


-
SpecieshumanProduct IDFXC21331Cloning SiteSgfI-PmeIGenBank AccessionGeneKIEE3341SymbolEPHA4
Alias : EK8, HEK8, SEK, TYRO1DescriptionEPH receptor A4, transcript variant 2Original Clone IDcp93341 Length: 2958 bp
Length: 2958 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 986 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)

Entry Exp ID% symbol CCDS2447.1 9.5e-196 100.0 EPHA4 CCDS75131.1 2.2e-129 66.2 EPHA5 CCDS3514.1 4.3e-129 66.2 EPHA5 CCDS2922.1 6.8e-126 63.6 EPHA3 CCDS3268.1 1.9e-110 58.7 EPHB3
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]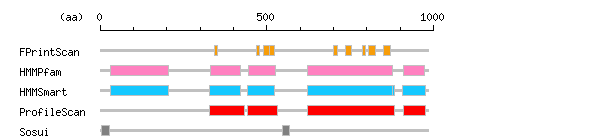 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan NULL 342 351 PR00014 NULL NULL 468 478 PR00014 NULL NULL 491 509 PR00014 NULL NULL 509 523 PR00014 NULL IPR001245 699 712 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 736 754 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 786 796 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 805 827 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 849 871 PR00109 Serine-threonine/tyrosine-protein kinase HMMPfam IPR001090 30 204 PF01404 Ephrin receptor IPR003961 330 420 PF00041 Fibronectin IPR003961 446 525 PF00041 Fibronectin IPR001245 621 878 PF07714 Serine-threonine/tyrosine-protein kinase IPR011510 909 973 PF07647 Sterile alpha motif HMMSmart IPR001090 30 204 SM00615 Ephrin receptor IPR003961 329 420 SM00060 Fibronectin IPR003961 441 522 SM00060 Fibronectin IPR002290 621 882 SM00220 Serine/threonine-protein kinase domain IPR020635 621 878 SM00219 Tyrosine-protein kinase IPR001660 908 975 SM00454 Sterile alpha motif domain ProfileScan IPR003961 328 433 PS50853 Fibronectin IPR003961 441 532 PS50853 Fibronectin IPR000719 621 882 PS50011 Protein kinase IPR001660 911 975 PS50105 Sterile alpha motif domain
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 4 IFYFALFSCLFGICDAVTGSRVY 26 SECONDARY 23 2 547 TVLLVSVSGSVVLVVILIAAFVI 569 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_001291465 986 602188 100.0 100.0 NP_004429 986 602188 100.0 100.0 XP_005246431 949 602188 100.0 96.2 NP_001291466 935 602188 100.0 94.6 NP_001268695 1016 600004 66.2 99.2 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KE3341 Download>KIEE3341 2958 bp ATGGCTGGGATTTTCTATTTCGCCCTATTTTCGTGTCTCTTCGGGATTTGCGACGCTGTC ACAGGTTCCAGGGTATACCCCGCGAATGAAGTTACCTTATTGGATTCCAGATCTGTTCAG GGAGAACTTGGGTGGATAGCAAGCCCTCTGGAAGGAGGGTGGGAGGAAGTGAGTATCATG GATGAAAAAAATACACCAATCCGAACCTACCAAGTGTGCAATGTGATGGAACCCAGCCAG AATAACTGGCTACGAACTGATTGGATCACCCGAGAAGGGGCTCAGAGGGTGTATATTGAG ATTAAATTCACCTTGAGGGACTGCAATAGTCTTCCGGGCGTCATGGGGACTTGCAAGGAG ACGTTTAACCTGTACTACTATGAATCAGACAACGACAAAGAGCGTTTCATCAGAGAGAAC CAGTTTGTCAAAATTGACACCATTGCTGCTGATGAGAGCTTCACCCAAGTGGACATTGGT GACAGAATCATGAAGCTGAACACCGAGATCCGGGATGTAGGGCCATTAAGCAAAAAGGGG TTTTACCTGGCTTTTCAGGATGTGGGGGCCTGCATCGCCCTGGTATCAGTCCGTGTGTTC TATAAAAAGTGTCCACTCACAGTCCGCAATCTGGCCCAGTTTCCTGACACCATCACAGGG GCTGATACGTCTTCCCTGGTGGAAGTTCGAGGCTCCTGTGTCAACAACTCAGAAGAGAAA GATGTGCCAAAAATGTACTGTGGGGCAGATGGTGAATGGCTGGTACCCATTGGCAACTGC CTATGCAACGCTGGGCATGAGGAGCGGAGCGGAGAATGCCAAGCTTGCAAAATTGGATAT TACAAGGCTCTCTCCACGGATGCCACCTGTGCCAAGTGCCCACCCCACAGCTACTCTGTC TGGGAAGGAGCCACCTCGTGCACCTGTGACCGAGGCTTTTTCAGAGCTGACAACGATGCT GCCTCTATGCCCTGCACCCGTCCACCATCTGCTCCCCTGAACTTGATTTCAAATGTCAAC GAGACATCTGTGAACTTGGAATGGAGTAGCCCTCAGAATACAGGTGGCCGCCAGGACATT TCCTATAATGTGGTATGCAAGAAATGTGGAGCTGGTGACCCCAGCAAGTGCCGACCCTGT GGAAGTGGGGTCCACTACACCCCACAGCAGAATGGCTTGAAGACCACCAAAGTCTCCATC ACTGACCTCCTAGCTCATACCAATTACACCTTTGAAATCTGGGCTGTGAATGGAGTGTCC AAATATAACCCTAACCCAGACCAATCAGTTTCTGTCACTGTGACCACCAACCAAGCAGCA CCATCATCCATTGCTTTGGTCCAGGCTAAAGAAGTCACAAGATACAGTGTGGCACTGGCT TGGCTGGAACCAGATCGGCCCAATGGGGTAATCCTGGAATATGAAGTCAAGTATTATGAG AAGGATCAGAATGAGCGAAGCTATCGTATAGTTCGGACAGCTGCCAGGAACACAGATATC AAAGGCCTGAACCCTCTCACTTCCTATGTTTTCCACGTGCGAGCCAGGACAGCAGCTGGC TATGGAGACTTCAGTGAGCCCTTGGAGGTTACAACCAACACAGTGCCTTCCCGGATCATT GGAGATGGGGCTAACTCCACAGTCCTTCTGGTCTCTGTCTCGGGCAGTGTGGTGCTGGTG GTAATTCTCATTGCAGCTTTTGTCATCAGCCGGAGACGGAGTAAATACAGTAAAGCCAAA CAAGAAGCGGATGAAGAGAAACATTTGAATCAAGGTGTAAGAACATATGTGGACCCCTTT ACGTACGAAGATCCCAACCAAGCAGTGCGAGAGTTTGCCAAAGAAATTGACGCATCCTGC ATTAAGATTGAAAAAGTTATAGGAGTTGGTGAATTTGGTGAGGTATGCAGTGGGCGTCTC AAAGTGCCTGGCAAGAGAGAGATCTGTGTGGCTATCAAGACTCTGAAAGCTGGTTATACA GACAAACAGAGGAGAGACTTCCTGAGTGAGGCCAGCATCATGGGACAGTTTGACCATCCG AACATCATTCACTTGGAAGGCGTGGTCACTAAATGTAAACCAGTAATGATCATAACAGAG TACATGGAGAATGGCTCCTTGGATGCATTCCTCAGGAAAAATGATGGCAGATTTACAGTC ATTCAGCTGGTGGGCATGCTTCGTGGCATTGGGTCTGGGATGAAGTATTTATCTGATATG AGCTATGTGCATCGTGATCTGGCCGCACGGAACATCCTGGTGAACAGCAACTTGGTCTGC AAAGTGTCTGATTTTGGCATGTCCCGAGTGCTTGAGGATGATCCGGAAGCAGCTTACACC ACCAGGGGTGGCAAGATTCCTATCCGGTGGACTGCGCCAGAAGCAATTGCCTATCGTAAA TTCACATCAGCAAGTGATGTATGGAGCTATGGAATCGTTATGTGGGAAGTGATGTCGTAC GGGGAGAGGCCCTATTGGGATATGTCCAATCAAGATGTGATTAAAGCCATTGAGGAAGGC TATCGGTTACCCCCTCCAATGGACTGCCCCATTGCGCTCCACCAGCTGATGCTAGACTGC TGGCAGAAGGAGAGGAGCGACAGGCCTAAATTTGGGCAGATTGTCAACATGTTGGACAAA CTCATCCGCAACCCCAACAGCTTGAAGAGGACAGGGACGGAGAGCTCCAGACCTAACACT GCCTTGTTGGATCCAAGCTCCCCTGAATTCTCTGCTGTGGTATCAGTGGGCGATTGGCTC CAGGCCATTAAAATGGACCGGTATAAGGATAACTTCACAGCTGCTGGTTATACCACACTA GAGGCTGTGGTGCACGTGAACCAGGAGGACCTGGCAAGAATTGGTATCACAGCCATCACG CACCAGAATAAGATTTTGAGCAGTGTCCAGGCAATGCGAACCCAAATGCAGCAGATGCAC GGCAGAATGGTTCCCGTC
Cloned ORF protein sequence for pF1KE3341 Download>KIEE3341 986 aa MAGIFYFALFSCLFGICDAVTGSRVYPANEVTLLDSRSVQGELGWIASPLEGGWEEVSIM DEKNTPIRTYQVCNVMEPSQNNWLRTDWITREGAQRVYIEIKFTLRDCNSLPGVMGTCKE TFNLYYYESDNDKERFIRENQFVKIDTIAADESFTQVDIGDRIMKLNTEIRDVGPLSKKG FYLAFQDVGACIALVSVRVFYKKCPLTVRNLAQFPDTITGADTSSLVEVRGSCVNNSEEK DVPKMYCGADGEWLVPIGNCLCNAGHEERSGECQACKIGYYKALSTDATCAKCPPHSYSV WEGATSCTCDRGFFRADNDAASMPCTRPPSAPLNLISNVNETSVNLEWSSPQNTGGRQDI SYNVVCKKCGAGDPSKCRPCGSGVHYTPQQNGLKTTKVSITDLLAHTNYTFEIWAVNGVS KYNPNPDQSVSVTVTTNQAAPSSIALVQAKEVTRYSVALAWLEPDRPNGVILEYEVKYYE KDQNERSYRIVRTAARNTDIKGLNPLTSYVFHVRARTAAGYGDFSEPLEVTTNTVPSRII GDGANSTVLLVSVSGSVVLVVILIAAFVISRRRSKYSKAKQEADEEKHLNQGVRTYVDPF TYEDPNQAVREFAKEIDASCIKIEKVIGVGEFGEVCSGRLKVPGKREICVAIKTLKAGYT DKQRRDFLSEASIMGQFDHPNIIHLEGVVTKCKPVMIITEYMENGSLDAFLRKNDGRFTV IQLVGMLRGIGSGMKYLSDMSYVHRDLAARNILVNSNLVCKVSDFGMSRVLEDDPEAAYT TRGGKIPIRWTAPEAIAYRKFTSASDVWSYGIVMWEVMSYGERPYWDMSNQDVIKAIEEG YRLPPPMDCPIALHQLMLDCWQKERSDRPKFGQIVNMLDKLIRNPNSLKRTGTESSRPNT ALLDPSSPEFSAVVSVGDWLQAIKMDRYKDNFTAAGYTTLEAVVHVNQEDLARIGITAIT HQNKILSSVQAMRTQMQQMHGRMVPV
Nucleotide Sequence (with vector) for pF1KE3341 Download>pF1KE3341 6071 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGCTGGGATT TTCTATTTCGCCCTATTTTCGTGTCTCTTCGGGATTTGCGACGCTGTCACAGGTTCCAGG GTATACCCCGCGAATGAAGTTACCTTATTGGATTCCAGATCTGTTCAGGGAGAACTTGGG TGGATAGCAAGCCCTCTGGAAGGAGGGTGGGAGGAAGTGAGTATCATGGATGAAAAAAAT ACACCAATCCGAACCTACCAAGTGTGCAATGTGATGGAACCCAGCCAGAATAACTGGCTA CGAACTGATTGGATCACCCGAGAAGGGGCTCAGAGGGTGTATATTGAGATTAAATTCACC TTGAGGGACTGCAATAGTCTTCCGGGCGTCATGGGGACTTGCAAGGAGACGTTTAACCTG TACTACTATGAATCAGACAACGACAAAGAGCGTTTCATCAGAGAGAACCAGTTTGTCAAA ATTGACACCATTGCTGCTGATGAGAGCTTCACCCAAGTGGACATTGGTGACAGAATCATG AAGCTGAACACCGAGATCCGGGATGTAGGGCCATTAAGCAAAAAGGGGTTTTACCTGGCT TTTCAGGATGTGGGGGCCTGCATCGCCCTGGTATCAGTCCGTGTGTTCTATAAAAAGTGT CCACTCACAGTCCGCAATCTGGCCCAGTTTCCTGACACCATCACAGGGGCTGATACGTCT TCCCTGGTGGAAGTTCGAGGCTCCTGTGTCAACAACTCAGAAGAGAAAGATGTGCCAAAA ATGTACTGTGGGGCAGATGGTGAATGGCTGGTACCCATTGGCAACTGCCTATGCAACGCT GGGCATGAGGAGCGGAGCGGAGAATGCCAAGCTTGCAAAATTGGATATTACAAGGCTCTC TCCACGGATGCCACCTGTGCCAAGTGCCCACCCCACAGCTACTCTGTCTGGGAAGGAGCC ACCTCGTGCACCTGTGACCGAGGCTTTTTCAGAGCTGACAACGATGCTGCCTCTATGCCC TGCACCCGTCCACCATCTGCTCCCCTGAACTTGATTTCAAATGTCAACGAGACATCTGTG AACTTGGAATGGAGTAGCCCTCAGAATACAGGTGGCCGCCAGGACATTTCCTATAATGTG GTATGCAAGAAATGTGGAGCTGGTGACCCCAGCAAGTGCCGACCCTGTGGAAGTGGGGTC CACTACACCCCACAGCAGAATGGCTTGAAGACCACCAAAGTCTCCATCACTGACCTCCTA GCTCATACCAATTACACCTTTGAAATCTGGGCTGTGAATGGAGTGTCCAAATATAACCCT AACCCAGACCAATCAGTTTCTGTCACTGTGACCACCAACCAAGCAGCACCATCATCCATT GCTTTGGTCCAGGCTAAAGAAGTCACAAGATACAGTGTGGCACTGGCTTGGCTGGAACCA GATCGGCCCAATGGGGTAATCCTGGAATATGAAGTCAAGTATTATGAGAAGGATCAGAAT GAGCGAAGCTATCGTATAGTTCGGACAGCTGCCAGGAACACAGATATCAAAGGCCTGAAC CCTCTCACTTCCTATGTTTTCCACGTGCGAGCCAGGACAGCAGCTGGCTATGGAGACTTC AGTGAGCCCTTGGAGGTTACAACCAACACAGTGCCTTCCCGGATCATTGGAGATGGGGCT AACTCCACAGTCCTTCTGGTCTCTGTCTCGGGCAGTGTGGTGCTGGTGGTAATTCTCATT GCAGCTTTTGTCATCAGCCGGAGACGGAGTAAATACAGTAAAGCCAAACAAGAAGCGGAT GAAGAGAAACATTTGAATCAAGGTGTAAGAACATATGTGGACCCCTTTACGTACGAAGAT CCCAACCAAGCAGTGCGAGAGTTTGCCAAAGAAATTGACGCATCCTGCATTAAGATTGAA AAAGTTATAGGAGTTGGTGAATTTGGTGAGGTATGCAGTGGGCGTCTCAAAGTGCCTGGC AAGAGAGAGATCTGTGTGGCTATCAAGACTCTGAAAGCTGGTTATACAGACAAACAGAGG AGAGACTTCCTGAGTGAGGCCAGCATCATGGGACAGTTTGACCATCCGAACATCATTCAC TTGGAAGGCGTGGTCACTAAATGTAAACCAGTAATGATCATAACAGAGTACATGGAGAAT GGCTCCTTGGATGCATTCCTCAGGAAAAATGATGGCAGATTTACAGTCATTCAGCTGGTG GGCATGCTTCGTGGCATTGGGTCTGGGATGAAGTATTTATCTGATATGAGCTATGTGCAT CGTGATCTGGCCGCACGGAACATCCTGGTGAACAGCAACTTGGTCTGCAAAGTGTCTGAT TTTGGCATGTCCCGAGTGCTTGAGGATGATCCGGAAGCAGCTTACACCACCAGGGGTGGC AAGATTCCTATCCGGTGGACTGCGCCAGAAGCAATTGCCTATCGTAAATTCACATCAGCA AGTGATGTATGGAGCTATGGAATCGTTATGTGGGAAGTGATGTCGTACGGGGAGAGGCCC TATTGGGATATGTCCAATCAAGATGTGATTAAAGCCATTGAGGAAGGCTATCGGTTACCC CCTCCAATGGACTGCCCCATTGCGCTCCACCAGCTGATGCTAGACTGCTGGCAGAAGGAG AGGAGCGACAGGCCTAAATTTGGGCAGATTGTCAACATGTTGGACAAACTCATCCGCAAC CCCAACAGCTTGAAGAGGACAGGGACGGAGAGCTCCAGACCTAACACTGCCTTGTTGGAT CCAAGCTCCCCTGAATTCTCTGCTGTGGTATCAGTGGGCGATTGGCTCCAGGCCATTAAA ATGGACCGGTATAAGGATAACTTCACAGCTGCTGGTTATACCACACTAGAGGCTGTGGTG CACGTGAACCAGGAGGACCTGGCAAGAATTGGTATCACAGCCATCACGCACCAGAATAAG ATTTTGAGCAGTGTCCAGGCAATGCGAACCCAAATGCAGCAGATGCACGGCAGAATGGTT CCCGTCGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGG CATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCAC CGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTT GCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTA TCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGT CCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTT CTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCT TCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAAC TGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAG ACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCC GCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGAT GCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTG TCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACG GGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTA TTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTA TCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTC GACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTC GATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGG CTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTG CCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGT GTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGC GGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGC ATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGA CCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCAC AGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAA CCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCA CAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGC GTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATA CCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTA TCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCA GCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGA CTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGG TGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGG TATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGG CAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAG AAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAA CGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGAT CCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAA ACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGG TTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTG GTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGC GTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAA ACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGAT ACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAG CGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGG TAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGG CTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGA GTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGC GGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGG ATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATG TATCCGCTCAT
 more Linker info
more Linker info
{kind=link}