


-
SpecieshumanProduct IDFXC30998Cloning SiteSgfI-PmeIGenBank AccessionGeneKIEE3542SymbolEPHA6
Alias : EHK-2, EHK2, EK12, EPA6, HEK12, PRO57066DescriptionEPH receptor A6, transcript variant 1Original Clone IDcp93542 Length: 3390 bp
Length: 3390 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 1130 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
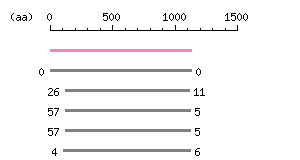
Entry Exp ID% symbol CCDS46876.1 1.9e-197 100.0 EPHA6 CCDS2922.1 2.1e-75 62.3 EPHA3 CCDS75131.1 6.7e-71 60.4 EPHA5 CCDS3514.1 1.3e-70 60.4 EPHA5 CCDS2447.1 1.2e-67 58.6 EPHA4
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan NULL 551 560 PR00014 NULL NULL 564 574 PR00014 NULL NULL 587 605 PR00014 NULL NULL 605 619 PR00014 NULL IPR001245 845 858 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 882 900 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 932 942 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 951 973 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 995 1017 PR00109 Serine-threonine/tyrosine-protein kinase HMMPfam IPR001090 128 301 PF01404 Ephrin receptor IPR003961 427 518 PF00041 Fibronectin IPR003961 549 621 PF00041 Fibronectin IPR001245 838 1024 PF07714 Serine-threonine/tyrosine-protein kinase IPR021129 1059 1117 PF00536 Sterile alpha motif HMMSmart IPR001090 128 301 SM00615 Ephrin receptor IPR003961 426 518 SM00060 Fibronectin IPR003961 537 618 SM00060 Fibronectin IPR002290 725 1028 SM00220 Serine/threonine-protein kinase domain IPR020635 725 1024 SM00219 Tyrosine-protein kinase IPR001660 1052 1119 SM00454 Sterile alpha motif domain ProfileScan IPR003961 425 529 PS50853 Fibronectin IPR003961 533 628 PS50853 Fibronectin IPR000719 725 1038 PS50011 Protein kinase IPR001660 1059 1119 PS50105 Sterile alpha motif domain
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 642 ILVIATAAVGGFTLLVILTLFFL 664 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_001073917 1130 600066 100.0 100.0 XP_016861699 1104 600066 94.9 100.0 XP_006713655 1146 600066 98.6 100.0 XP_016861702 990 600066 98.4 86.2 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KE3542 Download>KIEE3542 3390 bp ATGCAATTCCCCTCGCCTCCAGCCGCGAGGAGCTCCCCGGCGCCGCAGGCAGCGTCCTCC TCCGAAGCAGCTGCACCTGCAACTGGGCAGCCTGGACCCTCGTGCCCTGTTCCCGGGACC TCGCGCAGGGGGCGCCCCGGGACACCCCCTGCGGGCCGGGTGGAGGAGGAAGAGGAGGAG GAGGAAGAAGACGTGGACAAGGACCCCCATCCTACCCAGAACACCTGCCTGCGCTGCCGC CACTTCTCTTTAAGGGAGAGGAAAAGAGAGCCTAGGAGAACCATGGGGGGCTGCGAAGTC CGGGAATTTCTTTTGCAATTTGGTTTCTTCTTGCCTCTGCTGACAGCGTGGCCAGGCGAC TGCAGTCACGTCTCCAACAACCAAGTTGTGTTGCTTGATACAACAACTGTACTGGGAGAG CTAGGATGGAAAACATATCCATTAAATGGGTGGGATGCCATCACTGAAATGGATGAACAT AATAGGCCCATTCACACATACCAGGTATGTAATGTAATGGAACCAAACCAAAACAACTGG CTTCGTACAAACTGGATCTCCCGTGATGCAGCTCAGAAAATTTATGTGGAAATGAAATTC ACACTAAGGGATTGTAACAGCATCCCATGGGTCTTGGGGACTTGCAAAGAAACATTTAAT CTGTTTTATATGGAATCAGATGAGTCCCACGGAATTAAATTCAAGCCAAACCAGTATACA AAGATCGACACAATTGCTGCTGATGAGAGTTTTACCCAGATGGATTTGGGTGATCGCATC CTCAAACTCAACACTGAAATTCGTGAGGTGGGGCCTATAGAAAGGAAAGGATTTTATCTG GCTTTTCAAGACATTGGGGCGTGCATTGCCCTGGTTTCAGTCCGTGTTTTCTACAAGAAA TGCCCCTTCACTGTTCGTAACTTGGCCATGTTTCCTGATACCATTCCAAGGGTTGATTCC TCCTCTTTGGTTGAAGTACGGGGTTCTTGTGTGAAGAGTGCTGAAGAGCGTGACACTCCT AAACTGTATTGTGGAGCTGATGGAGATTGGCTGGTTCCTCTTGGAAGGTGCATCTGCAGT ACAGGATATGAAGAAATTGAGGGTTCTTGCCATGCTTGCAGACCAGGATTCTATAAAGCT TTTGCTGGGAACACAAAATGTTCTAAATGTCCTCCACACAGTTTAACATACATGGAAGCA ACTTCTGTCTGTCAGTGTGAAAAGGGTTATTTCCGAGCTGAAAAAGACCCACCTTCTATG GCATGTACCAGGCCACCTTCAGCTCCTAGGAATGTGGTTTTTAACATCAATGAAACAGCC CTTATTTTGGAATGGAGCCCACCAAGTGACACAGGAGGGAGAAAAGATCTCACATACAGT GTAATCTGTAAGAAATGTGGCTTAGACACCAGCCAGTGTGAGGACTGTGGTGGAGGACTC CGCTTCATCCCAAGACATACAGGCCTGATCAACAATTCCGTGATAGTACTTGACTTTGTG TCTCACGTGAATTACACCTTTGAAATAGAAGCAATGAATGGAGTTTCTGAGTTGAGTTTT TCTCCCAAGCCATTCACAGCTATTACAGTGACCACGGATCAAGATGCACCTTCCCTGATA GGTGTGGTAAGGAAGGACTGGGCATCCCAAAATAGCATTGCCCTATCATGGCAAGCACCT GCTTTTTCCAATGGAGCCATTCTGGACTACGAGATCAAGTACTATGAGAAAGAACATGAG CAGCTGACCTACTCTTCCACAAGGTCCAAAGCCCCCAGTGTCATCATCACAGGTCTTAAG CCAGCCACCAAATATGTATTTCACATCCGAGTGAGAACTGCGACAGGATACAGTGGCTAC AGTCAGAAATTTGAATTTGAAACAGGAGATGAAACTTCTGACATGGCAGCAGAACAAGGA CAGATTCTCGTGATAGCCACCGCCGCTGTTGGCGGATTCACTCTCCTCGTCATCCTCACT TTATTCTTCTTGATCACTGGGAGATGTCAGTGGTACATAAAAGCCAAGATGAAGTCAGAA GAGAAGAGAAGAAACCACTTACAGAATGGGCATTTGCGCTTCCCGGGAATTAAAACTTAC ATTGATCCAGATACATATGAAGACCCATCCCTAGCAGTCCATGAATTTGCAAAGGAGATT GATCCCTCAAGAATTCGTATTGAGAGAGTCATTGGGGCAGGTGAATTTGGAGAAGTCTGT AGTGGGCGTTTGAAGACACCAGGGAAAAGAGAGATCCCAGTTGCCATTAAAACTTTGAAA GGTGGCCACATGGATCGGCAAAGAAGAGATTTTCTAAGAGAAGCTAGTATCATGGGCCAG TTTGACCATCCAAACATCATTCGCCTAGAAGGGGTTGTCACCAAAAGATCCTTCCCGGCC ATTGGGGTGGAGGCGTTTTGCCCCAGCTTCCTGAGGGCAGGGTTTTTAAATAGCATCCAG GCCCCGCATCCAGTGCCAGGGGGAGGATCTTTGCCCCCCAGGATTCCTGCTGGCAGACCA GTAATGATTGTGGTGGAATATATGGAGAATGGATCCCTAGACTCCTTTTTGCGGAAGCAT GATGGCCACTTCACAGTCATCCAGTTGGTCGGAATGCTCCGAGGCATTGCATCAGGCATG AAGTATCTTTCTGATATGGGTTATGTTCATCGAGACCTAGCGGCTCGGAATATACTGGTC AATAGCAACTTAGTATGCAAAGTTTCTGATTTTGGTCTCTCCAGAGTGCTGGAAGATGAT CCAGAAGCTGCTTATACAACAACTGGTGGAAAAATCCCCATAAGGTGGACAGCCCCAGAA GCCATCGCCTACAGAAAATTCTCCTCAGCAAGCGATGCATGGAGCTATGGCATTGTCATG TGGGAGGTCATGTCCTATGGAGAGAGACCTTATTGGGAAATGTCTAACCAAGATGTCATT CTGTCCATTGAAGAAGGGTACAGACTTCCAGCTCCCATGGGCTGTCCAGCATCTCTACAC CAGCTGATGCTCCACTGCTGGCAGAAGGAGAGAAATCACAGACCAAAATTTACTGACATT GTCAGCTTCCTTGACAAACTGATCCGAAATCCCAGTGCCCTTCACACCCTGGTGGAGGAC ATCCTTGTAATGCCAGAGTCCCCTGGTGAAGTTCCGGAATATCCTTTGTTTGTCACAGTT GGTGACTGGCTAGATTCTATAAAGATGGGGCAATACAAGAATAACTTCGTGGCAGCAGGG TTTACAACATTTGACCTGATTTCAAGAATGAGCATTGATGACATTAGAAGAATTGGAGTC ATACTTATTGGACACCAGAGACGAATAGTCAGCAGCATACAGACTTTACGTTTACACATG ATGCACATACAGGAGAAGGGATTTCATGTA
Cloned ORF protein sequence for pF1KE3542 Download>KIEE3542 1130 aa MQFPSPPAARSSPAPQAASSSEAAAPATGQPGPSCPVPGTSRRGRPGTPPAGRVEEEEEE EEEDVDKDPHPTQNTCLRCRHFSLRERKREPRRTMGGCEVREFLLQFGFFLPLLTAWPGD CSHVSNNQVVLLDTTTVLGELGWKTYPLNGWDAITEMDEHNRPIHTYQVCNVMEPNQNNW LRTNWISRDAAQKIYVEMKFTLRDCNSIPWVLGTCKETFNLFYMESDESHGIKFKPNQYT KIDTIAADESFTQMDLGDRILKLNTEIREVGPIERKGFYLAFQDIGACIALVSVRVFYKK CPFTVRNLAMFPDTIPRVDSSSLVEVRGSCVKSAEERDTPKLYCGADGDWLVPLGRCICS TGYEEIEGSCHACRPGFYKAFAGNTKCSKCPPHSLTYMEATSVCQCEKGYFRAEKDPPSM ACTRPPSAPRNVVFNINETALILEWSPPSDTGGRKDLTYSVICKKCGLDTSQCEDCGGGL RFIPRHTGLINNSVIVLDFVSHVNYTFEIEAMNGVSELSFSPKPFTAITVTTDQDAPSLI GVVRKDWASQNSIALSWQAPAFSNGAILDYEIKYYEKEHEQLTYSSTRSKAPSVIITGLK PATKYVFHIRVRTATGYSGYSQKFEFETGDETSDMAAEQGQILVIATAAVGGFTLLVILT LFFLITGRCQWYIKAKMKSEEKRRNHLQNGHLRFPGIKTYIDPDTYEDPSLAVHEFAKEI DPSRIRIERVIGAGEFGEVCSGRLKTPGKREIPVAIKTLKGGHMDRQRRDFLREASIMGQ FDHPNIIRLEGVVTKRSFPAIGVEAFCPSFLRAGFLNSIQAPHPVPGGGSLPPRIPAGRP VMIVVEYMENGSLDSFLRKHDGHFTVIQLVGMLRGIASGMKYLSDMGYVHRDLAARNILV NSNLVCKVSDFGLSRVLEDDPEAAYTTTGGKIPIRWTAPEAIAYRKFSSASDAWSYGIVM WEVMSYGERPYWEMSNQDVILSIEEGYRLPAPMGCPASLHQLMLHCWQKERNHRPKFTDI VSFLDKLIRNPSALHTLVEDILVMPESPGEVPEYPLFVTVGDWLDSIKMGQYKNNFVAAG FTTFDLISRMSIDDIRRIGVILIGHQRRIVSSIQTLRLHMMHIQEKGFHV
Nucleotide Sequence (with vector) for pF1KE3542 Download>pF1KE3542 6503 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGCAATTCCCC TCGCCTCCAGCCGCGAGGAGCTCCCCGGCGCCGCAGGCAGCGTCCTCCTCCGAAGCAGCT GCACCTGCAACTGGGCAGCCTGGACCCTCGTGCCCTGTTCCCGGGACCTCGCGCAGGGGG CGCCCCGGGACACCCCCTGCGGGCCGGGTGGAGGAGGAAGAGGAGGAGGAGGAAGAAGAC GTGGACAAGGACCCCCATCCTACCCAGAACACCTGCCTGCGCTGCCGCCACTTCTCTTTA AGGGAGAGGAAAAGAGAGCCTAGGAGAACCATGGGGGGCTGCGAAGTCCGGGAATTTCTT TTGCAATTTGGTTTCTTCTTGCCTCTGCTGACAGCGTGGCCAGGCGACTGCAGTCACGTC TCCAACAACCAAGTTGTGTTGCTTGATACAACAACTGTACTGGGAGAGCTAGGATGGAAA ACATATCCATTAAATGGGTGGGATGCCATCACTGAAATGGATGAACATAATAGGCCCATT CACACATACCAGGTATGTAATGTAATGGAACCAAACCAAAACAACTGGCTTCGTACAAAC TGGATCTCCCGTGATGCAGCTCAGAAAATTTATGTGGAAATGAAATTCACACTAAGGGAT TGTAACAGCATCCCATGGGTCTTGGGGACTTGCAAAGAAACATTTAATCTGTTTTATATG GAATCAGATGAGTCCCACGGAATTAAATTCAAGCCAAACCAGTATACAAAGATCGACACA ATTGCTGCTGATGAGAGTTTTACCCAGATGGATTTGGGTGATCGCATCCTCAAACTCAAC ACTGAAATTCGTGAGGTGGGGCCTATAGAAAGGAAAGGATTTTATCTGGCTTTTCAAGAC ATTGGGGCGTGCATTGCCCTGGTTTCAGTCCGTGTTTTCTACAAGAAATGCCCCTTCACT GTTCGTAACTTGGCCATGTTTCCTGATACCATTCCAAGGGTTGATTCCTCCTCTTTGGTT GAAGTACGGGGTTCTTGTGTGAAGAGTGCTGAAGAGCGTGACACTCCTAAACTGTATTGT GGAGCTGATGGAGATTGGCTGGTTCCTCTTGGAAGGTGCATCTGCAGTACAGGATATGAA GAAATTGAGGGTTCTTGCCATGCTTGCAGACCAGGATTCTATAAAGCTTTTGCTGGGAAC ACAAAATGTTCTAAATGTCCTCCACACAGTTTAACATACATGGAAGCAACTTCTGTCTGT CAGTGTGAAAAGGGTTATTTCCGAGCTGAAAAAGACCCACCTTCTATGGCATGTACCAGG CCACCTTCAGCTCCTAGGAATGTGGTTTTTAACATCAATGAAACAGCCCTTATTTTGGAA TGGAGCCCACCAAGTGACACAGGAGGGAGAAAAGATCTCACATACAGTGTAATCTGTAAG AAATGTGGCTTAGACACCAGCCAGTGTGAGGACTGTGGTGGAGGACTCCGCTTCATCCCA AGACATACAGGCCTGATCAACAATTCCGTGATAGTACTTGACTTTGTGTCTCACGTGAAT TACACCTTTGAAATAGAAGCAATGAATGGAGTTTCTGAGTTGAGTTTTTCTCCCAAGCCA TTCACAGCTATTACAGTGACCACGGATCAAGATGCACCTTCCCTGATAGGTGTGGTAAGG AAGGACTGGGCATCCCAAAATAGCATTGCCCTATCATGGCAAGCACCTGCTTTTTCCAAT GGAGCCATTCTGGACTACGAGATCAAGTACTATGAGAAAGAACATGAGCAGCTGACCTAC TCTTCCACAAGGTCCAAAGCCCCCAGTGTCATCATCACAGGTCTTAAGCCAGCCACCAAA TATGTATTTCACATCCGAGTGAGAACTGCGACAGGATACAGTGGCTACAGTCAGAAATTT GAATTTGAAACAGGAGATGAAACTTCTGACATGGCAGCAGAACAAGGACAGATTCTCGTG ATAGCCACCGCCGCTGTTGGCGGATTCACTCTCCTCGTCATCCTCACTTTATTCTTCTTG ATCACTGGGAGATGTCAGTGGTACATAAAAGCCAAGATGAAGTCAGAAGAGAAGAGAAGA AACCACTTACAGAATGGGCATTTGCGCTTCCCGGGAATTAAAACTTACATTGATCCAGAT ACATATGAAGACCCATCCCTAGCAGTCCATGAATTTGCAAAGGAGATTGATCCCTCAAGA ATTCGTATTGAGAGAGTCATTGGGGCAGGTGAATTTGGAGAAGTCTGTAGTGGGCGTTTG AAGACACCAGGGAAAAGAGAGATCCCAGTTGCCATTAAAACTTTGAAAGGTGGCCACATG GATCGGCAAAGAAGAGATTTTCTAAGAGAAGCTAGTATCATGGGCCAGTTTGACCATCCA AACATCATTCGCCTAGAAGGGGTTGTCACCAAAAGATCCTTCCCGGCCATTGGGGTGGAG GCGTTTTGCCCCAGCTTCCTGAGGGCAGGGTTTTTAAATAGCATCCAGGCCCCGCATCCA GTGCCAGGGGGAGGATCTTTGCCCCCCAGGATTCCTGCTGGCAGACCAGTAATGATTGTG GTGGAATATATGGAGAATGGATCCCTAGACTCCTTTTTGCGGAAGCATGATGGCCACTTC ACAGTCATCCAGTTGGTCGGAATGCTCCGAGGCATTGCATCAGGCATGAAGTATCTTTCT GATATGGGTTATGTTCATCGAGACCTAGCGGCTCGGAATATACTGGTCAATAGCAACTTA GTATGCAAAGTTTCTGATTTTGGTCTCTCCAGAGTGCTGGAAGATGATCCAGAAGCTGCT TATACAACAACTGGTGGAAAAATCCCCATAAGGTGGACAGCCCCAGAAGCCATCGCCTAC AGAAAATTCTCCTCAGCAAGCGATGCATGGAGCTATGGCATTGTCATGTGGGAGGTCATG TCCTATGGAGAGAGACCTTATTGGGAAATGTCTAACCAAGATGTCATTCTGTCCATTGAA GAAGGGTACAGACTTCCAGCTCCCATGGGCTGTCCAGCATCTCTACACCAGCTGATGCTC CACTGCTGGCAGAAGGAGAGAAATCACAGACCAAAATTTACTGACATTGTCAGCTTCCTT GACAAACTGATCCGAAATCCCAGTGCCCTTCACACCCTGGTGGAGGACATCCTTGTAATG CCAGAGTCCCCTGGTGAAGTTCCGGAATATCCTTTGTTTGTCACAGTTGGTGACTGGCTA GATTCTATAAAGATGGGGCAATACAAGAATAACTTCGTGGCAGCAGGGTTTACAACATTT GACCTGATTTCAAGAATGAGCATTGATGACATTAGAAGAATTGGAGTCATACTTATTGGA CACCAGAGACGAATAGTCAGCAGCATACAGACTTTACGTTTACACATGATGCACATACAG GAGAAGGGATTTCATGTAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAG TCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTT GGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTT GAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGC CCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGC GTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTG CGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCG GCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCC TGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGA TCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCA GGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATC GGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTC AAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGG CTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGG GACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCT GCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCT ACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAA GCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAA CTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGC GATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGT GGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCT GAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCC GATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGG GGTTCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAAT ACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCA AAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCC TGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATA AAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCC GCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTC ACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGA ACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCC GGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAG GTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAG GACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAG CTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCA GATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGA CGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGAT CTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGC TGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCC TGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCA GTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCG TTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAG CCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCT TTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCC TGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCG TAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAA TAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGA ACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGC CCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGG CCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATA CATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}