921 PR01644 Transient receptor potential channel HMMPfam IPR013555 267 329 PF08344 Transient receptor potential II IPR005821 513 743 PF00520 Ion transport HMMSmart IPR002110 111 140 SM00248 Ankyrin repeat IPR002110 146 174 SM00248 Ankyrin repeat IPR002110 232 261 SM00248 Ankyrin repeat HMMTigr IPR004729 96 890 TIGR00870 Transient receptor potential channel ProfileScan IPR020683 119 169 PS50297 Ankyrin repeat-containing domain
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 416 EQTIAIKCLVVLVVALGLPFLAI 438 PRIMARY 23 2 458 KFVAHAASFIIFLGLLVFNASDR 480 PRIMARY 23 3 506 QFTWTEMLIMVWVLGMMWSEC 526 SECONDARY 21 4 543 NVLDFGMLSIFIAAFTARFLAFL 565 SECONDARY 23 5 609 IISEGLYAIAVVLSFSRIAYILP 631 PRIMARY 23 6 651 FKFMVLFIMVFFAFMIGMFILYS 673 PRIMARY 23 7 720 GYVLYGIYNVTMVVVLLNMLIAM 742 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_001124170 921 602345,616410 100.0 100.0 XP_011530520 920 602345,616410 99.9 100.0 NP_003296 848 602345,616410 100.0 92.1 XP_016864067 936 602345,616410 98.2 100.0 XP_011530519 937 602345,616410 98.3 100.0 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KE2112 Download>KIEE2112 2763 bp ATGTCCACCAAGGTCAGGAAGTGCAAAGAACAAGCAAGGGTGACCTTCCCGGCGCCGGAG GAGGAGGAAGACGAGGGCGAGGACGAGGGCGCGGAGCCGCAGCGCCGCCGCCGGGGCTGG AGGGGCGTCAACGGGGGGCTGGAGCCGCGCTCGGCGCCCTCGCAGCGGGAGCCGCACGGC TACTGCCCGCCGCCCTTCTCCCACGGGCCGGACCTGTCCATGGAGGGAAGCCCATCCCTG AGACGCATGACAGTGATGCGGGAGAAGGGCCGGCGCCAGGCTGTCAGGGGCCCGGCCTTC ATGTTCAATGACCGCGGCACCAGCCTCACCGCCGAGGAGGAGCGCTTCCTCGACGCCGCC GAGTACGGCAACATCCCAGTGGTGCGCAAGATGCTGGAGGAGTCCAAGACGCTGAACGTC AACTGCGTGGACTACATGGGCCAGAACGCGCTGCAGCTGGCTGTGGGCAACGAGCACCTG GAGGTGACCGAGCTGCTGCTCAAGAAGGAGAACCTGGCGCGCATTGGCGACGCCCTGCTG CTCGCCATCAGCAAGGGCTACGTGCGCATCGTAGAGGCCATCCTCAACCACCCTGGCTTC GCGGCCAGCAAGCGTCTCACTCTGAGCCCCTGTGAGCAGGAGCTGCAGGACGACGACTTC TACGCTTACGACGAGGACGGCACGCGCTTCTCGCCGGACATCACCCCCATCATCCTGGCG GCGCACTGCCAGAAATACGAAGTGGTGCACATGCTGCTGATGAAGGGTGCCAGGATCGAG CGGCCGCACGACTATTTCTGCAAGTGCGGGGACTGCATGGAGAAGCAGAGGCACGACTCC TTCAGCCACTCACGCTCGAGGATCAATGCCTACAAGGGGCTGGCCAGCCCGGCTTACCTC TCATTGTCCAGCGAGGACCCGGTGCTTACGGCCCTAGAGCTCAGCAACGAGCTGGCCAAG CTGGCCAACATAGAGAAGGAGTTCAAGAATGACTATCGGAAGCTCTCCATGCAATGCAAA GACTTTGTAGTGGGTGTGCTGGATCTCTGCCGAGACTCAGAAGAGGTAGAAGCCATTCTG AATGGAGATCTGGAATCAGCAGAGCCTCTGGAGGTACACAGGCACAAAGCTTCATTAAGT CGTGTCAAACTTGCCATTAAGTATGAAGTCAAAAAGTTTGTGGCTCATCCCAACTGCCAG CAGCAGCTCTTGACGATCTGGTATGAGAACCTCTCAGGCCTAAGGGAGCAGACCATAGCT ATCAAGTGTCTCGTTGTGCTGGTCGTGGCCCTGGGCCTTCCATTCCTGGCCATTGGCTAC TGGATCGCACCTTGCAGCAGGCTGGGGAAAATTCTGCGAAGCCCTTTTATGAAGTTTGTA GCACATGCAGCTTCTTTCATCATCTTCCTGGGTCTGCTTGTGTTCAATGCCTCAGACAGG TTCGAAGGCATCACCACGCTGCCCAATATCACAGTTACTGACTATCCCAAACAGATCTTC AGGGTGAAAACCACCCAGTTTACATGGACTGAAATGCTAATTATGGTCTGGGTTCTTGGA ATGATGTGGTCTGAATGTAAAGAGCTCTGGCTGGAAGGACCTAGGGAATACATTTTGCAG TTGTGGAATGTGCTTGACTTTGGGATGCTGTCCATCTTCATTGCTGCTTTCACAGCCAGA TTCCTAGCTTTCCTTCAGGCAACGAAGGCACAACAGTATGTGGACAGTTACGTCCAAGAG AGTGACCTCAGTGAAGTGACACTCCCACCAGAGATACAGTATTTCACTTATGCTAGAGAT AAATGGCTCCCTTCTGACCCTCAGATTATATCTGAAGGCCTTTATGCCATAGCTGTTGTG CTCAGCTTCTCTCGGATTGCGTACATCCTCCCTGCAAATGAGAGCTTTGGCCCCCTGCAG ATCTCTCTTGGAAGGACTGTAAAGGACATATTCAAGTTCATGGTCCTCTTTATTATGGTG TTTTTTGCCTTTATGATTGGCATGTTCATACTTTATTCTTACTACCTTGGGGCTAAAGTT AATGCTGCTTTTACCACTGTAGAAGAAAGTTTCAAGACTTTATTTTGGTCAATATTTGGG TTGTCTGAAGTGACTTCCGTTGTGCTCAAATATGATCACAAATTCATAGAAAATATTGGA TACGTTCTTTATGGAATATACAATGTAACTATGGTGGTCGTTTTACTCAACATGCTAATT GCTATGATTAATAGCTCATATCAAGAAATTGAGGATGACAGTGATGTAGAATGGAAGTTT GCTCGTTCAAAACTTTGGTTATCCTATTTTGATGATGGAAAAACATTACCTCCACCTTTC AGTCTAGTTCCTAGTCCAAAATCATTTGTTTATTTCATCATGCGAATTGTTAACTTTCCC AAATGCAGAAGGAGAAGGCTTCAGAAGGATATAGAAATGGGAATGGGTAACTCAAAGTCC AGGTTAAACCTCTTCACTCAGTCTAACTCAAGAGTTTTTGAATCACACAGTTTTAACAGC ATTCTCAATCAGCCAACACGTTATCAGCAGATAATGAAAAGACTTATAAAGCGGTATGTT TTGAAAGCACAAGTAGACAAAGAAAATGATGAAGTTAATGAAGGTGAATTAAAAGAAATC AAGCAAGATATCTCCAGCCTTCGTTATGAACTTTTGGAAGACAAGAGCCAAGCAACTGAG GAATTAGCCATTCTAATTCATAAACTTAGTGAGAAACTGAATCCCAGCATGCTGAGATGT GAA
Cloned ORF protein sequence for pF1KE2112 Download>KIEE2112 921 aa MSTKVRKCKEQARVTFPAPEEEEDEGEDEGAEPQRRRRGWRGVNGGLEPRSAPSQREPHG YCPPPFSHGPDLSMEGSPSLRRMTVMREKGRRQAVRGPAFMFNDRGTSLTAEEERFLDAA EYGNIPVVRKMLEESKTLNVNCVDYMGQNALQLAVGNEHLEVTELLLKKENLARIGDALL LAISKGYVRIVEAILNHPGFAASKRLTLSPCEQELQDDDFYAYDEDGTRFSPDITPIILA AHCQKYEVVHMLLMKGARIERPHDYFCKCGDCMEKQRHDSFSHSRSRINAYKGLASPAYL SLSSEDPVLTALELSNELAKLANIEKEFKNDYRKLSMQCKDFVVGVLDLCRDSEEVEAIL NGDLESAEPLEVHRHKASLSRVKLAIKYEVKKFVAHPNCQQQLLTIWYENLSGLREQTIA IKCLVVLVVALGLPFLAIGYWIAPCSRLGKILRSPFMKFVAHAASFIIFLGLLVFNASDR FEGITTLPNITVTDYPKQIFRVKTTQFTWTEMLIMVWVLGMMWSECKELWLEGPREYILQ LWNVLDFGMLSIFIAAFTARFLAFLQATKAQQYVDSYVQESDLSEVTLPPEIQYFTYARD KWLPSDPQIISEGLYAIAVVLSFSRIAYILPANESFGPLQISLGRTVKDIFKFMVLFIMV FFAFMIGMFILYSYYLGAKVNAAFTTVEESFKTLFWSIFGLSEVTSVVLKYDHKFIENIG YVLYGIYNVTMVVVLLNMLIAMINSSYQEIEDDSDVEWKFARSKLWLSYFDDGKTLPPPF SLVPSPKSFVYFIMRIVNFPKCRRRRLQKDIEMGMGNSKSRLNLFTQSNSRVFESHSFNS ILNQPTRYQQIMKRLIKRYVLKAQVDKENDEVNEGELKEIKQDISSLRYELLEDKSQATE ELAILIHKLSEKLNPSMLRCE
Nucleotide Sequence (with vector) for pF1KE2112 Download>pF1KE2112 5876 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGTCCACCAAG GTCAGGAAGTGCAAAGAACAAGCAAGGGTGACCTTCCCGGCGCCGGAGGAGGAGGAAGAC GAGGGCGAGGACGAGGGCGCGGAGCCGCAGCGCCGCCGCCGGGGCTGGAGGGGCGTCAAC GGGGGGCTGGAGCCGCGCTCGGCGCCCTCGCAGCGGGAGCCGCACGGCTACTGCCCGCCG CCCTTCTCCCACGGGCCGGACCTGTCCATGGAGGGAAGCCCATCCCTGAGACGCATGACA GTGATGCGGGAGAAGGGCCGGCGCCAGGCTGTCAGGGGCCCGGCCTTCATGTTCAATGAC CGCGGCACCAGCCTCACCGCCGAGGAGGAGCGCTTCCTCGACGCCGCCGAGTACGGCAAC ATCCCAGTGGTGCGCAAGATGCTGGAGGAGTCCAAGACGCTGAACGTCAACTGCGTGGAC TACATGGGCCAGAACGCGCTGCAGCTGGCTGTGGGCAACGAGCACCTGGAGGTGACCGAG CTGCTGCTCAAGAAGGAGAACCTGGCGCGCATTGGCGACGCCCTGCTGCTCGCCATCAGC AAGGGCTACGTGCGCATCGTAGAGGCCATCCTCAACCACCCTGGCTTCGCGGCCAGCAAG CGTCTCACTCTGAGCCCCTGTGAGCAGGAGCTGCAGGACGACGACTTCTACGCTTACGAC GAGGACGGCACGCGCTTCTCGCCGGACATCACCCCCATCATCCTGGCGGCGCACTGCCAG AAATACGAAGTGGTGCACATGCTGCTGATGAAGGGTGCCAGGATCGAGCGGCCGCACGAC TATTTCTGCAAGTGCGGGGACTGCATGGAGAAGCAGAGGCACGACTCCTTCAGCCACTCA CGCTCGAGGATCAATGCCTACAAGGGGCTGGCCAGCCCGGCTTACCTCTCATTGTCCAGC GAGGACCCGGTGCTTACGGCCCTAGAGCTCAGCAACGAGCTGGCCAAGCTGGCCAACATA GAGAAGGAGTTCAAGAATGACTATCGGAAGCTCTCCATGCAATGCAAAGACTTTGTAGTG GGTGTGCTGGATCTCTGCCGAGACTCAGAAGAGGTAGAAGCCATTCTGAATGGAGATCTG GAATCAGCAGAGCCTCTGGAGGTACACAGGCACAAAGCTTCATTAAGTCGTGTCAAACTT GCCATTAAGTATGAAGTCAAAAAGTTTGTGGCTCATCCCAACTGCCAGCAGCAGCTCTTG ACGATCTGGTATGAGAACCTCTCAGGCCTAAGGGAGCAGACCATAGCTATCAAGTGTCTC GTTGTGCTGGTCGTGGCCCTGGGCCTTCCATTCCTGGCCATTGGCTACTGGATCGCACCT TGCAGCAGGCTGGGGAAAATTCTGCGAAGCCCTTTTATGAAGTTTGTAGCACATGCAGCT TCTTTCATCATCTTCCTGGGTCTGCTTGTGTTCAATGCCTCAGACAGGTTCGAAGGCATC ACCACGCTGCCCAATATCACAGTTACTGACTATCCCAAACAGATCTTCAGGGTGAAAACC ACCCAGTTTACATGGACTGAAATGCTAATTATGGTCTGGGTTCTTGGAATGATGTGGTCT GAATGTAAAGAGCTCTGGCTGGAAGGACCTAGGGAATACATTTTGCAGTTGTGGAATGTG CTTGACTTTGGGATGCTGTCCATCTTCATTGCTGCTTTCACAGCCAGATTCCTAGCTTTC CTTCAGGCAACGAAGGCACAACAGTATGTGGACAGTTACGTCCAAGAGAGTGACCTCAGT GAAGTGACACTCCCACCAGAGATACAGTATTTCACTTATGCTAGAGATAAATGGCTCCCT TCTGACCCTCAGATTATATCTGAAGGCCTTTATGCCATAGCTGTTGTGCTCAGCTTCTCT CGGATTGCGTACATCCTCCCTGCAAATGAGAGCTTTGGCCCCCTGCAGATCTCTCTTGGA AGGACTGTAAAGGACATATTCAAGTTCATGGTCCTCTTTATTATGGTGTTTTTTGCCTTT ATGATTGGCATGTTCATACTTTATTCTTACTACCTTGGGGCTAAAGTTAATGCTGCTTTT ACCACTGTAGAAGAAAGTTTCAAGACTTTATTTTGGTCAATATTTGGGTTGTCTGAAGTG ACTTCCGTTGTGCTCAAATATGATCACAAATTCATAGAAAATATTGGATACGTTCTTTAT GGAATATACAATGTAACTATGGTGGTCGTTTTACTCAACATGCTAATTGCTATGATTAAT AGCTCATATCAAGAAATTGAGGATGACAGTGATGTAGAATGGAAGTTTGCTCGTTCAAAA CTTTGGTTATCCTATTTTGATGATGGAAAAACATTACCTCCACCTTTCAGTCTAGTTCCT AGTCCAAAATCATTTGTTTATTTCATCATGCGAATTGTTAACTTTCCCAAATGCAGAAGG AGAAGGCTTCAGAAGGATATAGAAATGGGAATGGGTAACTCAAAGTCCAGGTTAAACCTC TTCACTCAGTCTAACTCAAGAGTTTTTGAATCACACAGTTTTAACAGCATTCTCAATCAG CCAACACGTTATCAGCAGATAATGAAAAGACTTATAAAGCGGTATGTTTTGAAAGCACAA GTAGACAAAGAAAATGATGAAGTTAATGAAGGTGAATTAAAAGAAATCAAGCAAGATATC TCCAGCCTTCGTTATGAACTTTTGGAAGACAAGAGCCAAGCAACTGAGGAATTAGCCATT CTAATTCATAAACTTAGTGAGAAACTGAATCCCAGCATGCTGAGATGTGAAGTTTAAACG AATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCC GGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACT AGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAAC TATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCC ACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTA GCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTT CCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCA GCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTG CCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCG TTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGG CTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGG CTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAAT GAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCA GCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCG GGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGAT GCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAA CATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTG GACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATG CCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTG GAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTAT CAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGAC CGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGC CTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGC CCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAA CGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGC GTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTC AAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAG CTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCT CCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTA GGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGC CTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGC AGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTT GAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCT GAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGC TGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCA AGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTA AGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGG AAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGC AGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCA TACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTT TACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGAT TATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGG CCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGA ACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACC TGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCC CCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACT GGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGC CGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGC CATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGT TTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}