


-
SpecieshumanProduct IDFXC00380Cloning SiteSgfI-PmeISymbolADCY7
Alias : AC7Descriptionadenylate cyclase 7, transcript variant 1 Length: 3240 bp
Length: 3240 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 1080 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
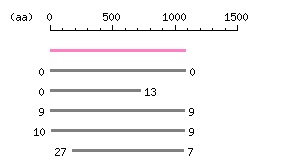
Entry Exp ID% symbol CCDS10741.1 0 100.0 ADCY7 CCDS73882.1 0 99.9 ADCY7 CCDS3872.2 1.7e-217 55.3 ADCY2 CCDS9627.1 7.1e-198 52.8 ADCY4 CCDS56274.1 2.5e-100 40.2 ADCY5
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]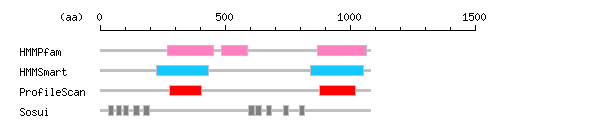 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition HMMPfam IPR001054 271 452 PF00211 Adenylyl cyclase class-3/4/guanylyl cyclase IPR009398 485 591 PF06327 Adenylate cyclase-like IPR001054 871 1067 PF00211 Adenylyl cyclase class-3/4/guanylyl cyclase HMMSmart IPR001054 224 432 SM00044 Adenylyl cyclase class-3/4/guanylyl cyclase IPR001054 840 1052 SM00044 Adenylyl cyclase class-3/4/guanylyl cyclase ProfileScan IPR001054 279 406 PS50125 Adenylyl cyclase class-3/4/guanylyl cyclase IPR001054 879 1023 PS50125 Adenylyl cyclase class-3/4/guanylyl cyclase
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 32 GPLLLTLLLVAATACVALIIIAF 54 PRIMARY 23 2 65 ILGMAFLVLAVFAALSVLMYVEC 87 PRIMARY 23 3 93 LRALALLTWACLVALGYVLVFDA 115 PRIMARY 23 4 135 VVYTLLPFSMRGAVAVGAVSTAS 157 PRIMARY 23 5 174 VRVGLQLLANAVIFLCGNLTGAF 196 SECONDARY 23 6 595 HDFACASLIFVCILLVHVLLMPR 617 PRIMARY 23 7 622 GVSFGLVACVLGLVLGLCFATKF 644 PRIMARY 23 8 665 PLLRLTLAVLTIGSLLTVAIINL 687 SECONDARY 23 9 732 ACSVFLRMSLEPKVVLLTVALVA 754 PRIMARY 23 10 796 KTMTNFYLVLFYITLLTLSRQID 818 SECONDARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_001105 1080 600385 100.0 100.0 XP_016878384 1080 600385 100.0 100.0 XP_011521142 1086 600385 99.4 100.0 XP_011521140 1086 600385 99.4 100.0 XP_011521139 1086 600385 99.4 100.0 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KSDA0037 Download>KIAA0037 3240 bp ATGCCAGCCAAGGGGCGCTACTTCCTCAACGAGGGCGAGGAGGGCCCTGACCAAGATGCG CTCTACGAGAAGTACCAGCTCACCAGCCAGCATGGGCCGCTGCTGCTCACGCTCCTGCTG GTGGCCGCCACTGCCTGCGTGGCCCTCATCATCATTGCCTTCAGCCAGGGGGACCCCTCC AGACACCAGGCCATTCTGGGCATGGCGTTCCTGGTGCTGGCGGTGTTTGCGGCCCTCTCT GTGCTGATGTACGTCGAGTGTCTCCTGCGGCGCTGGCTCAGGGCCTTGGCGCTGCTCACC TGGGCCTGCTTGGTGGCGCTGGGCTATGTGCTGGTGTTCGACGCATGGACAAAGGCGGCC TGTGCGTGGGAGCAGGTGCCCTTCTTCCTGTTCATTGTCTTCGTGGTGTACACACTACTG CCCTTCAGCATGCGGGGCGCTGTCGCCGTTGGGGCCGTCTCCACTGCCTCCCACCTCCTG GTGCTCGGTTCTTTGATGGGAGGCTTCACGACACCCAGTGTCCGGGTGGGGCTGCAGCTG CTGGCCAACGCAGTCATCTTCCTGTGTGGGAACCTGACAGGCGCCTTCCACAAGCACCAA ATGCAGGATGCGTCCCGGGACCTCTTCACCTACACTGTGAAGTGCATCCAGATCCGCCGG AAGCTGCGCATCGAGAAGCGCCAGCAGGAGAACCTGCTGCTGTCAGTGCTTCCGGCCCAC ATCTCCATGGGCATGAAGCTGGCCATCATCGAACGGCTCAAGGAGCATGGTGACCGTCGC TGCATGCCTGACAACAACTTCCACAGCCTCTACGTCAAGAGGCACCAGAATGTCAGCATC CTCTATGCGGACATCGTGGGCTTCACGCAGCTGGCCAGCGACTGTTCTCCCAAGGAGCTG GTGGTGGTGCTGAATGAGCTCTTTGGCAAGTTCGACCAGATCGCCAAGGCCAACGAGTGC ATGCGAATCAAGATCCTCGGCGACTGCTACTACTGTGTATCGGGCCTGCCCGTGTCGCTG CCTACCCACGCCCGGAACTGCGTGAAGATGGGGCTGGACATGTGCCAGGCCATCAAGCAG GTGCGGGAGGCCACGGGCGTGGACATCAACATGCGTGTGGGCATACACTCGGGGAATGTG CTGTGCGGGGTCATCGGGCTGCGCAAGTGGCAGTATGACGTGTGGTCCCACGACGTGTCC CTGGCCAACCGGATGGAGGCAGCCGGAGTACCCGGCCGGGTGCACATCACGGAGGCCACG CTAAAGCACCTGGACAAGGCGTACGAGGTGGAGGATGGGCACGGGCAGCAGCGGGACCCC TACCTCAAGGAGATGAACATCCGCACCTACCTGGTCATCGACCCCCGGAGCCAGCAGCCA CCCCCGCCCAGCCAACACCTCCCCAGGCCCAAGGGGGACGCGGCCCTGAAGATGCGGGCG TCAGTGCGCATGACCCGGTACCTCGAGTCCTGGGGGGCGGCACGGCCCTTTGCACATCTC AACCACCGTGAGAGCGTGAGCAGTGGTGAGACCCACGTCCCCAACGGGCGGAGGCCTAAG AGCGTTCCCCAGCGCCACCGCCGGACCCCAGACAGAAGCATGTCCCCCAAGGGGCGGTCG GAGGATGACTCGTACGATGACGAGATGCTGTCAGCCATTGAGGGGCTCAGCTCCACGAGG CCCTGCTGCTCCAAGTCCGATGACTTCTACACCTTTGGGTCCATCTTCCTGGAGAAGGGC TTTGAGCGCGAGTACCGCCTGGCACCCATCCCCCGGGCCCGCCACGACTTTGCCTGCGCC AGCCTGATCTTCGTCTGCATCCTGCTCGTCCATGTCCTGCTCATGCCCAGGACGGCGGCA CTGGGTGTGTCCTTCGGGCTGGTGGCCTGTGTACTGGGGCTGGTGCTGGGCCTGTGCTTT GCCACCAAGTTCTCGAGGTGCTGCCCAGCTCGGGGGACGCTCTGCACTATCTCTGAGAGG GTGGAGACACAGCCCCTGCTGAGGCTGACCCTGGCCGTCCTGACCATCGGCAGCCTGCTC ACTGTGGCCATCATCAACCTGCCCCTGATGCCTTTCCAAGTTCCAGAGCTGCCTGTTGGC AATGAGACAGGCCTACTGGCCGCGAGCAGCAAGACAAGAGCCCTGTGTGAGCCCCTCCCG TACTACACCTGCAGCTGTGTCCTGGGCTTCATCGCCTGCTCGGTCTTCCTGAGGATGAGC CTGGAGCCAAAGGTTGTGCTGCTGACAGTGGCCCTGGTGGCCTACCTGGTGCTCTTCAAC CTCTCCCCATGCTGGCAGTGGGACTGCTGCGGCCAAGGCCTGGGCAACCTCACCAAGCCC AACGGCACCACCAGTGGCACCCCTAGCTGTTCCTGGAAGGACCTGAAGACCATGACCAAT TTCTACCTGGTCCTGTTCTACATCACCCTGCTTACACTCTCCAGACAGATTGACTATTAC TGCCGCTTGGACTGCCTATGGAAGAAGAAGTTCAAGAAGGAGCACGAGGAGTTTGAGACC ATGGAGAACGTGAACCGCCTTCTTCTGGAGAACGTCCTGCCAGCCCACGTGGCTGCCCAC TTTATCGGTGACAAGTTAAACGAGGACTGGTACCATCAGTCCTATGACTGCGTCTGTGTC ATGTTTGCCTCCGTGCCGGACTTCAAAGTGTTCTACACAGAGTGCGATGTCAACAAAGAA GGGCTGGAGTGCCTACGCCTGCTCAATGAGATCATTGCCGACTTCGACGAGCTCCTACTG AAGCCCAAGTTCAGCGGCGTGGAGAAGATCAAGACCATCGGCAGCACGTACATGGCAGCT GCAGGGCTCAGCGTCGCCTCAGGGCACGAGAACCAGGAGCTGGAGCGGCAGCATGCCCAC ATTGGTGTCATGGTGGAGTTCAGCATCGCCCTGATGAGTAAGCTGGACGGCATCAACAGG CACTCCTTCAACTCCTTCCGCCTCCGCGTCGGCATAAACCATGGGCCTGTGATTGCTGGA GTGATTGGGGCCCGAAAACCTCAGTATGACATCTGGGGAAACACTGTCAATGTGGCCAGC CGAATGGAAAGCACTGGAGAACTTGGGAAAATCCAGGTTACCGAGGAGACCTGCACCATC CTCCAGGGCCTCGGGTACTCTTGTGAATGCCGTGGCCTGATCAACGTCAAAGGCAAAGGC GAGCTGAGGACTTACTTTGTCTGTACGGACACTGCCAAGTTTCAGGGGCTGGGGCTGAAC
Cloned ORF protein sequence for pF1KSDA0037 Download>KIAA0037 1080 aa MPAKGRYFLNEGEEGPDQDALYEKYQLTSQHGPLLLTLLLVAATACVALIIIAFSQGDPS RHQAILGMAFLVLAVFAALSVLMYVECLLRRWLRALALLTWACLVALGYVLVFDAWTKAA CAWEQVPFFLFIVFVVYTLLPFSMRGAVAVGAVSTASHLLVLGSLMGGFTTPSVRVGLQL LANAVIFLCGNLTGAFHKHQMQDASRDLFTYTVKCIQIRRKLRIEKRQQENLLLSVLPAH ISMGMKLAIIERLKEHGDRRCMPDNNFHSLYVKRHQNVSILYADIVGFTQLASDCSPKEL VVVLNELFGKFDQIAKANECMRIKILGDCYYCVSGLPVSLPTHARNCVKMGLDMCQAIKQ VREATGVDINMRVGIHSGNVLCGVIGLRKWQYDVWSHDVSLANRMEAAGVPGRVHITEAT LKHLDKAYEVEDGHGQQRDPYLKEMNIRTYLVIDPRSQQPPPPSQHLPRPKGDAALKMRA SVRMTRYLESWGAARPFAHLNHRESVSSGETHVPNGRRPKSVPQRHRRTPDRSMSPKGRS EDDSYDDEMLSAIEGLSSTRPCCSKSDDFYTFGSIFLEKGFEREYRLAPIPRARHDFACA SLIFVCILLVHVLLMPRTAALGVSFGLVACVLGLVLGLCFATKFSRCCPARGTLCTISER VETQPLLRLTLAVLTIGSLLTVAIINLPLMPFQVPELPVGNETGLLAASSKTRALCEPLP YYTCSCVLGFIACSVFLRMSLEPKVVLLTVALVAYLVLFNLSPCWQWDCCGQGLGNLTKP NGTTSGTPSCSWKDLKTMTNFYLVLFYITLLTLSRQIDYYCRLDCLWKKKFKKEHEEFET MENVNRLLLENVLPAHVAAHFIGDKLNEDWYHQSYDCVCVMFASVPDFKVFYTECDVNKE GLECLRLLNEIIADFDELLLKPKFSGVEKIKTIGSTYMAAAGLSVASGHENQELERQHAH IGVMVEFSIALMSKLDGINRHSFNSFRLRVGINHGPVIAGVIGARKPQYDIWGNTVNVAS RMESTGELGKIQVTEETCTILQGLGYSCECRGLINVKGKGELRTYFVCTDTAKFQGLGLN
Nucleotide Sequence (with vector) for pF1KSDA0037 Download>pF1KSDA0037 6377 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT AGAACCATGCCAGCCAAGGGGCGCTACTTCCTCAACGAGGGCGAGGAGGGCCCTGACCAA GATGCGCTCTACGAGAAGTACCAGCTCACCAGCCAGCATGGGCCGCTGCTGCTCACGCTC CTGCTGGTGGCCGCCACTGCCTGCGTGGCCCTCATCATCATTGCCTTCAGCCAGGGGGAC CCCTCCAGACACCAGGCCATTCTGGGCATGGCGTTCCTGGTGCTGGCGGTGTTTGCGGCC CTCTCTGTGCTGATGTACGTCGAGTGTCTCCTGCGGCGCTGGCTCAGGGCCTTGGCGCTG CTCACCTGGGCCTGCTTGGTGGCGCTGGGCTATGTGCTGGTGTTCGACGCATGGACAAAG GCGGCCTGTGCGTGGGAGCAGGTGCCCTTCTTCCTGTTCATTGTCTTCGTGGTGTACACA CTACTGCCCTTCAGCATGCGGGGCGCTGTCGCCGTTGGGGCCGTCTCCACTGCCTCCCAC CTCCTGGTGCTCGGTTCTTTGATGGGAGGCTTCACGACACCCAGTGTCCGGGTGGGGCTG CAGCTGCTGGCCAACGCAGTCATCTTCCTGTGTGGGAACCTGACAGGCGCCTTCCACAAG CACCAAATGCAGGATGCGTCCCGGGACCTCTTCACCTACACTGTGAAGTGCATCCAGATC CGCCGGAAGCTGCGCATCGAGAAGCGCCAGCAGGAGAACCTGCTGCTGTCAGTGCTTCCG GCCCACATCTCCATGGGCATGAAGCTGGCCATCATCGAACGGCTCAAGGAGCATGGTGAC CGTCGCTGCATGCCTGACAACAACTTCCACAGCCTCTACGTCAAGAGGCACCAGAATGTC AGCATCCTCTATGCGGACATCGTGGGCTTCACGCAGCTGGCCAGCGACTGTTCTCCCAAG GAGCTGGTGGTGGTGCTGAATGAGCTCTTTGGCAAGTTCGACCAGATCGCCAAGGCCAAC GAGTGCATGCGAATCAAGATCCTCGGCGACTGCTACTACTGTGTATCGGGCCTGCCCGTG TCGCTGCCTACCCACGCCCGGAACTGCGTGAAGATGGGGCTGGACATGTGCCAGGCCATC AAGCAGGTGCGGGAGGCCACGGGCGTGGACATCAACATGCGTGTGGGCATACACTCGGGG AATGTGCTGTGCGGGGTCATCGGGCTGCGCAAGTGGCAGTATGACGTGTGGTCCCACGAC GTGTCCCTGGCCAACCGGATGGAGGCAGCCGGAGTACCCGGCCGGGTGCACATCACGGAG GCCACGCTAAAGCACCTGGACAAGGCGTACGAGGTGGAGGATGGGCACGGGCAGCAGCGG GACCCCTACCTCAAGGAGATGAACATCCGCACCTACCTGGTCATCGACCCCCGGAGCCAG CAGCCACCCCCGCCCAGCCAACACCTCCCCAGGCCCAAGGGGGACGCGGCCCTGAAGATG CGGGCGTCAGTGCGCATGACCCGGTACCTCGAGTCCTGGGGGGCGGCACGGCCCTTTGCA CATCTCAACCACCGTGAGAGCGTGAGCAGTGGTGAGACCCACGTCCCCAACGGGCGGAGG CCTAAGAGCGTTCCCCAGCGCCACCGCCGGACCCCAGACAGAAGCATGTCCCCCAAGGGG CGGTCGGAGGATGACTCGTACGATGACGAGATGCTGTCAGCCATTGAGGGGCTCAGCTCC ACGAGGCCCTGCTGCTCCAAGTCCGATGACTTCTACACCTTTGGGTCCATCTTCCTGGAG AAGGGCTTTGAGCGCGAGTACCGCCTGGCACCCATCCCCCGGGCCCGCCACGACTTTGCC TGCGCCAGCCTGATCTTCGTCTGCATCCTGCTCGTCCATGTCCTGCTCATGCCCAGGACG GCGGCACTGGGTGTGTCCTTCGGGCTGGTGGCCTGTGTACTGGGGCTGGTGCTGGGCCTG TGCTTTGCCACCAAGTTCTCGAGGTGCTGCCCAGCTCGGGGGACGCTCTGCACTATCTCT GAGAGGGTGGAGACACAGCCCCTGCTGAGGCTGACCCTGGCCGTCCTGACCATCGGCAGC CTGCTCACTGTGGCCATCATCAACCTGCCCCTGATGCCTTTCCAAGTTCCAGAGCTGCCT GTTGGCAATGAGACAGGCCTACTGGCCGCGAGCAGCAAGACAAGAGCCCTGTGTGAGCCC CTCCCGTACTACACCTGCAGCTGTGTCCTGGGCTTCATCGCCTGCTCGGTCTTCCTGAGG ATGAGCCTGGAGCCAAAGGTTGTGCTGCTGACAGTGGCCCTGGTGGCCTACCTGGTGCTC TTCAACCTCTCCCCATGCTGGCAGTGGGACTGCTGCGGCCAAGGCCTGGGCAACCTCACC AAGCCCAACGGCACCACCAGTGGCACCCCTAGCTGTTCCTGGAAGGACCTGAAGACCATG ACCAATTTCTACCTGGTCCTGTTCTACATCACCCTGCTTACACTCTCCAGACAGATTGAC TATTACTGCCGCTTGGACTGCCTATGGAAGAAGAAGTTCAAGAAGGAGCACGAGGAGTTT GAGACCATGGAGAACGTGAACCGCCTTCTTCTGGAGAACGTCCTGCCAGCCCACGTGGCT GCCCACTTTATCGGTGACAAGTTAAACGAGGACTGGTACCATCAGTCCTATGACTGCGTC TGTGTCATGTTTGCCTCCGTGCCGGACTTCAAAGTGTTCTACACAGAGTGCGATGTCAAC AAAGAAGGGCTGGAGTGCCTACGCCTGCTCAATGAGATCATTGCCGACTTCGACGAGCTC CTACTGAAGCCCAAGTTCAGCGGCGTGGAGAAGATCAAGACCATCGGCAGCACGTACATG GCAGCTGCAGGGCTCAGCGTCGCCTCAGGGCACGAGAACCAGGAGCTGGAGCGGCAGCAT GCCCACATTGGTGTCATGGTGGAGTTCAGCATCGCCCTGATGAGTAAGCTGGACGGCATC AACAGGCACTCCTTCAACTCCTTCCGCCTCCGCGTCGGCATAAACCATGGGCCTGTGATT GCTGGAGTGATTGGGGCCCGAAAACCTCAGTATGACATCTGGGGAAACACTGTCAATGTG GCCAGCCGAATGGAAAGCACTGGAGAACTTGGGAAAATCCAGGTTACCGAGGAGACCTGC ACCATCCTCCAGGGCCTCGGGTACTCTTGTGAATGCCGTGGCCTGATCAACGTCAAAGGC AAAGGCGAGCTGAGGACTTACTTTGTCTGTACGGACACTGCCAAGTTTCAGGGGCTGGGG CTGAACTACGTAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACC TGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGC TGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGG TTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTC TAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTC CCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACT GGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCG TGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAA GTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGAT CAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCT CCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGC TCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACC GACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCC ACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGG CTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAG AAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGC CCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGT CTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTC GCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCC TGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGG CTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAG CTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCG CAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCG AAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTT ATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGC CAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGA GCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATA CCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTAC CGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTG TAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCC CGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAG ACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGT AGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGT ATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTG ATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTAC GCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCA GTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCAC CTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGAT GGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACC CTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTT CGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAG CGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCG AGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAG CCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGG CAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGC CGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAAC GAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTC TCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAG GGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCC TGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCA AATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}