


-
SpecieshumanProduct IDFXC00375Cloning SiteSgfI-PmeISymbolEFTUD2
Alias : MFDGA, MFDM, SNRNP116, Snrp116, Snu114, U5-116KDDescriptionelongation factor Tu GTP binding domain containing 2, transcript variant 1 Length: 2916 bp
Length: 2916 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 972 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)

Entry Exp ID% symbol CCDS11489.1 0 100.0 EFTUD2 CCDS45707.1 0 100.0 EFTUD2 CCDS59295.1 0 99.0 EFTUD2 CCDS12117.1 1.4e-90 39.2 EEF2 CCDS42071.1 9.4e-18 25.7 EFL1
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]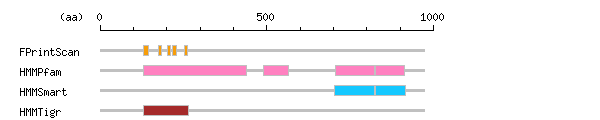 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR000795 131 144 PR00315 Protein synthesis factor IPR000795 176 184 PR00315 Protein synthesis factor IPR000795 201 211 PR00315 Protein synthesis factor IPR000795 217 228 PR00315 Protein synthesis factor IPR000795 253 262 PR00315 Protein synthesis factor HMMPfam IPR000795 129 439 PF00009 Protein synthesis factor IPR004161 491 566 PF03144 Translation elongation factor EFTu/EF1A IPR005517 707 823 PF03764 Translation elongation factor EFG/EF2 IPR000640 826 914 PF00679 Translation elongation factor EFG/EF2 HMMSmart IPR005517 703 824 SM00889 Translation elongation factor EFG/EF2 IPR000640 826 915 SM00838 Translation elongation factor EFG/EF2 HMMTigr IPR005225 130 264 TIGR00231 Small GTP-binding protein domain
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_001245282 972 603892,610536 100.0 100.0 NP_004238 972 603892,610536 100.0 100.0 NP_001136077 937 603892,610536 100.0 96.4 NP_001245283 962 603892,610536 99.0 100.0 NP_001952 858 130610,609306 39.2 86.5 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KSDA0031 Download>KIAA0031 2916 bp ATGGATACCGACTTATATGATGAGTTTGGGAATTATATTGGACCAGAGCTTGATTCTGAT GAAGATGATGATGAATTGGGTAGAGAGACCAAAGATCTTGATGAGATGGATGATGATGAC GACGACGATGACGTAGGAGATCATGACGATGACCACCCTGGGATGGAGGTGGTGCTGCAT GAGGACAAGAAGTACTACCCAACAGCCGAGGAGGTGTATGGTCCTGAGGTGGAGACCATA GTTCAAGAGGAAGACACTCAGCCTCTCACAGAACCCATTATTAAGCCAGTGAAAACCAAG AAATTCACTCTGATGGAGCAGACATTACCTGTTACGGTGTATGAGATGGATTTCTTGGCG GATCTGATGGATAACTCAGAGCTCATCAGAAATGTGACCCTTTGTGGACATCTCCACCAT GGCAAGACATGTTTTGTGGATTGTTTAATTGAACAGACTCACCCGGAAATCAGAAAGCGC TATGACCAAGATCTGTGCTATACTGACATCCTCTTCACAGAGCAAGAGAGAGGTGTAGGC ATCAAAAGCACTCCTGTGACAGTGGTCTTGCCAGACACCAAAGGAAAATCTTATCTCTTC AATATCATGGACACTCCAGGACATGTGAATTTCTCTGATGAGGTCACAGCTGGCTTGCGC ATCTCAGATGGAGTGGTCCTTTTCATTGATGCTGCTGAGGGGGTGATGCTGAACACAGAG CGGCTGATCAAGCATGCGGTGCAGGAGAGGCTGGCAGTCACTGTGTGCATCAACAAGATT GACCGGCTGATCCTGGAGCTGAAGCTGCCTCCAACTGATGCTTATTACAAGCTGCGCCAC ATTGTGGATGAGGTCAATGGATTAATAAGCATGTATTCCACTGATGAGAACCTGATCCTT TCCCCACTCCTGGGTAACGTCTGCTTCTCCAGCTCCCAGTACAGCATCTGCTTCACGCTG GGCTCCTTTGCCAAGATCTATGCCGACACCTTTGGTGACATTAATTACCAAGAATTTGCT AAAAGACTCTGGGGTGACATCTACTTCAACCCTAAGACGCGAAAGTTCACCAAAAAGGCC CCAACTAGCAGCTCCCAGAGAAGTTTCGTGGAGTTTATCTTGGAGCCTCTTTATAAGATC CTCGCCCAGGTTGTAGGTGACGTGGACACCAGCCTCCCACGGACCCTAGACGAGCTTGGC ATCCACCTGACGAAGGAGGAGCTGAAGCTGAACATCCGCCCCTTGCTCAGGCTGGTCTGC AAAAAGTTCTTTGGCGAGTTCACAGGCTTTGTGGACATGTGTGTGCAGCATATCCCTTCT CCAAAGGTGGGCGCCAAGCCCAAGATTGAGCACACCTACACCGGTGGTGTGGACTCCGAC CTCGGCGAGGCTATGAGTGACTGTGACCCTGATGGCCCCCTGATGTGCCACACTACTAAG ATGTACAGCACAGATGATGGAGTCCAGTTTCACGCCTTTGGCCGGGTGCTGAGTGGCACC ATTCATGCTGGGCAGCCTGTGAAGGTACTGGGGGAGAACTACACCCTGGAGGATGAGGAA GACTCCCAGATATGCACCGTGGGCCGCCTTTGGATCTCTGTGGCCAGGTACCACATCGAG GTGAACCGTGTTCCTGCTGGCAACTGGGTTCTGATTGAAGGTGTTGATCAACCAATTGTG AAGACAGCAACCATAACCGAACCCCGAGGCAATGAGGAGGCTCAGATTTTCCGACCCTTG AAGTTCAATACCACATCTGTTATCAAGATTGCTGTGGAGCCAGTCAACCCCTCAGAGCTG CCCAAGATGCTTGATGGCCTGCGCAAGGTCAACAAGAGCTATCCATCCCTCACCACCAAG GTGGAGGAGTCTGGCGAGCATGTGATCCTGGGCACTGGGGAGCTCTACCTGGACTGTGTG ATGCATGATTTGCGGAAGATGTACTCAGAGATAGACATCAAGGTGGCTGACCCAGTTGTC ACGTTTTGTGAGACGGTGGTGGAAACATCCTCCCTCAAGTGCTTTGCTGAAACGCCTAAT AAGAAGAACAAGATCACCATGATTGCTGAGCCTCTTGAGAAGGGCCTGGCAGAGGACATA GAGAATGAGGTGGTCCAGATTACGTGGAACAGGAAGAAGCTGGGAGAGTTCTTCCAGACC AAGTACGATTGGGATCTGCTGGCTGCCCGTTCCATCTGGGCTTTTGGCCCTGATGCGACT GGCCCCAACATTCTGGTGGATGATACTCTGCCCTCTGAGGTGGACAAGGCTCTTCTTGGT TCAGTGAAGGACAGCATCGTTCAAGGTTTCCAGTGGGGAACCAGGGAGGGCCCCCTCTGT GATGAATTGATTCGGAATGTCAAGTTTAAGATCCTGGATGCGGTGGTTGCCCAGGAGCCC CTGCACCGGGGCGGGGGCCAGATCATCCCCACAGCCAGGAGAGTCGTCTACTCTGCCTTC CTCATGGCTACTCCTCGTCTGATGGAGCCTTACTACTTTGTAGAGGTCCAGGCCCCTGCA GATTGCGTCTCTGCAGTTTATACCGTCCTGGCCAGGCGCAGGGGGCACGTGACTCAGGAT GCACCCATCCCAGGCTCCCCTCTGTACACCATCAAAGCTTTTATCCCGGCCATCGACTCT TTTGGCTTTGAGACTGATCTCCGGACTCACACCCAGGGACAAGCCTTTTCTCTGTCTGTC TTCCACCACTGGCAGATTGTGCCTGGTGATCCCCTGGACAAGAGCATTGTCATCCGCCCC TTGGAGCCACAGCCAGCTCCTCACCTGGCCCGGGAATTCATGATCAAAACCCGCCGTAGG AAGGGCCTCAGTGAAGATGTGAGCATCAGCAAATTCTTCGATGATCCTATGTTGCTGGAA CTTGCCAAACAGGATGTTGTGCTCAATTACCCCATG
Cloned ORF protein sequence for pF1KSDA0031 Download>KIAA0031 972 aa MDTDLYDEFGNYIGPELDSDEDDDELGRETKDLDEMDDDDDDDDVGDHDDDHPGMEVVLH EDKKYYPTAEEVYGPEVETIVQEEDTQPLTEPIIKPVKTKKFTLMEQTLPVTVYEMDFLA DLMDNSELIRNVTLCGHLHHGKTCFVDCLIEQTHPEIRKRYDQDLCYTDILFTEQERGVG IKSTPVTVVLPDTKGKSYLFNIMDTPGHVNFSDEVTAGLRISDGVVLFIDAAEGVMLNTE RLIKHAVQERLAVTVCINKIDRLILELKLPPTDAYYKLRHIVDEVNGLISMYSTDENLIL SPLLGNVCFSSSQYSICFTLGSFAKIYADTFGDINYQEFAKRLWGDIYFNPKTRKFTKKA PTSSSQRSFVEFILEPLYKILAQVVGDVDTSLPRTLDELGIHLTKEELKLNIRPLLRLVC KKFFGEFTGFVDMCVQHIPSPKVGAKPKIEHTYTGGVDSDLGEAMSDCDPDGPLMCHTTK MYSTDDGVQFHAFGRVLSGTIHAGQPVKVLGENYTLEDEEDSQICTVGRLWISVARYHIE VNRVPAGNWVLIEGVDQPIVKTATITEPRGNEEAQIFRPLKFNTTSVIKIAVEPVNPSEL PKMLDGLRKVNKSYPSLTTKVEESGEHVILGTGELYLDCVMHDLRKMYSEIDIKVADPVV TFCETVVETSSLKCFAETPNKKNKITMIAEPLEKGLAEDIENEVVQITWNRKKLGEFFQT KYDWDLLAARSIWAFGPDATGPNILVDDTLPSEVDKALLGSVKDSIVQGFQWGTREGPLC DELIRNVKFKILDAVVAQEPLHRGGGQIIPTARRVVYSAFLMATPRLMEPYYFVEVQAPA DCVSAVYTVLARRRGHVTQDAPIPGSPLYTIKAFIPAIDSFGFETDLRTHTQGQAFSLSV FHHWQIVPGDPLDKSIVIRPLEPQPAPHLAREFMIKTRRRKGLSEDVSISKFFDDPMLLE LAKQDVVLNYPM
Nucleotide Sequence (with vector) for pF1KSDA0031 Download>pF1KSDA0031 6053 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT AGAACCATGGATACCGACTTATATGATGAGTTTGGGAATTATATTGGACCAGAGCTTGAT TCTGATGAAGATGATGATGAATTGGGTAGAGAGACCAAAGATCTTGATGAGATGGATGAT GATGACGACGACGATGACGTAGGAGATCATGACGATGACCACCCTGGGATGGAGGTGGTG CTGCATGAGGACAAGAAGTACTACCCAACAGCCGAGGAGGTGTATGGTCCTGAGGTGGAG ACCATAGTTCAAGAGGAAGACACTCAGCCTCTCACAGAACCCATTATTAAGCCAGTGAAA ACCAAGAAATTCACTCTGATGGAGCAGACATTACCTGTTACGGTGTATGAGATGGATTTC TTGGCGGATCTGATGGATAACTCAGAGCTCATCAGAAATGTGACCCTTTGTGGACATCTC CACCATGGCAAGACATGTTTTGTGGATTGTTTAATTGAACAGACTCACCCGGAAATCAGA AAGCGCTATGACCAAGATCTGTGCTATACTGACATCCTCTTCACAGAGCAAGAGAGAGGT GTAGGCATCAAAAGCACTCCTGTGACAGTGGTCTTGCCAGACACCAAAGGAAAATCTTAT CTCTTCAATATCATGGACACTCCAGGACATGTGAATTTCTCTGATGAGGTCACAGCTGGC TTGCGCATCTCAGATGGAGTGGTCCTTTTCATTGATGCTGCTGAGGGGGTGATGCTGAAC ACAGAGCGGCTGATCAAGCATGCGGTGCAGGAGAGGCTGGCAGTCACTGTGTGCATCAAC AAGATTGACCGGCTGATCCTGGAGCTGAAGCTGCCTCCAACTGATGCTTATTACAAGCTG CGCCACATTGTGGATGAGGTCAATGGATTAATAAGCATGTATTCCACTGATGAGAACCTG ATCCTTTCCCCACTCCTGGGTAACGTCTGCTTCTCCAGCTCCCAGTACAGCATCTGCTTC ACGCTGGGCTCCTTTGCCAAGATCTATGCCGACACCTTTGGTGACATTAATTACCAAGAA TTTGCTAAAAGACTCTGGGGTGACATCTACTTCAACCCTAAGACGCGAAAGTTCACCAAA AAGGCCCCAACTAGCAGCTCCCAGAGAAGTTTCGTGGAGTTTATCTTGGAGCCTCTTTAT AAGATCCTCGCCCAGGTTGTAGGTGACGTGGACACCAGCCTCCCACGGACCCTAGACGAG CTTGGCATCCACCTGACGAAGGAGGAGCTGAAGCTGAACATCCGCCCCTTGCTCAGGCTG GTCTGCAAAAAGTTCTTTGGCGAGTTCACAGGCTTTGTGGACATGTGTGTGCAGCATATC CCTTCTCCAAAGGTGGGCGCCAAGCCCAAGATTGAGCACACCTACACCGGTGGTGTGGAC TCCGACCTCGGCGAGGCTATGAGTGACTGTGACCCTGATGGCCCCCTGATGTGCCACACT ACTAAGATGTACAGCACAGATGATGGAGTCCAGTTTCACGCCTTTGGCCGGGTGCTGAGT GGCACCATTCATGCTGGGCAGCCTGTGAAGGTACTGGGGGAGAACTACACCCTGGAGGAT GAGGAAGACTCCCAGATATGCACCGTGGGCCGCCTTTGGATCTCTGTGGCCAGGTACCAC ATCGAGGTGAACCGTGTTCCTGCTGGCAACTGGGTTCTGATTGAAGGTGTTGATCAACCA ATTGTGAAGACAGCAACCATAACCGAACCCCGAGGCAATGAGGAGGCTCAGATTTTCCGA CCCTTGAAGTTCAATACCACATCTGTTATCAAGATTGCTGTGGAGCCAGTCAACCCCTCA GAGCTGCCCAAGATGCTTGATGGCCTGCGCAAGGTCAACAAGAGCTATCCATCCCTCACC ACCAAGGTGGAGGAGTCTGGCGAGCATGTGATCCTGGGCACTGGGGAGCTCTACCTGGAC TGTGTGATGCATGATTTGCGGAAGATGTACTCAGAGATAGACATCAAGGTGGCTGACCCA GTTGTCACGTTTTGTGAGACGGTGGTGGAAACATCCTCCCTCAAGTGCTTTGCTGAAACG CCTAATAAGAAGAACAAGATCACCATGATTGCTGAGCCTCTTGAGAAGGGCCTGGCAGAG GACATAGAGAATGAGGTGGTCCAGATTACGTGGAACAGGAAGAAGCTGGGAGAGTTCTTC CAGACCAAGTACGATTGGGATCTGCTGGCTGCCCGTTCCATCTGGGCTTTTGGCCCTGAT GCGACTGGCCCCAACATTCTGGTGGATGATACTCTGCCCTCTGAGGTGGACAAGGCTCTT CTTGGTTCAGTGAAGGACAGCATCGTTCAAGGTTTCCAGTGGGGAACCAGGGAGGGCCCC CTCTGTGATGAATTGATTCGGAATGTCAAGTTTAAGATCCTGGATGCGGTGGTTGCCCAG GAGCCCCTGCACCGGGGCGGGGGCCAGATCATCCCCACAGCCAGGAGAGTCGTCTACTCT GCCTTCCTCATGGCTACTCCTCGTCTGATGGAGCCTTACTACTTTGTAGAGGTCCAGGCC CCTGCAGATTGCGTCTCTGCAGTTTATACCGTCCTGGCCAGGCGCAGGGGGCACGTGACT CAGGATGCACCCATCCCAGGCTCCCCTCTGTACACCATCAAAGCTTTTATCCCGGCCATC GACTCTTTTGGCTTTGAGACTGATCTCCGGACTCACACCCAGGGACAAGCCTTTTCTCTG TCTGTCTTCCACCACTGGCAGATTGTGCCTGGTGATCCCCTGGACAAGAGCATTGTCATC CGCCCCTTGGAGCCACAGCCAGCTCCTCACCTGGCCCGGGAATTCATGATCAAAACCCGC CGTAGGAAGGGCCTCAGTGAAGATGTGAGCATCAGCAAATTCTTCGATGATCCTATGTTG CTGGAACTTGCCAAACAGGATGTTGTGCTCAATTACCCCATGTACGTAGTTTAAACGAAT TCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGC TGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGC ATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTAT ATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACT GCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCT GACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCT TTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCT GGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCG CCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTT CGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTA TTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTG TCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAA CTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCT GTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGG CAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCA ATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACAT CGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGAC GAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCG GATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAA AATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAG GACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGC TTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTT CTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCA ACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGC AGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTT GCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAG TCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTC CCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCC TTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGT CGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTT ATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGC AGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAA GTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAA GCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGG TAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGA AGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGG GATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAA TACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGC TTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATAC GGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTAC CTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTAT GGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCA CGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACG CAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGA CCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCA TGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGG CCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGG GAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCAT AAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTC TACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}