Nucleotide Sequence (with vector) for pFN21AA1042
Download
>pFN21AA1042 7564 bp
TCAATATTGGCCATTAGCCATATTATTCATTGGTTATATAGCATAAATCAATATTGGCTA
TTGGCCATTGCATACGTTGTATCTATATCATAATATGTACATTTATATTGGCTCATGTCC
AATATGACCGCCATGTTGGCATTGATTATTGACTAGTTATTAATAGTAATCAATTACGGG
GTCATTAGTTCATAGCCCATATATGGAGTTCCGCGTTACATAACTTACGGTAAATGGCCC
GCCTGGCTGACCGCCCAACGACCCCCGCCCATTGACGTCAATAATGACGTATGTTCCCAT
AGTAACGCCAATAGGGACTTTCCATTGACGTCAATGGGTGGAGTATTTACGGTAAACTGC
CCACTTGGCAGTACATCAAGTGTATCATATGCCAAGTCCGCCCCCTATTGACGTCAATGA
CGGTAAATGGCCCGCCTGGCATTATGCCCAGTACATGACCTTACGGGACTTTCCTACTTG
GCAGTACATCTACGTATTAGTCATCGCTATTACCATGGTGATGCGGTTTTGGCAGTACAC
CAATGGGCGTGGATAGCGGTTTGACTCACGGGGATTTCCAAGTCTCCACCCCATTGACGT
CAATGGGAGTTTGTTTTGGCACCAAAATCAACGGGACTTTCCAAAATGTCGTAATAACCC
CGCCCCGTTGACGCAAATGGGCGGTAGGCGTGTACGGTGGGAGGTCTATATAAGCAGAGC
TGGTTTAGTGAACCGTCAGATCACTAGAAGCTTTATTGCGGTAGTTTATCACAGTTAAAT
TGCTAACGCAGTCAGTGCTTCTGACACAACAGTCTCGAACTTAAGCTGCAGAAGTTGGTC
GTGAGGCACTGGGCAGGTAAGTATCAAGGTTACAAGACAGGTTTAAGGAGACCAATAGAA
ACTGGGCTTGTCGAGACAGAGAAGACTCTTGCGTTTCTGATAGGCACCTATTGGTCTTAC
TGACATCCACTTTGCCTTTCTCTCCACAGGTGTCCACTCCCAGTTCAATTACAGCTCTTA
AGGCTAGAGTATTAATACGACTCACTATAGGGCTAGCAAAGCCACCATGGCAGAAATCGG
TACTGGCTTTCCATTCGACCCCCATTATGTGGAAGTCCTGGGCGAGCGCATGCACTACGT
CGATGTTGGTCCGCGCGATGGCACCCCTGTGCTGTTCCTGCACGGTAACCCGACCTCCTC
CTACGTGTGGCGCAACATCATCCCGCATGTTGCACCGACCCATCGCTGCATTGCTCCAGA
CCTGATCGGTATGGGCAAATCCGACAAACCAGACCTGGGTTATTTCTTCGACGACCACGT
CCGCTTCATGGATGCCTTCATCGAAGCCCTGGGTCTGGAAGAGGTCGTCCTGGTCATTCA
CGACTGGGGCTCCGCTCTGGGTTTCCACTGGGCCAAGCGCAATCCAGAGCGCGTCAAAGG
TATTGCATTTATGGAGTTCATCCGCCCTATCCCGACCTGGGACGAATGGCCAGAATTTGC
CCGCGAGACCTTCCAGGCCTTCCGCACCACCGACGTCGGCCGCAAGCTGATCATCGATCA
GAACGTTTTTATCGAGGGTACGCTGCCGATGGGTGTCGTCCGCCCGCTGACTGAAGTCGA
GATGGACCATTACCGCGAGCCGTTCCTGAATCCTGTTGACCGCGAGCCACTGTGGCGCTT
CCCAAACGAGCTGCCAATCGCCGGTGAGCCAGCGAACATCGTCGCGCTGGTCGAAGAATA
CATGGACTGGCTGCACCAGTCCCCTGTCCCGAAGCTGCTGTTCTGGGGCACCCCAGGCGT
TCTGATCCCACCGGCCGAAGCCGCTCGCCTGGCCAAAAGCCTGCCTAACTGCAAGGCTGT
GGACATCGGCCCGGGTCTGAATCTGCTGCAAGAAGACAACCCGGACCTGATCGGCAGCGA
GATCGCGCGCTGGCTGTCGACGCTCGAGATTTCCGGCGAGCCAACCACTGAGGATCTGTA
CTTTCAGAGCGATAACGCGATCGCCATGGCATTGGTTTTTCAATTCGGGCAGCCCGTCAG
GGCTCAGCCTCTGCCAGGACTCTGCCACGGCAAGCTCATTCGGACAAACGCCTGTGATGT
GTGCAACAGCACCGATCTTCCGGAAGTCGAGATCATTAGCCTGCTGGAGGAGCAGCTGCC
CCATTATAAGTTAAGAGCCGACACCATCTACGGTTATGACCACGACGACTGGCTCCATAC
ACCTCTCATTTCTCCAGATGCCAACATTGACCTCACAACCGAGCAAATTGAAGAGACGTT
AAAATACTTCCTTTTATGTGCTGAAAGAGTTGGCCAGATGACTAAGACATATAATGACAT
AGATGCTGTCACTCGGCTTCTTGAGGAGAAAGAGCGGGATTTAGAATTGGCCGCTCGCAT
CGGCCAGTCGTTGTTGAAGAAGAACAAGACCCTAACCGAGAGGAACGAGCTGCTGGAGGA
GCAGGTGGAACACATCAGGGAGGAGGTGTCTCAGCTCCGGCATGAGCTGTCCATGAAGGA
TGAGCTGCTTCAGTTCTACACCAGCGCTGCGGAGGAGAGTGAGCCCGAGTCCGTTTGCTC
AACCCCGTTGAAGAGGAATGAGTCGTCCTCCTCAGTCCAGAATTACTTTCATTTGGATTC
TCTTCAAAAGAAGCTGAAAGACCTTGAAGAGGAGAATGTTGTACTTCGATCCGAGGCCAG
CCAGCTGAAGACAGAGACCATCACCTATGAGGAGAAGGAGCAGCAGCTGGTCAATGACTG
CGTGAAGGAGCTGAGGGATGCCAATGTCCAGATTGCTAGTATCTCAGAGGAACTGGCCAA
GAAGACGGAAGATGCTGCCCGCCAGCAAGAGGAGATCACACACCTGCTATCGCAAATAGT
TGATTTGCAGAAAAAGGCAAAAGCTTGCGCAGTGGAAAATGAAGAACTTGTCCAGCATCT
GGGGGCTGCTAAGGATGCCCAGCGGCAGCTCACAGCCGAGCTGCGTGAGCTGGAGGACAA
GTACGCAGAGTGCATGGAGATGCTGCATGAGGCGCAGGAGGAGCTGAAGAACCTCCGGAA
CAAAACCATGCCCAATACCACGTCTCGGCGCTACCACTCGCTGGGCCTGTTTCCCATGGA
TTCCTTGGCAGCAGAGATTGAGGGAACGATGCGCAAGGAGCTGCAGTTGGAAGAGGCCGA
GTCTCCAGACATCACTCACCAGAAGCGTGTCTTTGAGACAGTAAGAAACATCAACCAGGT
TGTCAAGCAGAGATCTCTGACCCCTTCTCCCATGAACATCCCCGGCTCCAACCAGTCCTC
GGCCATGAACTCCCTCCTGTCCAGCTGCGTCAGCACCCCCCGGTCCAGCTTCTACGGCAG
CGACATAGGCAACGTCGTCCTCGACAACAAGACCAACAGCATCATTCTGGAAACAGAGGC
AGCCGACCTGGGAAACGATGAGCGGAGTAAGAAGCCGGGGACGCCGGGCACCCCAGGCTC
CCACGACCTGGAGACGGCGCTGAGGCGGCTGTCCCTGCGCCGGGAGAACTACCTCTCGGA
GAGGAGGTTCTTTGAGGAGGAGCAAGAGAGGAAGCTCCAGGAGCTGGCGGAGAAGGGCGA
GCTGCGCAGCGGCTCCCTCACACCCACTGAGAGCATCATGTCCCTGGGCACGCACTCCCG
CTTCTCCGAGTTCACCGGCTTCTCTGGCATGTCCTTCAGCAGCCGCTCCTACCTGCCTGA
GAAGCTCCAGATCGTGAAGCCGCTGGAAGGTTCTGCCACACTTCACCACTGGCAGCAGTT
GGCCCAACCTCACCTTGGGGGCATCCTGGACCCCCGGCCTGGTGTGGTCACCAAGGGCTT
CCGGACGCTGGATGTTGACCTGGACGAAGTGTACTGCCTTAACGACTTTGAAGAAGATGA
CACAGGTGACCACATTTCTCTCCCACGCCTAGCTACCTCCACTCCAGTTCAGCACCCAGA
GACCTCAGCGCACCATCCTGGGAAGTGCATGTCTCAGACCAACTCCACCTTCACCTTCAC
CACCTGTCGCATCCTGCATCCTTCAGATGAGCTCACTCGGGTCACACCAAGCCTTAACTC
AGCCCCAACTCCAGCTTGTGGCAGCACCAGCCACTTGAAATCCACGCCGGTGGCCACACC
ATGCACTCCACGGAGACTGAGCCTGGCTGAGTCCTTCACTAACACCCGTGAGTCCACGAC
CACCATGAGCACATCCCTGGGGCTCGTGTGGCTGTTGAAGGAGCGGGGCATTTCTGCTGC
CGTGTACGACCCCCAGAGCTGGGACAGGGCCGGCCGGGGCTCCCTCCTGCACTCCTACAC
GCCCAAGATGGCTGTGATCCCCTCTACTCCGCCGAACTCGCCTATGCAGACACCCACATC
CTCCCCACCCTCCTTTGAGTTCAAGTGCACGAGCCCTCCCTACGACAATTTCCTGGCTTC
CAAGCCAGCCAGCTCCATCCTGAGGGAAGTGAGAGAAAAGAACGTCCGCAGCAGCGAGAG
CCAGACCGACGTGTCCGTCTCCAACCTCAACCTCGTGGACAAAGTCAGGAGGTTTGGGGT
GGCCAAAGTGGTGAACTCAGGGCGAGCCCATGTCCCCACCTTGACTGAGGAGCAGGGACC
CCTCCTCTGTGGGCCCCCGGGGCCAGCACCAGCCCTTGTTCCCAGAGGCCTGGTACCTGA
GGGCCTGCCCCTCAGATGCCCCACTGTCACCAGTGCCATCGGTGGGCTGCAGCTCAATAG
TGGCATCCGGCGGAATCGCAGCTTCCCCACCATGGTGGGATCTAGCATGCAGATGAAAGC
TCCTGTGACTCTCACCTCGGGCATCTTGATGGGTGCTAAGCTCTCCAAACAAACTAGCTT
ACGGGTTTAAACGAATTCGGGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCA
TGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCG
CTGAGCAATAACTAGCATAACCCCTTGGGGCGGCCGCTTCGAGCAGACATGATAAGATAC
ATTGATGAGTTTGGACAAACCACAACTAGAATGCAGTGAAAAAAATGCTTTATTTGTGAA
ATTTGTGATGCTATTGCTTTATTTGTAACCATTATAAGCTGCAATAAACAAGTTAACAAC
AACAATTGCATTCATTTTATGTTTCAGGTTCAGGGGGAGATGTGGGAGGTTTTTTTAAGC
AAGTAAAACCTCTACAAATGTGGTAAAATCGAATTCTAATGGATCCTCTTTGCGCTTGCG
TTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGC
GGACTGGCTTTCTACGTAATGGTTTCTTAGACGTCAGGTGGCACTTTTCGGGGAAATGTG
CGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAGA
CAATAACCCTGATAAATGCTTCAATAATATTGAAAAAGGAAGAGTATGAGTATTCAACAT
TTCCGTGTCGCCCTTATTCCCTTTTTTGCGGCATTTTGCCTTCCTGTTTTTGCTCACCCA
GAAACGCTGGTGAAAGTAAAAGATGCTGAAGATCAGTTGGGTGCACGAGTGGGTTACATC
GAACTGGATCTCAACAGCGGTAAGATCCTTGAGAGTTTTCGCCCCGAAGAACGTTTTCCA
ATGATGAGCACTTTCAAAGTTCTGCTATGTGGCGCGGTATTATCCCGTATTGACGCCGGG
CAAGAGCAACTCGGTCGCCGCATACACTATTCTCAGAATGACTTGGTTGAGTACTCACCA
GTCACAGAAAAGCATCTTACGGATGGCATGACAGTAAGAGAATTATGCAGTGCTGCCATA
ACCATGAGTGATAACACTGCGGCCAACTTACTTCTGACAACTATCGGAGGACCGAAGGAG
CTAACCGCTTTTTTGCACAACATGGGGGATCATGTAACTCGCCTTGATCGTTGGGAACCG
GAGCTGAATGAAGCCATACCAAACGACGAGCGTGACACCACGATGCCTGTAGCAATGGCA
ACAACGTTGCGCAAACTATTAACTGGCGAACTACTTACTCTAGCTTCCCGGCAACAATTA
ATAGACTGGATGGAGGCGGATAAAGTTGCAGGACCACTTCTGCGCTCGGCCCTTCCGGCT
GGCTGGTTTATTGCTGATAAATCTGGAGCCGGTGAGCGTGGGTCTCGCGGTATCATTGCA
GCACTGGGGCCAGATGGTAAGCCCTCCCGTATCGTAGTTATCTACACGACGGGGAGTCAG
GCAACTATGGATGAACGAAATAGACAGATCGCTGAGATAGGTGCCTCACTGATTAAGCAT
TGGTAATTCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGG
TAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCC
AGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCC
CCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGAC
TATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCC
TGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATA
GCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGC
ACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCA
ACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAG
CGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTA
GAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTG
GTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGC
AGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGT
CTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAA
GGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCT
TCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGT
GGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGC
GGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAA
CGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTC
GTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAG
ATCT



 Characterization of the cloned ORF
Characterization of the cloned ORF Restriction map B
Restriction map B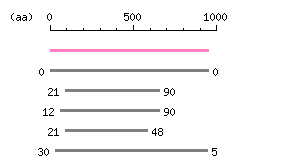

 more Linker info
more Linker info
{kind=link}