Nucleotide Sequence (with vector) for pF1KSDA1242
Download
>pF1KSDA1242 4618 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT
AGAACCATGGACCAGGACTATGAGCGGCGCCTGCTTCGCCAGATCGTCATCCAGAATGAG
AACACGATGCCACGCGTCACAGAGATGCGGCGGACCCTGACGCCTGCCAGCTCCCCAGTG
TCCTCGCCCAGCAAGCACGGAGACCGCTTCATCCCCTCCAGAGCCGGAGCCAACTGGAGC
GTGAACTTCCACAGGATTAACGAGAATGAGAAGTCTCCCAGTCAGAACCGGAAAGCCAAG
GACGCCACCTCAGACAACGGCAAAGACGGCCTGGCCTACTCTGCCCTGCTCAAGAATGAG
CTGCTGGGTGCCGGCATCGAGAAGGTGCAGGACCCGCAGACTGAGGACCGCAGGCTGCAG
CCCTCCACGCCTGAGAAGAAGGGTCTGTTCACGTATTCCCTTAGCACCAAGCGCTCCAGC
CCCGATGACGGCAACGATGTGTCTCCCTACTCCCTGTCTCCCGTCAGCAACAAGAGCCAG
AAGCTGCTCCGGTCCCCCCGGAAACCCACCCGCAAGATCTCCAAGATCCCCTTCAAGGTG
CTGGACGCGCCCGAGCTGCAGGACGACTTCTACCTCAATCTGGTGGACTGGTCGTCCCTC
AATGTGCTCAGCGTGGGGCTAGGCACCTGCGTGTACCTGTGGAGTGCCTGTACCAGCCAG
GTGACGCGGCTCTGTGACCTCTCAGTGGAAGGGGACTCAGTGACCTCCGTGGGCTGGTCT
GAGCGGGGGAACCTGGTGGCGGTGGGCACACACAAGGGCTTCGTGCAGATCTGGGACGCA
GCCGCAGGGAAGAAGCTGTCCATGTTGGAGGGCCACACGGCACGCGTCGGGGCGCTGGCC
TGGAATGCTGAGCAGCTGTCGTCCGGGAGCCGCGACCGCATGATCCTGCAGAGGGACATC
CGCACCCCGCCACTGCAGTCGGAGCGGCGGCTGCAGGGCCACCGGCAGGAGGTGTGCGGG
CTCAAGTGGTCCACAGACCACCAGCTCCTCGCCTCGGGGGGCAACGACAACAAGCTGCTG
GTCTGGAATCACTCGAGCCTGAGCCCCGTGCAGCAGTACACGGAGCACCTGGCGGCCGTG
AAGGCCATCGCCTGGTCCCCACATCAGCACGGGCTGCTGGCCTCGGGGGGCGGCACAGCT
GACCGCTGTATCCGCTTCTGGAACACGCTGACAGGACAACCACTGCAGTGTATCGACACG
GGCTCCCAAGTGTGCAATCTGGCCTGGTCCAAGCACGCCAACGAGCTGGTGAGCACGCAC
GGCTACTCACAGAACCAGATCCTTGTCTGGAAGTACCCCTCCCTGACCCAGGTGGCCAAG
CTGACCGGGCACTCCTACCGCGTGCTGTACCTGGCAATGTCCCCTGATGGGGAGGCCATC
GTCACTGGTGCTGGAGACGAGACCCTGAGGTTCTGGAACGTCTTTAGCAAAACCCGTTCG
ACAAAGGAGTCTGTGTCTGTGCTCAACCTCTTCACCAGGATCCGGTACGTAGTTTAAACG
AATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCC
GGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACT
AGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAAC
TATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCC
ACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTA
GCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTT
CCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCA
GCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTG
CCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCG
TTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGG
CTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGG
CTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAAT
GAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCA
GCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCG
GGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGAT
GCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAA
CATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTG
GACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATG
CCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTG
GAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTAT
CAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGAC
CGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGC
CTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGCGAAATGACCGACCAAGCGAC
GCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGAT
AACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCC
GCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGC
TCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGA
AGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTT
CTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTG
TAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGC
GCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTG
GCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTC
TTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTG
CTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACC
GCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTT
CAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGT
TAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCC
GGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATG
GCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATT
CATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATT
TTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGG
ATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCC
GGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCA
GAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCA
CCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCT
CCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGA
CTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCC
GCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCC
GCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGC
GTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 1479 bp
Length: 1479 bp Restriction map B
Restriction map B
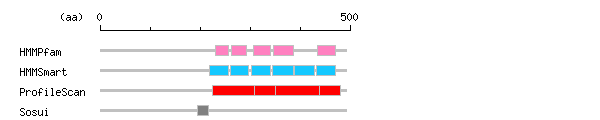
 more Linker info
more Linker info
{kind=link}