


-
SpecieshumanProduct IDFXC00109Cloning SiteSgfI-PmeISymbolATP9A
Alias : ATPIIADescriptionATPase, class II, type 9A Length: 2733 bp
Length: 2733 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 911 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)

Entry Exp ID% symbol CCDS33489.1 0 87.2 ATP9A CCDS77202.1 6.1e-214 77.4 ATP9B CCDS12014.1 1.1e-199 76.4 ATP9B CCDS33896.1 2.2e-57 30.7 ATP11B CCDS3466.1 3.6e-54 30.8 ATP8A1
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]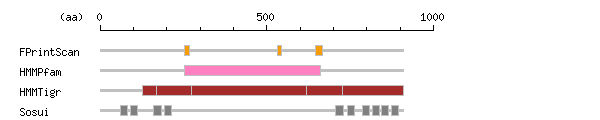 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR001757 253 267 PR00119 ATPase IPR001757 533 543 PR00119 ATPase IPR001757 647 666 PR00119 ATPase HMMPfam IPR005834 253 660 PF00702 Haloacid dehalogenase-like hydrolase HMMTigr IPR006539 128 909 TIGR01652 ATPase IPR001757 168 275 TIGR01494 ATPase IPR001757 620 727 TIGR01494 ATPase
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 60 NQFKYFFNLYFLLLACSQFVPEM 82 SECONDARY 23 2 89 TYWVPLGFVLAVTVIREAVEEIR 111 SECONDARY 23 3 161 DLEVNCLTKILFGALVVVSLVMV 183 PRIMARY 23 4 193 YLQIIRFLLLFSNIIPISLRVNL 215 PRIMARY 23 5 707 SQFVIHRSLCISTMQAVFSSVFY 729 SECONDARY 23 6 741 IIGYSTIYTMFPVFSLVLDKDVK 763 SECONDARY 23 7 786 KTFLIWVLISIYQGSTIMYGALL 808 PRIMARY 23 8 816 HIVAISFTSLILTELLMVALTIQ 838 PRIMARY 23 9 843 LMTVAELLSLACYIASLVFLHEF 865 PRIMARY 23 10 873 TLSFLWKVSVITLVSCLPLYVLK 895 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) XP_011526783 1025 609126 87.2 90.2 NP_006036 1047 609126 87.2 90.2 NP_001293014 1136 614446 77.4 86.9 XP_016881219 1137 614446 77.4 86.9 XP_016881228 753 614446 77.6 80.1 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KA0611 Download>KIAA0611 2733 bp ATGGACAGCAGGCCCCGCGCCGGGTGCTGCGAGTGGCTGAGATGCTGCGGTGGAGGGGAG GCCAGGCCCCGCACTGTCTGGCTGGGGCACCCCGAGAAGAGAGACCAGAGGTATCCTCGG AATGTCATCAACAATCAGAAGTACAATTTCTTCACCTTTCTTCCTGGGGTGCTGTTCAAC CAGTTCAAATACTTTTTCAACCTCTATTTCTTACTTCTTGCCTGCTCTCAGTTTGTTCCC GAAATGAGACTTGGTGCACTCTATACCTACTGGGTTCCCCTGGGCTTCGTGCTGGCCGTC ACTGTCATCCGTGAGGCGGTGGAGGAGATCCGATGCTACGTGCGGGACAAGGAAGTCAAC TCCCAGGTCTACAGCCGGCTCACAGCACGAGGTACTGTTGTGGGTGTTGTTCTTTACACT GGCAGAGAACTCCGGAGTGTCATGAATACCTCAAATCCCCGAAGTAAGATCGGCCTGTTC GACTTGGAAGTGAACTGCCTCACCAAGATCCTCTTTGGTGCCCTGGTGGTGGTCTCGCTG GTCATGGTTGCCCTTCAGCACTTTGCAGGCCGTTGGTACCTGCAGATCATCCGCTTCCTC CTCTTGTTTTCCAACATCATCCCCATTAGTTTGCGCGTGAACCTGGACATGGGCAAGATC GTGTACAGCTGGGTGATTCGAAGGGACTCAAAAATCCCCGGGACCGTGGTTCGCTCCAGC ACGATTCCTGAGCAGCTGGGCAGGATTTCGTACTTACTCACAGACAAGACAGGCACTCTT ACCCAGAACGAGATGATTTTCAAACGGCTCCATCTCGGAACAGTAGCCTACGGCCTCGAC TCAATGGACGAAGTACAAAGCCACATTTTCAGCATTTACACCCAGCAATCCCAGGACCCA CCGGCTCAGAAGGGCCCAACGCTCACCACTAAGGTCCGGCGGACCATGAGCAGCCGCGTG CACGAAGCCGTGAAGGCCATCGCGCTCTGCCACAACGTGACTCCCGTGTATGAGTCCAAC GGTGTGACTGATCAGGCTGAGGCCGAGAAGCAGTACGAAGACTCCTGCCGCGTATACCAG GCATCCAGCCCCGATGAGGTGGCCCTGGTACAGTGGACGGAAAGTGTGGGCTTAACCCTG GTGGGCCGAGACCAGTCTTCCATGCAGCTGAGGACCCCTGGCGACCAGATCCTGAACTTC ACCATCCTACAGATCTTCCCTTTCACCTATGAAAGCAAACGTATGGGCATCATCGTGCGG GATGAATCAACTGGAGAAATTACGTTTTACATGAAGGGAGCAGATGTGGTCATGGCTGGC ATTGTGCAGTACAATGACTGGTTGGAGGAAGAGTGTGGCAACATGGCCCGAGAAGGGCTG CGGGTGCTCGTGGTGGCAAAGAAGTCTCTTGCAGAGGAGCAGTATCAGGACTTTGAAGCC CGCTACGTCCAGGCCAAGCTGAGTGTGCACGACCGCTCCCTCAAAGTGGCCACGGTGATC GAGAGCCTGGAGATGGAGATGGAACTGCTGTGCCTGACGGGCGTGGAGGACCAGCTGCAG GCAGATGTGCGGCCCACGCTGGAGACCCTGAGGAATGCTGGCATCAAGGTTTGGATGCTG ACAGGGGACAAGCTGGAGACAGCTACGTGCACAGCGAAGAATGCACATCTGGTGACCAGA AACCAAGACATCCACGTTTTTCGGCTGGTGACCAACCGCGGGGAGGCTCACCTCGAGCTG AACGCCTTCCGCAGGAAGCATGATTGTGCCCTGGTCATCTCGGGAGACTCCCTGGAGGTT TGCCTCAAGTACTATGAGTACGAGTTCATGGAGCTGGCCTGCCAGTGCCCGGCCGTAGTC TGCTGCCGATGTGCCCCCACCCAGAAGGCCCAGATCGTGCGCCTGCTTCAGGAGCGCACG GGCAAGCTCACCTGTGCAGTAGGGGACGGAGGCAATGACGTCAGCATGATTCAGGAATCT GACTGCGGCGTGGGAGTGGAAGGAAAGGAAGGAAAACAGGCTTCGTTGGCTGCAGACTTC TCCATCACTCAATTTAAGCATCTTGGCCGGTTGCTTATGGTGCATGGCCGGAACAGCTAC AAGCGGTCAGCCGCCCTCAGCCAGTTCGTGATTCACAGGAGCCTCTGTATCAGCACCATG CAGGCTGTCTTTTCCTCCGTGTTTTACTTTGCCTCCGTCCCTCTCTATCAAGGATTCCTC ATCATTGGGTACTCCACAATTTACACCATGTTTCCTGTGTTTTCTCTGGTCCTGGACAAA GATGTCAAATCGGAAGTTGCCATGCTGTATCCTGAGCTCTACAAGGATCTTCTCAAGGGA CGGCCGTTGTCCTACAAGACATTCTTAATATGGGTTTTGATTAGCATCTATCAAGGGAGC ACCATCATGTACGGGGCGCTGCTGCTGTTTGAGTCGGAGTTCGTGCACATCGTGGCCATC TCCTTCACCTCGCTGATCCTCACCGAGCTGCTCATGGTGGCGCTGACCATCCAGACCTGG CACTGGCTCATGACAGTGGCGGAGCTGCTCAGCCTGGCCTGCTACATCGCCTCCCTGGTG TTCTTACACGAGTTCATCGATGTGTACTTCATCGCCACCTTGTCATTCTTGTGGAAAGTC TCCGTCATCACTCTGGTCAGCTGCCTCCCCCTCTATGTCCTCAAGTACCTGCGAAGACGG TTCTCTCCCCCCAGCTACTCAAAGCTCACATCA
Cloned ORF protein sequence for pF1KA0611 Download>KIAA0611 911 aa MDSRPRAGCCEWLRCCGGGEARPRTVWLGHPEKRDQRYPRNVINNQKYNFFTFLPGVLFN QFKYFFNLYFLLLACSQFVPEMRLGALYTYWVPLGFVLAVTVIREAVEEIRCYVRDKEVN SQVYSRLTARGTVVGVVLYTGRELRSVMNTSNPRSKIGLFDLEVNCLTKILFGALVVVSL VMVALQHFAGRWYLQIIRFLLLFSNIIPISLRVNLDMGKIVYSWVIRRDSKIPGTVVRSS TIPEQLGRISYLLTDKTGTLTQNEMIFKRLHLGTVAYGLDSMDEVQSHIFSIYTQQSQDP PAQKGPTLTTKVRRTMSSRVHEAVKAIALCHNVTPVYESNGVTDQAEAEKQYEDSCRVYQ ASSPDEVALVQWTESVGLTLVGRDQSSMQLRTPGDQILNFTILQIFPFTYESKRMGIIVR DESTGEITFYMKGADVVMAGIVQYNDWLEEECGNMAREGLRVLVVAKKSLAEEQYQDFEA RYVQAKLSVHDRSLKVATVIESLEMEMELLCLTGVEDQLQADVRPTLETLRNAGIKVWML TGDKLETATCTAKNAHLVTRNQDIHVFRLVTNRGEAHLELNAFRRKHDCALVISGDSLEV CLKYYEYEFMELACQCPAVVCCRCAPTQKAQIVRLLQERTGKLTCAVGDGGNDVSMIQES DCGVGVEGKEGKQASLAADFSITQFKHLGRLLMVHGRNSYKRSAALSQFVIHRSLCISTM QAVFSSVFYFASVPLYQGFLIIGYSTIYTMFPVFSLVLDKDVKSEVAMLYPELYKDLLKG RPLSYKTFLIWVLISIYQGSTIMYGALLLFESEFVHIVAISFTSLILTELLMVALTIQTW HWLMTVAELLSLACYIASLVFLHEFIDVYFIATLSFLWKVSVITLVSCLPLYVLKYLRRR FSPPSYSKLTS
Nucleotide Sequence (with vector) for pF1KA0611 Download>pF1KA0611 5846 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGACAGCAGG CCCCGCGCCGGGTGCTGCGAGTGGCTGAGATGCTGCGGTGGAGGGGAGGCCAGGCCCCGC ACTGTCTGGCTGGGGCACCCCGAGAAGAGAGACCAGAGGTATCCTCGGAATGTCATCAAC AATCAGAAGTACAATTTCTTCACCTTTCTTCCTGGGGTGCTGTTCAACCAGTTCAAATAC TTTTTCAACCTCTATTTCTTACTTCTTGCCTGCTCTCAGTTTGTTCCCGAAATGAGACTT GGTGCACTCTATACCTACTGGGTTCCCCTGGGCTTCGTGCTGGCCGTCACTGTCATCCGT GAGGCGGTGGAGGAGATCCGATGCTACGTGCGGGACAAGGAAGTCAACTCCCAGGTCTAC AGCCGGCTCACAGCACGAGGTACTGTTGTGGGTGTTGTTCTTTACACTGGCAGAGAACTC CGGAGTGTCATGAATACCTCAAATCCCCGAAGTAAGATCGGCCTGTTCGACTTGGAAGTG AACTGCCTCACCAAGATCCTCTTTGGTGCCCTGGTGGTGGTCTCGCTGGTCATGGTTGCC CTTCAGCACTTTGCAGGCCGTTGGTACCTGCAGATCATCCGCTTCCTCCTCTTGTTTTCC AACATCATCCCCATTAGTTTGCGCGTGAACCTGGACATGGGCAAGATCGTGTACAGCTGG GTGATTCGAAGGGACTCAAAAATCCCCGGGACCGTGGTTCGCTCCAGCACGATTCCTGAG CAGCTGGGCAGGATTTCGTACTTACTCACAGACAAGACAGGCACTCTTACCCAGAACGAG ATGATTTTCAAACGGCTCCATCTCGGAACAGTAGCCTACGGCCTCGACTCAATGGACGAA GTACAAAGCCACATTTTCAGCATTTACACCCAGCAATCCCAGGACCCACCGGCTCAGAAG GGCCCAACGCTCACCACTAAGGTCCGGCGGACCATGAGCAGCCGCGTGCACGAAGCCGTG AAGGCCATCGCGCTCTGCCACAACGTGACTCCCGTGTATGAGTCCAACGGTGTGACTGAT CAGGCTGAGGCCGAGAAGCAGTACGAAGACTCCTGCCGCGTATACCAGGCATCCAGCCCC GATGAGGTGGCCCTGGTACAGTGGACGGAAAGTGTGGGCTTAACCCTGGTGGGCCGAGAC CAGTCTTCCATGCAGCTGAGGACCCCTGGCGACCAGATCCTGAACTTCACCATCCTACAG ATCTTCCCTTTCACCTATGAAAGCAAACGTATGGGCATCATCGTGCGGGATGAATCAACT GGAGAAATTACGTTTTACATGAAGGGAGCAGATGTGGTCATGGCTGGCATTGTGCAGTAC AATGACTGGTTGGAGGAAGAGTGTGGCAACATGGCCCGAGAAGGGCTGCGGGTGCTCGTG GTGGCAAAGAAGTCTCTTGCAGAGGAGCAGTATCAGGACTTTGAAGCCCGCTACGTCCAG GCCAAGCTGAGTGTGCACGACCGCTCCCTCAAAGTGGCCACGGTGATCGAGAGCCTGGAG ATGGAGATGGAACTGCTGTGCCTGACGGGCGTGGAGGACCAGCTGCAGGCAGATGTGCGG CCCACGCTGGAGACCCTGAGGAATGCTGGCATCAAGGTTTGGATGCTGACAGGGGACAAG CTGGAGACAGCTACGTGCACAGCGAAGAATGCACATCTGGTGACCAGAAACCAAGACATC CACGTTTTTCGGCTGGTGACCAACCGCGGGGAGGCTCACCTCGAGCTGAACGCCTTCCGC AGGAAGCATGATTGTGCCCTGGTCATCTCGGGAGACTCCCTGGAGGTTTGCCTCAAGTAC TATGAGTACGAGTTCATGGAGCTGGCCTGCCAGTGCCCGGCCGTAGTCTGCTGCCGATGT GCCCCCACCCAGAAGGCCCAGATCGTGCGCCTGCTTCAGGAGCGCACGGGCAAGCTCACC TGTGCAGTAGGGGACGGAGGCAATGACGTCAGCATGATTCAGGAATCTGACTGCGGCGTG GGAGTGGAAGGAAAGGAAGGAAAACAGGCTTCGTTGGCTGCAGACTTCTCCATCACTCAA TTTAAGCATCTTGGCCGGTTGCTTATGGTGCATGGCCGGAACAGCTACAAGCGGTCAGCC GCCCTCAGCCAGTTCGTGATTCACAGGAGCCTCTGTATCAGCACCATGCAGGCTGTCTTT TCCTCCGTGTTTTACTTTGCCTCCGTCCCTCTCTATCAAGGATTCCTCATCATTGGGTAC TCCACAATTTACACCATGTTTCCTGTGTTTTCTCTGGTCCTGGACAAAGATGTCAAATCG GAAGTTGCCATGCTGTATCCTGAGCTCTACAAGGATCTTCTCAAGGGACGGCCGTTGTCC TACAAGACATTCTTAATATGGGTTTTGATTAGCATCTATCAAGGGAGCACCATCATGTAC GGGGCGCTGCTGCTGTTTGAGTCGGAGTTCGTGCACATCGTGGCCATCTCCTTCACCTCG CTGATCCTCACCGAGCTGCTCATGGTGGCGCTGACCATCCAGACCTGGCACTGGCTCATG ACAGTGGCGGAGCTGCTCAGCCTGGCCTGCTACATCGCCTCCCTGGTGTTCTTACACGAG TTCATCGATGTGTACTTCATCGCCACCTTGTCATTCTTGTGGAAAGTCTCCGTCATCACT CTGGTCAGCTGCCTCCCCCTCTATGTCCTCAAGTACCTGCGAAGACGGTTCTCTCCCCCC AGCTACTCAAAGCTCACATCAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTA GAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGA GTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGT CTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAAC CGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCT TGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTT CTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTT GCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAG CCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCA AGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCAC GCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACA ATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTT GTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCG TGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGA AGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCT CCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCG GCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATG GAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCC GAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCAT GGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGAC TGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATT GCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCT CCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTC TGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGT AATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCA GCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCC CCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACT ATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCT GCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAG CTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCA CGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAA CCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGC GAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAG AAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGG TAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCA GCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTC TGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAG GATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTT CGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTG GCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCG GCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAAC GCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCG TAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGA TCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTT GCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACG CCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATC AAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGG TGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAAC GGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGA AGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAA ATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}