Nucleotide Sequence (with vector) for pFN21AA0852
Download
>pFN21AA0852 7615 bp
TCAATATTGGCCATTAGCCATATTATTCATTGGTTATATAGCATAAATCAATATTGGCTA
TTGGCCATTGCATACGTTGTATCTATATCATAATATGTACATTTATATTGGCTCATGTCC
AATATGACCGCCATGTTGGCATTGATTATTGACTAGTTATTAATAGTAATCAATTACGGG
GTCATTAGTTCATAGCCCATATATGGAGTTCCGCGTTACATAACTTACGGTAAATGGCCC
GCCTGGCTGACCGCCCAACGACCCCCGCCCATTGACGTCAATAATGACGTATGTTCCCAT
AGTAACGCCAATAGGGACTTTCCATTGACGTCAATGGGTGGAGTATTTACGGTAAACTGC
CCACTTGGCAGTACATCAAGTGTATCATATGCCAAGTCCGCCCCCTATTGACGTCAATGA
CGGTAAATGGCCCGCCTGGCATTATGCCCAGTACATGACCTTACGGGACTTTCCTACTTG
GCAGTACATCTACGTATTAGTCATCGCTATTACCATGGTGATGCGGTTTTGGCAGTACAC
CAATGGGCGTGGATAGCGGTTTGACTCACGGGGATTTCCAAGTCTCCACCCCATTGACGT
CAATGGGAGTTTGTTTTGGCACCAAAATCAACGGGACTTTCCAAAATGTCGTAATAACCC
CGCCCCGTTGACGCAAATGGGCGGTAGGCGTGTACGGTGGGAGGTCTATATAAGCAGAGC
TGGTTTAGTGAACCGTCAGATCACTAGAAGCTTTATTGCGGTAGTTTATCACAGTTAAAT
TGCTAACGCAGTCAGTGCTTCTGACACAACAGTCTCGAACTTAAGCTGCAGAAGTTGGTC
GTGAGGCACTGGGCAGGTAAGTATCAAGGTTACAAGACAGGTTTAAGGAGACCAATAGAA
ACTGGGCTTGTCGAGACAGAGAAGACTCTTGCGTTTCTGATAGGCACCTATTGGTCTTAC
TGACATCCACTTTGCCTTTCTCTCCACAGGTGTCCACTCCCAGTTCAATTACAGCTCTTA
AGGCTAGAGTATTAATACGACTCACTATAGGGCTAGCAAAGCCACCATGGCAGAAATCGG
TACTGGCTTTCCATTCGACCCCCATTATGTGGAAGTCCTGGGCGAGCGCATGCACTACGT
CGATGTTGGTCCGCGCGATGGCACCCCTGTGCTGTTCCTGCACGGTAACCCGACCTCCTC
CTACGTGTGGCGCAACATCATCCCGCATGTTGCACCGACCCATCGCTGCATTGCTCCAGA
CCTGATCGGTATGGGCAAATCCGACAAACCAGACCTGGGTTATTTCTTCGACGACCACGT
CCGCTTCATGGATGCCTTCATCGAAGCCCTGGGTCTGGAAGAGGTCGTCCTGGTCATTCA
CGACTGGGGCTCCGCTCTGGGTTTCCACTGGGCCAAGCGCAATCCAGAGCGCGTCAAAGG
TATTGCATTTATGGAGTTCATCCGCCCTATCCCGACCTGGGACGAATGGCCAGAATTTGC
CCGCGAGACCTTCCAGGCCTTCCGCACCACCGACGTCGGCCGCAAGCTGATCATCGATCA
GAACGTTTTTATCGAGGGTACGCTGCCGATGGGTGTCGTCCGCCCGCTGACTGAAGTCGA
GATGGACCATTACCGCGAGCCGTTCCTGAATCCTGTTGACCGCGAGCCACTGTGGCGCTT
CCCAAACGAGCTGCCAATCGCCGGTGAGCCAGCGAACATCGTCGCGCTGGTCGAAGAATA
CATGGACTGGCTGCACCAGTCCCCTGTCCCGAAGCTGCTGTTCTGGGGCACCCCAGGCGT
TCTGATCCCACCGGCCGAAGCCGCTCGCCTGGCCAAAAGCCTGCCTAACTGCAAGGCTGT
GGACATCGGCCCGGGTCTGAATCTGCTGCAAGAAGACAACCCGGACCTGATCGGCAGCGA
GATCGCGCGCTGGCTGTCGACGCTCGAGATTTCCGGCGAGCCAACCACTGAGGATCTGTA
CTTTCAGAGCGATAACGCGATCGCCATGCTTTGCTTTTTGGATGATGGAGCAGGAATGGA
TCCAAGTGATGCTGCCAGTGTGATCCAGTTTGGGAAGTCGGCCAAGCGAACACCTGAGTC
TACTCAGATTGGGCAGTACGGGAATGGGTTAAAATCGGGCTCAATGCGCATTGGGAAGGA
TTTTATCCTGTTCACCAAGAAGGAAGACACCATGACGTGCCTCTTCCTGTCTCGCACGTT
TCATGAGGAAGAAGGCATTGATGAAGTGATAGTCCCACTGCCCACCTGGAATGCTCGGAC
CCGGGAACCTGTCACAGACAATGTAGAGAAATTTGCCATTGAGACAGAACTCATCTATAA
GTACTCTCCATTCCGCACTGAGGAGGAAGTGATGACCCAGTTTATGAAGATTCCTGGGGA
CAGCGGAACATTGGTGATCATCTTCAATCTCAAACTCATGGATAATGGAGAGCCAGAACT
AGACATAATCTCAAATCCAAGAGATATCCAGATGGCAGAGACGTCCCCAGAGGGCACGAA
GCCAGAGCGGCGCTCGTTCCGTGCCTATGCCGCTGTGCTCTATATTGATCCCCGGATGAG
GATCTTCATCCATGGGCACAAGGTGCAGACCAAGAGGCTCTCCTGCTGCCTGTACAAGCC
CAGGATGTACAAGTACACGTCAAGCCGTTTCAAGACCCGTGCGGAGCAGGAGGTGAAGAA
AGCAGAGCACGTAGCAAGGATTGCTGAAGAGAAGGCGCGGGAGGCAGAGAGCAAAGCTCG
GACATTAGAAGTACGCCTAGGTGGAGACCTCACGCGGGACTCCAGGGTGATGTTGCGACA
GGTCCAGAACAGAGCCATCACTCTGCGCAGAGAAGCCGATGTCAAGAAGAGGATCAAGGA
GGCCAAGCAGCGAGCACTTAAAGAACCTAAGGAACTGAATTTTGTTTTTGGTGTCAACAT
TGAACACCGGGATCTGGATGGCATGTTCATCTACAACTGTAGCCGACTGATCAAAATGTA
TGAGAAAGTGGGCCCACAGCTGGAAGGGGGCATGGCATGTGGCGGGGTTGTTGGGGTTGT
TGATGTGCCCTACCTGGTCCTGGAGCCTACACACAACAAACAGGACTTTGCTGATGCCAA
GGAGTACCGGCACCTGCTCCGAGCAATGGGGGAGCACCTGGCGCAGTATTGGAAGGATAT
TGCCATCGCCCAGAGGGGAATCATCAAGTTCTGGGATGAGTTTGGCTACCTCTCTGCCAA
CTGGAACCAGCCCCCGTCCAGTGAGCTGCGTTACAAACGCCGGAGAGCTATGGAAATCCC
CACCACCATCCAGTGCGATTTGTGTCTGAAATGGAGAACCCTCCCCTTCCAGCTGAGTTC
TGTGGAAAAAGATTACCCTGACACCTGGGTTTGCTCCATGAACCCTGATCCTGAACAGGA
CCGGTGTGAGGCTTCTGAACAAAAGCAGAAGGTTCCCCTGGGAACATTCAGAAAGGACAT
GAAGACGCAGGAAGAGAAGCAGAAACAACTGACAGAGAAAATTCGCCAGCAGCAGGAGAA
GCTGGAGGCCCTTCAGAAAACCACACCCATCCGCTCCCAAGCAGACCTGAAGAAATTGCC
CTTGGAAGTGACCACCAGACCTTCCACTGAGGAACCTGTGCGTAGACCTCAGCGTCCTCG
GTCGCCCCCTTTACCTGCTGTGATCAGGAACGCCCCCAGCAGACCCCCTTCTTTGCCAAC
TCCTAGACCAGCCAGCCAGCCCCGAAAGGCTCCTGTCATCAGCAGTACCCCAAAGCTCCC
TGCTTTGGCAGCCCGGGAGGAGGCCAGCACATCTAGGCTGCTCCAGCCACCTGAGGCACC
CCGAAAGCCTGCCAACACTCTCGTCAAGACTGCATCCCGACCTGCCCCTCTGGTGCAGCA
ACTGTCACCATCTTTACTGCCCAACTCCAAGAGCCCTCGGGAGGTTCCTTCTCCCAAAGT
CATCAAGACTCCAGTGGTGAAGAAGACAGAGTCACCCATCAAACTCTCCCCGGCTACCCC
TAGTCGGAAGCGGAGTGTCGCAGTTTCTGATGAGGAAGAAGTTGAGGAGGAAGCTGAGAG
GAGGAAGGAGAGGTGCAAGCGGGGCAGATTTGTTGTGAAGGAGGAAAAGAAGGACTCGAA
TGAGCTCTCAGACAGTGCTGGGGAAGAGGACTCGGCTGACCTCAAGAGAGCTCAGAAAGA
TAAAGGGCTGCACGTGGAGGTGCGTGTGAACAGGGAGTGGTACACGGGCCGTGTCACAGC
CGTGGAGGTGGGCAAGCATGTGGTGCGGTGGAAGGTGAAGTTTGACTACGTGCCCACAGA
CACGACACCAAGAGACCGCTGGGTGGAGAAAGGCAGTGAGGATGTGCGGCTGATGAAACC
CCCTTCTCCGGAACATCAGAGCCTTGATACACAACAGGAGGGCGGGGAGGAGGAGGTGGG
CCCTGTGGCCCAGCAGGCCATAGCTGTCGCAGAGCCCTCCACTTCCGAATGCCTCCGCAT
TGAGCCTGACACCACTGCCCTGAGCACCAATCACGAGACCATCGACCTGCTTGTCCAGAT
CCTCCGGAATTGTTTACGGTACTTCCTGCCTCCAAGTTTCCCCATCTCCAAGAAGCAGCT
GAGTGCTATGAATTCAGATGAGCTAATATCTTTTCCTCTGAAGGAGTACTTCAAGCAATA
TGAAGTAGGGCTCCAAAACCTGTGCAATTCCTACCAGAGCCGTGCTGACTCCCGGGCCAA
GGCCTCCGAGGAAAGCCTGCGCACCTCCGAGAGGAAGCTCCGCGAGACGGAGGAGAAGCT
GCAGAAGCTGAGGACCAACATCGTGGCACTCCTGCAAAAGGTGCAGGAGGACATAGACAT
CAACACAGATGATGAGCTGGACGCCTACATTGAGGACCTCATCACCAAGGGGGACGTTTA
AACGAATTCGGGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTG
ATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAAT
AACTAGCATAACCCCTTGGGGCGGCCGCTTCGAGCAGACATGATAAGATACATTGATGAG
TTTGGACAAACCACAACTAGAATGCAGTGAAAAAAATGCTTTATTTGTGAAATTTGTGAT
GCTATTGCTTTATTTGTAACCATTATAAGCTGCAATAAACAAGTTAACAACAACAATTGC
ATTCATTTTATGTTTCAGGTTCAGGGGGAGATGTGGGAGGTTTTTTTAAGCAAGTAAAAC
CTCTACAAATGTGGTAAAATCGAATTCTAATGGATCCTCTTTGCGCTTGCGTTTTCCCTT
GTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCT
TTCTACGTAATGGTTTCTTAGACGTCAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACC
CCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAGACAATAACCC
TGATAAATGCTTCAATAATATTGAAAAAGGAAGAGTATGAGTATTCAACATTTCCGTGTC
GCCCTTATTCCCTTTTTTGCGGCATTTTGCCTTCCTGTTTTTGCTCACCCAGAAACGCTG
GTGAAAGTAAAAGATGCTGAAGATCAGTTGGGTGCACGAGTGGGTTACATCGAACTGGAT
CTCAACAGCGGTAAGATCCTTGAGAGTTTTCGCCCCGAAGAACGTTTTCCAATGATGAGC
ACTTTCAAAGTTCTGCTATGTGGCGCGGTATTATCCCGTATTGACGCCGGGCAAGAGCAA
CTCGGTCGCCGCATACACTATTCTCAGAATGACTTGGTTGAGTACTCACCAGTCACAGAA
AAGCATCTTACGGATGGCATGACAGTAAGAGAATTATGCAGTGCTGCCATAACCATGAGT
GATAACACTGCGGCCAACTTACTTCTGACAACTATCGGAGGACCGAAGGAGCTAACCGCT
TTTTTGCACAACATGGGGGATCATGTAACTCGCCTTGATCGTTGGGAACCGGAGCTGAAT
GAAGCCATACCAAACGACGAGCGTGACACCACGATGCCTGTAGCAATGGCAACAACGTTG
CGCAAACTATTAACTGGCGAACTACTTACTCTAGCTTCCCGGCAACAATTAATAGACTGG
ATGGAGGCGGATAAAGTTGCAGGACCACTTCTGCGCTCGGCCCTTCCGGCTGGCTGGTTT
ATTGCTGATAAATCTGGAGCCGGTGAGCGTGGGTCTCGCGGTATCATTGCAGCACTGGGG
CCAGATGGTAAGCCCTCCCGTATCGTAGTTATCTACACGACGGGGAGTCAGGCAACTATG
GATGAACGAAATAGACAGATCGCTGAGATAGGTGCCTCACTGATTAAGCATTGGTAATTC
GAAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGT
TATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGG
CCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACG
AGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGAT
ACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTA
CCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCT
GTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCC
CCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAA
GACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATG
TAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAG
TATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTT
GATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTA
CGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTC
AGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCA
CCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGA
TGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTAC
CCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTT
TCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTA
GCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATC
GAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCT



 Characterization of the cloned ORF
Characterization of the cloned ORF Restriction map B
Restriction map B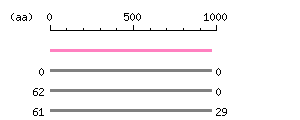

 more Linker info
more Linker info

{kind=link}