


-
SpecieshumanProduct IDFXC09635Cloning SiteSgfI-PmeIGenBank AccessionGeneKIEE3662SymbolEPHA2
Alias : ARCC2, CTPA, CTPP1, CTRCT6, ECKDescriptionEPH receptor A2Original Clone IDoc93662 Length: 2928 bp
Length: 2928 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 976 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
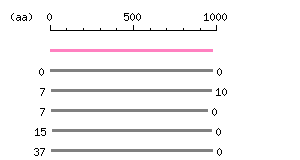
Entry Exp ID% symbol CCDS169.1 9e-189 100.0 EPHA2 CCDS2447.1 3.5e-92 52.3 EPHA4 CCDS86924.1 2.4e-90 52.9 EPHA4 CCDS5884.1 1e-80 50.7 EPHA1 CCDS3514.1 1.1e-77 53.4 EPHA5
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]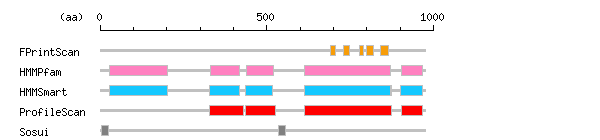 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR001245 692 705 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 729 747 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 779 789 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 798 820 PR00109 Serine-threonine/tyrosine-protein kinase IPR001245 842 864 PR00109 Serine-threonine/tyrosine-protein kinase HMMPfam IPR001090 28 201 PF01404 Ephrin receptor IPR003961 330 419 PF00041 Fibronectin IPR003961 438 519 PF00041 Fibronectin IPR001245 614 871 PF07714 Serine-threonine/tyrosine-protein kinase IPR021129 904 966 PF00536 Sterile alpha motif HMMSmart IPR001090 28 201 SM00615 Ephrin receptor IPR003961 329 419 SM00060 Fibronectin IPR003961 436 516 SM00060 Fibronectin IPR002290 613 875 SM00220 Serine/threonine-protein kinase domain IPR020635 613 871 SM00219 Tyrosine-protein kinase IPR001660 901 968 SM00454 Sterile alpha motif domain ProfileScan IPR003961 328 429 PS50853 Fibronectin IPR003961 435 526 PS50853 Fibronectin IPR000719 613 875 PS50011 Protein kinase IPR001660 904 968 PS50105 Sterile alpha motif domain
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 4 QAARACFALLWGCALAAAAAAQ 25 PRIMARY 22 2 535 LAVIGGVAVGVVLLLVLAGVGFF 557 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_004422 976 116600,176946 100.0 100.0 NP_001316019 922 116600,176946 100.0 94.5 XP_016865854 989 602190 51.7 98.5 NP_004429 986 602188 52.3 98.6 NP_001291465 986 602188 52.3 98.6 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KE3662 Download>KIEE3662 2928 bp ATGGAGCTCCAGGCAGCCCGCGCCTGCTTCGCCCTGCTGTGGGGCTGTGCGCTGGCCGCG GCCGCGGCGGCGCAGGGCAAGGAAGTGGTACTGCTGGACTTTGCTGCAGCTGGAGGGGAG CTCGGCTGGCTCACACACCCGTATGGCAAAGGGTGGGACCTGATGCAGAACATCATGAAT GACATGCCGATCTACATGTACTCCGTGTGCAACGTGATGTCTGGCGACCAGGACAACTGG CTCCGCACCAACTGGGTGTACCGAGGAGAGGCTGAGCGTATCTTCATTGAGCTCAAGTTT ACTGTACGTGACTGCAACAGCTTCCCTGGTGGCGCCAGCTCCTGCAAGGAGACTTTCAAC CTCTACTATGCCGAGTCGGACCTGGACTACGGCACCAACTTCCAGAAGCGCCTGTTCACC AAGATTGACACCATTGCGCCCGATGAGATCACCGTCAGCAGCGACTTCGAGGCACGCCAC GTGAAGCTGAACGTGGAGGAGCGCTCCGTGGGGCCGCTCACCCGCAAAGGCTTCTACCTG GCCTTCCAGGATATCGGTGCCTGTGTGGCGCTGCTCTCCGTCCGTGTCTACTACAAGAAG TGCCCCGAGCTGCTGCAGGGCCTGGCCCACTTCCCTGAGACCATCGCCGGCTCTGATGCA CCTTCCCTGGCCACTGTGGCCGGCACCTGTGTGGACCATGCCGTGGTGCCACCGGGGGGT GAAGAGCCCCGTATGCACTGTGCAGTGGATGGCGAGTGGCTGGTGCCCATTGGGCAGTGC CTGTGCCAGGCAGGCTACGAGAAGGTGGAGGATGCCTGCCAGGCCTGCTCGCCTGGATTT TTTAAGTTTGAGGCATCTGAGAGCCCCTGCTTGGAGTGCCCTGAGCACACGCTGCCATCC CCTGAGGGTGCCACCTCCTGCGAGTGTGAGGAAGGCTTCTTCCGGGCACCTCAGGACCCA GCGTCGATGCCTTGCACACGACCCCCCTCCGCCCCACACTACCTCACAGCCGTGGGCATG GGTGCCAAGGTGGAGCTGCGCTGGACGCCCCCTCAGGACAGCGGGGGCCGCGAGGACATT GTCTACAGCGTCACCTGCGAACAGTGCTGGCCCGAGTCTGGGGAATGCGGGCCGTGTGAG GCCAGTGTGCGCTACTCGGAGCCTCCTCACGGACTGACCCGCACCAGTGTGACAGTGAGC GACCTGGAGCCCCACATGAACTACACCTTCACCGTGGAGGCCCGCAATGGCGTCTCAGGC CTGGTAACCAGCCGCAGCTTCCGTACTGCCAGTGTCAGCATCAACCAGACAGAGCCCCCC AAGGTGAGGCTGGAGGGCCGCAGCACCACCTCGCTTAGCGTCTCCTGGAGCATCCCCCCG CCGCAGCAGAGCCGAGTGTGGAAGTACGAGGTCACTTACCGCAAGAAGGGAGACTCCAAC AGCTACAATGTGCGCCGCACCGAGGGTTTCTCCGTGACCCTGGACGACCTGGCCCCAGAC ACCACCTACCTGGTCCAGGTGCAGGCACTGACGCAGGAGGGCCAGGGGGCCGGCAGCAAG GTGCACGAATTCCAGACGCTGTCCCCGGAGGGATCTGGCAACTTGGCGGTGATTGGCGGC GTGGCTGTCGGTGTGGTCCTGCTTCTGGTGCTGGCAGGAGTTGGCTTCTTTATCCACCGC AGGAGGAAGAACCAGCGTGCCCGCCAGTCCCCGGAGGACGTTTACTTCTCCAAGTCAGAA CAACTGAAGCCCCTGAAGACATACGTGGACCCCCACACATATGAGGACCCCAACCAGGCT GTGTTGAAGTTCACTACCGAGATCCATCCATCCTGTGTCACTCGGCAGAAGGTGATCGGA GCAGGAGAGTTTGGGGAGGTGTACAAGGGCATGCTGAAGACATCCTCGGGGAAGAAGGAG GTGCCGGTGGCCATCAAGACGCTGAAAGCCGGCTACACAGAGAAGCAGCGAGTGGACTTC CTCGGCGAGGCCGGCATCATGGGCCAGTTCAGCCACCACAACATCATCCGCCTAGAGGGC GTCATCTCCAAATACAAGCCCATGATGATCATCACTGAGTACATGGAGAATGGGGCCCTG GACAAGTTCCTTCGGGAGAAGGATGGCGAGTTCAGCGTGCTGCAGCTGGTGGGCATGCTG CGGGGCATCGCAGCTGGCATGAAGTACCTGGCCAACATGAACTATGTGCACCGTGACCTG GCTGCCCGCAACATCCTCGTCAACAGCAACCTGGTCTGCAAGGTGTCTGACTTTGGCCTG TCCCGCGTGCTGGAGGACGACCCCGAGGCCACCTACACCACCAGTGGCGGCAAGATCCCC ATCCGCTGGACCGCCCCGGAGGCCATTTCCTACCGGAAGTTCACCTCTGCCAGCGACGTG TGGAGCTTTGGCATTGTCATGTGGGAGGTGATGACCTATGGCGAGCGGCCCTACTGGGAG TTGTCCAACCACGAGGTGATGAAAGCCATCAATGATGGCTTCCGGCTCCCCACACCCATG GACTGCCCCTCCGCCATCTACCAGCTCATGATGCAGTGCTGGCAGCAGGAGCGTGCCCGC CGCCCCAAGTTCGCTGACATCGTCAGCATCCTGGACAAGCTCATTCGTGCCCCTGACTCC CTCAAGACCCTGGCTGACTTTGACCCCCGCGTGTCTATCCGGCTCCCCAGCACGAGCGGC TCGGAGGGGGTGCCCTTCCGCACGGTGTCCGAGTGGCTGGAGTCCATCAAGATGCAGCAG TATACGGAGCACTTCATGGCGGCCGGCTACACTGCCATCGAGAAGGTGGTGCAGATGACC AACGACGACATCAAGAGGATTGGGGTGCGGCTGCCCGGCCACCAGAAGCGCATCGCCTAC AGCCTGCTGGGACTCAAGGACCAGGTGAACACTGTGGGGATCCCCATC
Cloned ORF protein sequence for pF1KE3662 Download>KIEE3662 976 aa MELQAARACFALLWGCALAAAAAAQGKEVVLLDFAAAGGELGWLTHPYGKGWDLMQNIMN DMPIYMYSVCNVMSGDQDNWLRTNWVYRGEAERIFIELKFTVRDCNSFPGGASSCKETFN LYYAESDLDYGTNFQKRLFTKIDTIAPDEITVSSDFEARHVKLNVEERSVGPLTRKGFYL AFQDIGACVALLSVRVYYKKCPELLQGLAHFPETIAGSDAPSLATVAGTCVDHAVVPPGG EEPRMHCAVDGEWLVPIGQCLCQAGYEKVEDACQACSPGFFKFEASESPCLECPEHTLPS PEGATSCECEEGFFRAPQDPASMPCTRPPSAPHYLTAVGMGAKVELRWTPPQDSGGREDI VYSVTCEQCWPESGECGPCEASVRYSEPPHGLTRTSVTVSDLEPHMNYTFTVEARNGVSG LVTSRSFRTASVSINQTEPPKVRLEGRSTTSLSVSWSIPPPQQSRVWKYEVTYRKKGDSN SYNVRRTEGFSVTLDDLAPDTTYLVQVQALTQEGQGAGSKVHEFQTLSPEGSGNLAVIGG VAVGVVLLLVLAGVGFFIHRRRKNQRARQSPEDVYFSKSEQLKPLKTYVDPHTYEDPNQA VLKFTTEIHPSCVTRQKVIGAGEFGEVYKGMLKTSSGKKEVPVAIKTLKAGYTEKQRVDF LGEAGIMGQFSHHNIIRLEGVISKYKPMMIITEYMENGALDKFLREKDGEFSVLQLVGML RGIAAGMKYLANMNYVHRDLAARNILVNSNLVCKVSDFGLSRVLEDDPEATYTTSGGKIP IRWTAPEAISYRKFTSASDVWSFGIVMWEVMTYGERPYWELSNHEVMKAINDGFRLPTPM DCPSAIYQLMMQCWQQERARRPKFADIVSILDKLIRAPDSLKTLADFDPRVSIRLPSTSG SEGVPFRTVSEWLESIKMQQYTEHFMAAGYTAIEKVVQMTNDDIKRIGVRLPGHQKRIAY SLLGLKDQVNTVGIPI
Nucleotide Sequence (with vector) for pF1KE3662 Download>pF1KE3662 6041 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGAGCTCCAG GCAGCCCGCGCCTGCTTCGCCCTGCTGTGGGGCTGTGCGCTGGCCGCGGCCGCGGCGGCG CAGGGCAAGGAAGTGGTACTGCTGGACTTTGCTGCAGCTGGAGGGGAGCTCGGCTGGCTC ACACACCCGTATGGCAAAGGGTGGGACCTGATGCAGAACATCATGAATGACATGCCGATC TACATGTACTCCGTGTGCAACGTGATGTCTGGCGACCAGGACAACTGGCTCCGCACCAAC TGGGTGTACCGAGGAGAGGCTGAGCGTATCTTCATTGAGCTCAAGTTTACTGTACGTGAC TGCAACAGCTTCCCTGGTGGCGCCAGCTCCTGCAAGGAGACTTTCAACCTCTACTATGCC GAGTCGGACCTGGACTACGGCACCAACTTCCAGAAGCGCCTGTTCACCAAGATTGACACC ATTGCGCCCGATGAGATCACCGTCAGCAGCGACTTCGAGGCACGCCACGTGAAGCTGAAC GTGGAGGAGCGCTCCGTGGGGCCGCTCACCCGCAAAGGCTTCTACCTGGCCTTCCAGGAT ATCGGTGCCTGTGTGGCGCTGCTCTCCGTCCGTGTCTACTACAAGAAGTGCCCCGAGCTG CTGCAGGGCCTGGCCCACTTCCCTGAGACCATCGCCGGCTCTGATGCACCTTCCCTGGCC ACTGTGGCCGGCACCTGTGTGGACCATGCCGTGGTGCCACCGGGGGGTGAAGAGCCCCGT ATGCACTGTGCAGTGGATGGCGAGTGGCTGGTGCCCATTGGGCAGTGCCTGTGCCAGGCA GGCTACGAGAAGGTGGAGGATGCCTGCCAGGCCTGCTCGCCTGGATTTTTTAAGTTTGAG GCATCTGAGAGCCCCTGCTTGGAGTGCCCTGAGCACACGCTGCCATCCCCTGAGGGTGCC ACCTCCTGCGAGTGTGAGGAAGGCTTCTTCCGGGCACCTCAGGACCCAGCGTCGATGCCT TGCACACGACCCCCCTCCGCCCCACACTACCTCACAGCCGTGGGCATGGGTGCCAAGGTG GAGCTGCGCTGGACGCCCCCTCAGGACAGCGGGGGCCGCGAGGACATTGTCTACAGCGTC ACCTGCGAACAGTGCTGGCCCGAGTCTGGGGAATGCGGGCCGTGTGAGGCCAGTGTGCGC TACTCGGAGCCTCCTCACGGACTGACCCGCACCAGTGTGACAGTGAGCGACCTGGAGCCC CACATGAACTACACCTTCACCGTGGAGGCCCGCAATGGCGTCTCAGGCCTGGTAACCAGC CGCAGCTTCCGTACTGCCAGTGTCAGCATCAACCAGACAGAGCCCCCCAAGGTGAGGCTG GAGGGCCGCAGCACCACCTCGCTTAGCGTCTCCTGGAGCATCCCCCCGCCGCAGCAGAGC CGAGTGTGGAAGTACGAGGTCACTTACCGCAAGAAGGGAGACTCCAACAGCTACAATGTG CGCCGCACCGAGGGTTTCTCCGTGACCCTGGACGACCTGGCCCCAGACACCACCTACCTG GTCCAGGTGCAGGCACTGACGCAGGAGGGCCAGGGGGCCGGCAGCAAGGTGCACGAATTC CAGACGCTGTCCCCGGAGGGATCTGGCAACTTGGCGGTGATTGGCGGCGTGGCTGTCGGT GTGGTCCTGCTTCTGGTGCTGGCAGGAGTTGGCTTCTTTATCCACCGCAGGAGGAAGAAC CAGCGTGCCCGCCAGTCCCCGGAGGACGTTTACTTCTCCAAGTCAGAACAACTGAAGCCC CTGAAGACATACGTGGACCCCCACACATATGAGGACCCCAACCAGGCTGTGTTGAAGTTC ACTACCGAGATCCATCCATCCTGTGTCACTCGGCAGAAGGTGATCGGAGCAGGAGAGTTT GGGGAGGTGTACAAGGGCATGCTGAAGACATCCTCGGGGAAGAAGGAGGTGCCGGTGGCC ATCAAGACGCTGAAAGCCGGCTACACAGAGAAGCAGCGAGTGGACTTCCTCGGCGAGGCC GGCATCATGGGCCAGTTCAGCCACCACAACATCATCCGCCTAGAGGGCGTCATCTCCAAA TACAAGCCCATGATGATCATCACTGAGTACATGGAGAATGGGGCCCTGGACAAGTTCCTT CGGGAGAAGGATGGCGAGTTCAGCGTGCTGCAGCTGGTGGGCATGCTGCGGGGCATCGCA GCTGGCATGAAGTACCTGGCCAACATGAACTATGTGCACCGTGACCTGGCTGCCCGCAAC ATCCTCGTCAACAGCAACCTGGTCTGCAAGGTGTCTGACTTTGGCCTGTCCCGCGTGCTG GAGGACGACCCCGAGGCCACCTACACCACCAGTGGCGGCAAGATCCCCATCCGCTGGACC GCCCCGGAGGCCATTTCCTACCGGAAGTTCACCTCTGCCAGCGACGTGTGGAGCTTTGGC ATTGTCATGTGGGAGGTGATGACCTATGGCGAGCGGCCCTACTGGGAGTTGTCCAACCAC GAGGTGATGAAAGCCATCAATGATGGCTTCCGGCTCCCCACACCCATGGACTGCCCCTCC GCCATCTACCAGCTCATGATGCAGTGCTGGCAGCAGGAGCGTGCCCGCCGCCCCAAGTTC GCTGACATCGTCAGCATCCTGGACAAGCTCATTCGTGCCCCTGACTCCCTCAAGACCCTG GCTGACTTTGACCCCCGCGTGTCTATCCGGCTCCCCAGCACGAGCGGCTCGGAGGGGGTG CCCTTCCGCACGGTGTCCGAGTGGCTGGAGTCCATCAAGATGCAGCAGTATACGGAGCAC TTCATGGCGGCCGGCTACACTGCCATCGAGAAGGTGGTGCAGATGACCAACGACGACATC AAGAGGATTGGGGTGCGGCTGCCCGGCCACCAGAAGCGCATCGCCTACAGCCTGCTGGGA CTCAAGGACCAGGTGAACACTGTGGGGATCCCCATCGTTTAAACGAATTCGAGCTCGGTA CCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGC CCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGG GGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCT TGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTG CTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCG GGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTT GCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCT GGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGA TGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAA CAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGAC TGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGG CGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAG GCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTT GTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTG TCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTG CATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGA GCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAG GGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGAT CTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTT TCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTG GCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTT TACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTC TTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGC TCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACAT GTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTT CCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCG AAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTC TCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGT GGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAA GCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTA TCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAA CAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAA CTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTT CGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTT TTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGAT CTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCAT GAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCA CGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTA AGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTA TCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCC GTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACT TACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGG CGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCT GATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAA CTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGG GAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTA TCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGA ACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGC ATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTT TGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}