Nucleotide Sequence (with vector) for pFN21AE4451
Download
>pFN21AE4451 6109 bp
TCAATATTGGCCATTAGCCATATTATTCATTGGTTATATAGCATAAATCAATATTGGCTA
TTGGCCATTGCATACGTTGTATCTATATCATAATATGTACATTTATATTGGCTCATGTCC
AATATGACCGCCATGTTGGCATTGATTATTGACTAGTTATTAATAGTAATCAATTACGGG
GTCATTAGTTCATAGCCCATATATGGAGTTCCGCGTTACATAACTTACGGTAAATGGCCC
GCCTGGCTGACCGCCCAACGACCCCCGCCCATTGACGTCAATAATGACGTATGTTCCCAT
AGTAACGCCAATAGGGACTTTCCATTGACGTCAATGGGTGGAGTATTTACGGTAAACTGC
CCACTTGGCAGTACATCAAGTGTATCATATGCCAAGTCCGCCCCCTATTGACGTCAATGA
CGGTAAATGGCCCGCCTGGCATTATGCCCAGTACATGACCTTACGGGACTTTCCTACTTG
GCAGTACATCTACGTATTAGTCATCGCTATTACCATGGTGATGCGGTTTTGGCAGTACAC
CAATGGGCGTGGATAGCGGTTTGACTCACGGGGATTTCCAAGTCTCCACCCCATTGACGT
CAATGGGAGTTTGTTTTGGCACCAAAATCAACGGGACTTTCCAAAATGTCGTAATAACCC
CGCCCCGTTGACGCAAATGGGCGGTAGGCGTGTACGGTGGGAGGTCTATATAAGCAGAGC
TGGTTTAGTGAACCGTCAGATCACTAGAAGCTTTATTGCGGTAGTTTATCACAGTTAAAT
TGCTAACGCAGTCAGTGCTTCTGACACAACAGTCTCGAACTTAAGCTGCAGAAGTTGGTC
GTGAGGCACTGGGCAGGTAAGTATCAAGGTTACAAGACAGGTTTAAGGAGACCAATAGAA
ACTGGGCTTGTCGAGACAGAGAAGACTCTTGCGTTTCTGATAGGCACCTATTGGTCTTAC
TGACATCCACTTTGCCTTTCTCTCCACAGGTGTCCACTCCCAGTTCAATTACAGCTCTTA
AGGCTAGAGTATTAATACGACTCACTATAGGGCTAGCAAAGCCACCATGGCAGAAATCGG
TACTGGCTTTCCATTCGACCCCCATTATGTGGAAGTCCTGGGCGAGCGCATGCACTACGT
CGATGTTGGTCCGCGCGATGGCACCCCTGTGCTGTTCCTGCACGGTAACCCGACCTCCTC
CTACGTGTGGCGCAACATCATCCCGCATGTTGCACCGACCCATCGCTGCATTGCTCCAGA
CCTGATCGGTATGGGCAAATCCGACAAACCAGACCTGGGTTATTTCTTCGACGACCACGT
CCGCTTCATGGATGCCTTCATCGAAGCCCTGGGTCTGGAAGAGGTCGTCCTGGTCATTCA
CGACTGGGGCTCCGCTCTGGGTTTCCACTGGGCCAAGCGCAATCCAGAGCGCGTCAAAGG
TATTGCATTTATGGAGTTCATCCGCCCTATCCCGACCTGGGACGAATGGCCAGAATTTGC
CCGCGAGACCTTCCAGGCCTTCCGCACCACCGACGTCGGCCGCAAGCTGATCATCGATCA
GAACGTTTTTATCGAGGGTACGCTGCCGATGGGTGTCGTCCGCCCGCTGACTGAAGTCGA
GATGGACCATTACCGCGAGCCGTTCCTGAATCCTGTTGACCGCGAGCCACTGTGGCGCTT
CCCAAACGAGCTGCCAATCGCCGGTGAGCCAGCGAACATCGTCGCGCTGGTCGAAGAATA
CATGGACTGGCTGCACCAGTCCCCTGTCCCGAAGCTGCTGTTCTGGGGCACCCCAGGCGT
TCTGATCCCACCGGCCGAAGCCGCTCGCCTGGCCAAAAGCCTGCCTAACTGCAAGGCTGT
GGACATCGGCCCGGGTCTGAATCTGCTGCAAGAAGACAACCCGGACCTGATCGGCAGCGA
GATCGCGCGCTGGCTGTCGACGCTCGAGATTTCCGGCGAGCCAACCACTGAGGATCTGTA
CTTTCAGAGCGATAACGCGATCGCCATGGCGGCGCGGGGGTCAGGGCCCCGCGCGCTCCG
CCTGCTGCTCTTGGTCCAGCTGGTCGCGGGGCGCTGCGGTCTAGCGGGCGCGGCGGGCGG
CGCGCAGAGAGGATTATCTGAACCTTCTTCTATTGCAAAACATGAAGATAGTTTGCTTAA
GGATTTATTTCAAGACTACGAAAGATGGGTTCGTCCTGTGGAACACCTGAATGACAAAAT
AAAAATAAAATTTGGACTTGCAATATCTCAATTGGTGGATGTGGATGAGAAAAATCAGTT
AATGACAACAAACGTCTGGTTGAAACAGGAATGGATAGATGTAAAATTAAGATGGAACCC
TGATGACTATGGTGGAATAAAAGTTATACGTGTTCCTTCAGACTCTGTCTGGACACCAGA
CATCGTTTTGTTTGATAATGCAGATGGACGTTTTGAAGGGACCAGTACGAAAACAGTCAT
CAGGTACAATGGCACTGTCACCTGGACTCCACCGGCAAACTACAAAAGTTCCTGTACCAT
AGATGTCACGTTTTTCCCATTTGACCTTCAGAACTGTTCCATGAAATTTGGTTCTTGGAC
TTATGATGGATCACAGGTTGATATAATTCTAGAGGACCAAGATGTAGACAAGAGAGATTT
TTTTGATAATGGAGAATGGGAGATTGTGAGTGCAACAGGGAGCAAAGGAAACAGAACCGA
CAGCTGTTGCTGGTATCCGTATGTCACTTACTCATTTGTAATCAAGCGCCTGCCTCTCTT
TTATACCTTGTTCCTTATAATACCCTGTATTGGGCTCTCATTTTTAACTGTACTTGTCTT
CTATCTTCCTTCAAATGAAGGTGAAAAGATTTGTCTCTGCACTTCAGTACTTGTGTCTTT
GACTGTCTTCCTTCTGGTTATTGAAGAGATCATACCATCATCTTCAAAAGTCATACCTCT
AATTGGAGAGTATCTGGTATTTACCATGATTTTTGTGACACTGTCAATTATGGTAACCGT
CTTCGCTATCAACATTCATCATCGTTCTTCCTCAACACATAATGCCATGGCGCCTTTGGT
CCGCAAGATATTTCTTCACACGCTTCCCAAACTGCTTTGCATGAGAAGTCATGTAGACAG
GTACTTCACTCAGAAAGAGGAAACTGAGAGTGGTAGTGGACCAAAATCTTCTAGAAACAC
ATTGGAAGCTGCGCTCGATTCTATTCGCTACATTACAAGACACATCATGAAGGAAAATGA
TGTCCGTGAGGTTGTTGAAGATTGGAAATTCATAGCCCAGGTTCTTGATCGGATGTTTCT
GTGGACTTTTCTTTTCGTTTCAATTGTTGGATCTCTTGGGCTTTTTGTTCCTGTTATTTA
TAAATGGGCAAATATATTAATACCAGTTCATATTGGAAATGCAAATAAGGTTTAAACGAA
TTCGGGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGG
CTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAG
CATAACCCCTTGGGGCGGCCGCTTCGAGCAGACATGATAAGATACATTGATGAGTTTGGA
CAAACCACAACTAGAATGCAGTGAAAAAAATGCTTTATTTGTGAAATTTGTGATGCTATT
GCTTTATTTGTAACCATTATAAGCTGCAATAAACAAGTTAACAACAACAATTGCATTCAT
TTTATGTTTCAGGTTCAGGGGGAGATGTGGGAGGTTTTTTTAAGCAAGTAAAACCTCTAC
AAATGTGGTAAAATCGAATTCTAATGGATCCTCTTTGCGCTTGCGTTTTCCCTTGTCCAG
ATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTAC
GTAATGGTTTCTTAGACGTCAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATT
TGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAGACAATAACCCTGATAA
ATGCTTCAATAATATTGAAAAAGGAAGAGTATGAGTATTCAACATTTCCGTGTCGCCCTT
ATTCCCTTTTTTGCGGCATTTTGCCTTCCTGTTTTTGCTCACCCAGAAACGCTGGTGAAA
GTAAAAGATGCTGAAGATCAGTTGGGTGCACGAGTGGGTTACATCGAACTGGATCTCAAC
AGCGGTAAGATCCTTGAGAGTTTTCGCCCCGAAGAACGTTTTCCAATGATGAGCACTTTC
AAAGTTCTGCTATGTGGCGCGGTATTATCCCGTATTGACGCCGGGCAAGAGCAACTCGGT
CGCCGCATACACTATTCTCAGAATGACTTGGTTGAGTACTCACCAGTCACAGAAAAGCAT
CTTACGGATGGCATGACAGTAAGAGAATTATGCAGTGCTGCCATAACCATGAGTGATAAC
ACTGCGGCCAACTTACTTCTGACAACTATCGGAGGACCGAAGGAGCTAACCGCTTTTTTG
CACAACATGGGGGATCATGTAACTCGCCTTGATCGTTGGGAACCGGAGCTGAATGAAGCC
ATACCAAACGACGAGCGTGACACCACGATGCCTGTAGCAATGGCAACAACGTTGCGCAAA
CTATTAACTGGCGAACTACTTACTCTAGCTTCCCGGCAACAATTAATAGACTGGATGGAG
GCGGATAAAGTTGCAGGACCACTTCTGCGCTCGGCCCTTCCGGCTGGCTGGTTTATTGCT
GATAAATCTGGAGCCGGTGAGCGTGGGTCTCGCGGTATCATTGCAGCACTGGGGCCAGAT
GGTAAGCCCTCCCGTATCGTAGTTATCTACACGACGGGGAGTCAGGCAACTATGGATGAA
CGAAATAGACAGATCGCTGAGATAGGTGCCTCACTGATTAAGCATTGGTAATTCGAAATG
ACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCA
CAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGA
ACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATC
ACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGG
CGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGAT
ACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGT
ATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTC
AGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACG
ACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCG
GTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTG
GTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCG
GCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCA
GAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGA
ACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGA
TCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGA
AACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTG
GTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGT
GGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTG
CGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATA
AACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCT



 Characterization of the cloned ORF
Characterization of the cloned ORF Restriction map B
Restriction map B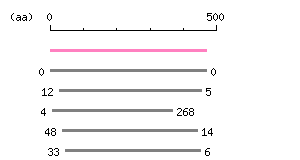
 more Linker info
more Linker info


{kind=link}