


-
SpecieshumanProduct IDFXC27060Cloning SiteSgfI-PmeIGenBank AccessionGeneKIEE4235SymbolKCNB1
Alias : DEE26, DRK1, Kv2.1Descriptionpotassium channel, voltage gated Shab related subfamily B, member 1Original Clone IDcp94235 Length: 2574 bp
Length: 2574 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 858 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
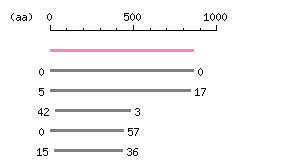
Entry Exp ID% symbol CCDS13418.1 0 100.0 KCNB1 CCDS6209.1 6.4e-154 63.6 KCNB2 CCDS6314.1 6e-59 45.9 KCNV1 CCDS1676.1 2.8e-57 42.3 KCNF1 CCDS12019.1 3.3e-49 39.8 KCNG2
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR003091 82 101 PR00169 Voltage-dependent potassium channel IPR003968 82 92 PR01491 Potassium channel IPR003973 130 143 PR01495 Potassium channel IPR003973 165 179 PR01495 Potassium channel IPR003091 182 210 PR00169 Voltage-dependent potassium channel IPR003091 231 254 PR00169 Voltage-dependent potassium channel IPR003973 253 266 PR01495 Potassium channel IPR003091 257 277 PR00169 Voltage-dependent potassium channel IPR003091 301 327 PR00169 Voltage-dependent potassium channel IPR003968 306 314 PR01491 Potassium channel IPR003091 330 353 PR00169 Voltage-dependent potassium channel IPR003968 330 344 PR01491 Potassium channel IPR003091 361 383 PR00169 Voltage-dependent potassium channel IPR003091 390 416 PR00169 Voltage-dependent potassium channel IPR003973 394 405 PR01495 Potassium channel IPR003968 401 412 PR01491 Potassium channel IPR003973 417 428 PR01495 Potassium channel IPR003973 451 466 PR01495 Potassium channel IPR004350 467 478 PR01514 Potassium channel IPR004350 508 520 PR01514 Potassium channel IPR004350 524 536 PR01514 Potassium channel IPR004350 538 549 PR01514 Potassium channel IPR004350 576 587 PR01514 Potassium channel IPR004350 726 737 PR01514 Potassium channel IPR004350 755 769 PR01514 Potassium channel HMMPfam IPR003131 33 132 PF02214 Potassium channel IPR005821 232 412 PF00520 Ion transport IPR003973 467 716 PF03521 Potassium channel HMMSmart IPR000210 31 140 SM00225 BTB/POZ-like
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 186 VAAKILAIISIMFIVLSTIALSL 208 PRIMARY 23 2 226 NPQLAHVEAVCIAWFTMEYLLRF 248 SECONDARY 23 3 259 KGPLNAIDLLAILPYYVTIFLTE 281 SECONDARY 23 4 330 ELGLLILFLAMGIMIFSSLVFF 351 PRIMARY 22 5 365 PASFWWATITMTTVGYGDIYPKT 387 SECONDARY 23 6 392 IVGGLCCIAGVLVIALPIPIIVN 414 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_004966 858 600397,616056 100.0 100.0 XP_006723847 858 600397,616056 100.0 100.0 XP_011527101 858 600397,616056 100.0 100.0 NP_004761 911 607738 63.6 97.9 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KE4235 Download>KIEE4235 2574 bp ATGCCGGCGGGCATGACGAAGCATGGCTCCCGCTCCACCAGCTCGCTGCCGCCCGAGCCC ATGGAGATCGTGCGCAGCAAGGCGTGCTCTCGGCGGGTCCGCCTCAACGTCGGGGGGCTG GCGCACGAGGTACTCTGGCGTACCCTGGACCGCCTGCCCCGCACGCGGCTGGGCAAGCTC CGCGACTGCAACACGCACGACTCGCTGCTCGAGGTGTGCGATGACTACAGCCTCGACGAC AACGAGTACTTCTTTGACCGCCACCCGGGCGCCTTCACCTCCATCCTCAACTTCTACCGC ACTGGGCGACTGCACATGATGGAGGAGATGTGCGCGCTCAGCTTCAGCCAAGAGCTCGAC TACTGGGGCATCGACGAGATCTACCTGGAGTCCTGCTGCCAGGCCCGCTACCACCAGAAG AAAGAGCAGATGAACGAGGAGCTCAAGCGTGAGGCCGAGACCCTACGGGAGCGGGAAGGC GAGGAGTTCGATAACACGTGCTGCGCAGAGAAGAGGAAAAAACTCTGGGACCTACTGGAG AAGCCCAATTCCTCTGTGGCTGCCAAGATCCTTGCCATAATTTCCATCATGTTCATCGTC CTCTCCACCATTGCCCTGTCCCTCAACACGCTGCCTGAGCTACAGAGCCTCGATGAGTTC GGCCAGTCCACAGACAACCCCCAGCTGGCCCACGTGGAGGCCGTGTGCATCGCATGGTTC ACCATGGAGTACCTGCTGAGGTTCCTCTCCTCGCCCAAGAAGTGGAAGTTCTTCAAGGGC CCACTCAATGCCATTGACTTGTTGGCCATTCTGCCATACTATGTCACCATTTTCCTCACC GAATCCAACAAGAGCGTGCTGCAATTCCAGAATGTCCGCCGCGTGGTCCAGATCTTCCGC ATCATGCGAATTCTCCGCATCCTTAAGCTTGCACGCCACTCCACTGGCCTCCAGTCTCTG GGCTTCACTTTGCGGAGGAGCTACAATGAGTTGGGCTTGCTCATCCTCTTCCTTGCCATG GGCATTATGATCTTCTCCAGCCTTGTCTTCTTTGCTGAGAAGGATGAGGACGACACCAAG TTCAAAAGCATCCCAGCCTCTTTCTGGTGGGCCACCATCACCATGACTACTGTTGGGTAT GGAGACATCTACCCCAAGACTCTCCTGGGGAAAATTGTTGGGGGACTCTGCTGCATTGCA GGAGTCCTGGTGATTGCTCTTCCCATCCCCATCATCGTCAATAACTTCTCTGAGTTCTAT AAGGAGCAGAAGAGACAGGAGAAAGCAATCAAACGGCGAGAGGCTCTGGAGAGAGCCAAG AGGAATGGCAGCATCGTATCCATGAACATGAAGGATGCTTTTGCCCGGAGCATTGAGATG ATGGACATTGTGGTTGAGAAAAATGGGGAGAATATGGGTAAGAAAGACAAAGTACAAGAT AACCACTTGTCTCCTAACAAATGGAAATGGACAAAGAGGACACTGTCTGAAACCAGCTCA AGTAAGTCCTTTGAAACCAAGGAACAGGGATCCCCTGAAAAAGCCAGATCGTCTTCTAGT CCTCAGCACCTGAACGTTCAGCAGTTGGAAGACATGTACAATAAGATGGCCAAGACCCAA TCCCAACCCATCCTCAATACCAAGGAGTCAGCAGCACAGAGCAAACCAAAGGAAGAACTT GAAATGGAGAGTATCCCCAGCCCCGTAGCCCCTCTGCCCACTCGCACAGAAGGGGTCATT GACATGCGAAGTATGTCAAGCATTGATAGTTTCATTAGCTGTGCCACAGACTTCCCTGAG GCCACCAGATTCTCCCACAGCCCTTTGACATCACTCCCCAGCAAGACTGGGGGCAGCACA GCCCCAGAAGTGGGCTGGCGGGGAGCTCTGGGTGCCAGTGGTGGTAGGTTTGTGGAGGCC AACCCCAGCCCTGATGCCAGCCAGCACTCTAGTTTCTTCATCGAGAGCCCCAAGAGTTCC ATGAAAACTAACAACCCTTTGAAGCTCCGAGCACTTAAAGTCAACTTCATGGAGGGTGAC CCCAGTCCACTCCTCCCCGTTCTAGGGATGTACCATGACCCTCTCAGGAACCGGGGGAGT GCTGCGGCTGCTGTCGCTGGACTGGAGTGTGCCACGCTTTTGGACAAGGCTGTGCTGAGC CCAGAGTCCTCCATCTACACCACAGCAAGTGCTAAGACACCCCCCCGGTCTCCTGAGAAA CACACAGCAATAGCGTTCAACTTTGAGGCGGGTGTCCACCAGTACATTGACGCAGACACA GATGATGAGGGACAGCTGCTCTACAGTGTGGACTCCAGCCCCCCCAAAAGCCTCCCTGGG AGCACCAGTCCGAAGTTCAGCACGGGGACAAGATCGGAGAAAAACCACTTTGAAAGCTCC CCTTTACCCACCTCCCCTAAGTTCTTAAGGCAGAACTGTATTTACTCCACAGAAGCATTG ACTGGAAAAGGCCCCAGTGGTCAGGAAAAGTGCAAACTTGAGAACCACATCTCCCCTGAC GTCCGTGTGTTGCCAGGGGGAGGAGCCCATGGAAGCACACGAGATCAGAGCATC
Cloned ORF protein sequence for pF1KE4235 Download>KIEE4235 858 aa MPAGMTKHGSRSTSSLPPEPMEIVRSKACSRRVRLNVGGLAHEVLWRTLDRLPRTRLGKL RDCNTHDSLLEVCDDYSLDDNEYFFDRHPGAFTSILNFYRTGRLHMMEEMCALSFSQELD YWGIDEIYLESCCQARYHQKKEQMNEELKREAETLREREGEEFDNTCCAEKRKKLWDLLE KPNSSVAAKILAIISIMFIVLSTIALSLNTLPELQSLDEFGQSTDNPQLAHVEAVCIAWF TMEYLLRFLSSPKKWKFFKGPLNAIDLLAILPYYVTIFLTESNKSVLQFQNVRRVVQIFR IMRILRILKLARHSTGLQSLGFTLRRSYNELGLLILFLAMGIMIFSSLVFFAEKDEDDTK FKSIPASFWWATITMTTVGYGDIYPKTLLGKIVGGLCCIAGVLVIALPIPIIVNNFSEFY KEQKRQEKAIKRREALERAKRNGSIVSMNMKDAFARSIEMMDIVVEKNGENMGKKDKVQD NHLSPNKWKWTKRTLSETSSSKSFETKEQGSPEKARSSSSPQHLNVQQLEDMYNKMAKTQ SQPILNTKESAAQSKPKEELEMESIPSPVAPLPTRTEGVIDMRSMSSIDSFISCATDFPE ATRFSHSPLTSLPSKTGGSTAPEVGWRGALGASGGRFVEANPSPDASQHSSFFIESPKSS MKTNNPLKLRALKVNFMEGDPSPLLPVLGMYHDPLRNRGSAAAAVAGLECATLLDKAVLS PESSIYTTASAKTPPRSPEKHTAIAFNFEAGVHQYIDADTDDEGQLLYSVDSSPPKSLPG STSPKFSTGTRSEKNHFESSPLPTSPKFLRQNCIYSTEALTGKGPSGQEKCKLENHISPD VRVLPGGGAHGSTRDQSI
Nucleotide Sequence (with vector) for pF1KE4235 Download>pF1KE4235 5687 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGCCGGCGGGC ATGACGAAGCATGGCTCCCGCTCCACCAGCTCGCTGCCGCCCGAGCCCATGGAGATCGTG CGCAGCAAGGCGTGCTCTCGGCGGGTCCGCCTCAACGTCGGGGGGCTGGCGCACGAGGTA CTCTGGCGTACCCTGGACCGCCTGCCCCGCACGCGGCTGGGCAAGCTCCGCGACTGCAAC ACGCACGACTCGCTGCTCGAGGTGTGCGATGACTACAGCCTCGACGACAACGAGTACTTC TTTGACCGCCACCCGGGCGCCTTCACCTCCATCCTCAACTTCTACCGCACTGGGCGACTG CACATGATGGAGGAGATGTGCGCGCTCAGCTTCAGCCAAGAGCTCGACTACTGGGGCATC GACGAGATCTACCTGGAGTCCTGCTGCCAGGCCCGCTACCACCAGAAGAAAGAGCAGATG AACGAGGAGCTCAAGCGTGAGGCCGAGACCCTACGGGAGCGGGAAGGCGAGGAGTTCGAT AACACGTGCTGCGCAGAGAAGAGGAAAAAACTCTGGGACCTACTGGAGAAGCCCAATTCC TCTGTGGCTGCCAAGATCCTTGCCATAATTTCCATCATGTTCATCGTCCTCTCCACCATT GCCCTGTCCCTCAACACGCTGCCTGAGCTACAGAGCCTCGATGAGTTCGGCCAGTCCACA GACAACCCCCAGCTGGCCCACGTGGAGGCCGTGTGCATCGCATGGTTCACCATGGAGTAC CTGCTGAGGTTCCTCTCCTCGCCCAAGAAGTGGAAGTTCTTCAAGGGCCCACTCAATGCC ATTGACTTGTTGGCCATTCTGCCATACTATGTCACCATTTTCCTCACCGAATCCAACAAG AGCGTGCTGCAATTCCAGAATGTCCGCCGCGTGGTCCAGATCTTCCGCATCATGCGAATT CTCCGCATCCTTAAGCTTGCACGCCACTCCACTGGCCTCCAGTCTCTGGGCTTCACTTTG CGGAGGAGCTACAATGAGTTGGGCTTGCTCATCCTCTTCCTTGCCATGGGCATTATGATC TTCTCCAGCCTTGTCTTCTTTGCTGAGAAGGATGAGGACGACACCAAGTTCAAAAGCATC CCAGCCTCTTTCTGGTGGGCCACCATCACCATGACTACTGTTGGGTATGGAGACATCTAC CCCAAGACTCTCCTGGGGAAAATTGTTGGGGGACTCTGCTGCATTGCAGGAGTCCTGGTG ATTGCTCTTCCCATCCCCATCATCGTCAATAACTTCTCTGAGTTCTATAAGGAGCAGAAG AGACAGGAGAAAGCAATCAAACGGCGAGAGGCTCTGGAGAGAGCCAAGAGGAATGGCAGC ATCGTATCCATGAACATGAAGGATGCTTTTGCCCGGAGCATTGAGATGATGGACATTGTG GTTGAGAAAAATGGGGAGAATATGGGTAAGAAAGACAAAGTACAAGATAACCACTTGTCT CCTAACAAATGGAAATGGACAAAGAGGACACTGTCTGAAACCAGCTCAAGTAAGTCCTTT GAAACCAAGGAACAGGGATCCCCTGAAAAAGCCAGATCGTCTTCTAGTCCTCAGCACCTG AACGTTCAGCAGTTGGAAGACATGTACAATAAGATGGCCAAGACCCAATCCCAACCCATC CTCAATACCAAGGAGTCAGCAGCACAGAGCAAACCAAAGGAAGAACTTGAAATGGAGAGT ATCCCCAGCCCCGTAGCCCCTCTGCCCACTCGCACAGAAGGGGTCATTGACATGCGAAGT ATGTCAAGCATTGATAGTTTCATTAGCTGTGCCACAGACTTCCCTGAGGCCACCAGATTC TCCCACAGCCCTTTGACATCACTCCCCAGCAAGACTGGGGGCAGCACAGCCCCAGAAGTG GGCTGGCGGGGAGCTCTGGGTGCCAGTGGTGGTAGGTTTGTGGAGGCCAACCCCAGCCCT GATGCCAGCCAGCACTCTAGTTTCTTCATCGAGAGCCCCAAGAGTTCCATGAAAACTAAC AACCCTTTGAAGCTCCGAGCACTTAAAGTCAACTTCATGGAGGGTGACCCCAGTCCACTC CTCCCCGTTCTAGGGATGTACCATGACCCTCTCAGGAACCGGGGGAGTGCTGCGGCTGCT GTCGCTGGACTGGAGTGTGCCACGCTTTTGGACAAGGCTGTGCTGAGCCCAGAGTCCTCC ATCTACACCACAGCAAGTGCTAAGACACCCCCCCGGTCTCCTGAGAAACACACAGCAATA GCGTTCAACTTTGAGGCGGGTGTCCACCAGTACATTGACGCAGACACAGATGATGAGGGA CAGCTGCTCTACAGTGTGGACTCCAGCCCCCCCAAAAGCCTCCCTGGGAGCACCAGTCCG AAGTTCAGCACGGGGACAAGATCGGAGAAAAACCACTTTGAAAGCTCCCCTTTACCCACC TCCCCTAAGTTCTTAAGGCAGAACTGTATTTACTCCACAGAAGCATTGACTGGAAAAGGC CCCAGTGGTCAGGAAAAGTGCAAACTTGAGAACCACATCTCCCCTGACGTCCGTGTGTTG CCAGGGGGAGGAGCCCATGGAAGCACACGAGATCAGAGCATCGTTTAAACGAATTCGAGC TCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAA CAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACC CCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGG TTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGC TACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATT CATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCA GCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCG CCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGG ATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATG CTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGC TATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCG CAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAG GACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTC GACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGAT CTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGG CGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATC GAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAG CATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGT GAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGC CGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATA GCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTC GTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGAC GAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGT ATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAA GAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGC GTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAG GTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGT GCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGG AAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCG CTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGG TAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCAC TGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTG GCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGT TACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGG TGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCC TTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTT GGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGG AACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGT GGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAA AATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCT GCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAA TCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGC GTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAG CGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCAT GCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAG AGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTC GTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGG ATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTG CCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAA CTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}