Nucleotide Sequence (with vector) for pF1KSDA0142
Download
>pF1KSDA0142 5077 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT
AGAACCATGACCGACAATAGCAACAATCAACTGGTAGTAAGAGCAAAGTTTAACTTCCAG
CAGACCAATGAGGACGAGCTTTCCTTCTCAAAAGGAGACGTCATCCATGTCACCCGTGTG
GAAGAGGGAGGCTGGTGGGAGGGCACACTCAACGGCCGGACCGGCTGGTTCCCCAGCAAC
TACGTGCGCGAGGTCAAGGCCAGCGAGAAGCCTGTGTCTCCCAAATCAGGAACACTGAAG
AGCCCTCCCAAAGGATTTGATACGACTGCCATAAACAAAAGCTATTACAATGTGGTGCTA
CAGAATATTTTAGAAACAGAAAATGAATATTCTAAAGAACTTCAGACTGTGCTTTCAACG
TACCTACGGCCATTGCAGACCAGTGAGAAGTTAAGTTCAGCAAACATTTCATATTTAATG
GGAAATCTAGAAGAAATATGTTCTTTCCAGCAAATGCTCGTACAGTCTTTAGAAGAATGC
ACCAAGTTGCCCGAAGCTCAGCAGAGAGTCGGAGGCTGCTTTTTAAACCTGATGCCACAG
ATGAAAACCCTGTACCTCACGTATTGTGCCAATCACCCTTCTGCAGTGAATGTCCTCACG
GAACACAGTGAGGAGTTGGGGGAGTTCATGGAGACCAAAGGTGCCAGCAGCCCTGGGATT
CTCGTGCTGACCACGGGCCTGAGCAAACCCTTCATGCGCCTGGATAAATACCCTACGCTG
CTCAAAGAGCTCGAGAGACACATGGAGGATTATCATACAGATAGACAAGATATTCAAAAA
TCCATGGCTGCCTTCAAAAACCTTTCAGCCCAATGTCAAGAAGTCCGGAAGAGGAAAGAG
CTTGAGCTGCAGATCCTGACGGAAGCCATCCGGAACTGGGAGGGCGATGACATTAAAACT
CTGGGCAACGTCACTTACATGTCCCAGGTCCTGATTCAGTGTGCCGGAAGTGAGGAAAAG
AATGAAAGATATCTTCTACTCTTCCCAAATGTTTTGCTAATGTTGTCTGCCAGTCCTAGG
ATGAGTGGCTTTATCTATCAGGGAAAGCTTCCAACGACAGGAATGACAATCACAAAGCTT
GAGGACAGTGAAAATCATAGAAATGCATTTGAAATATCAGGGAGCATGATTGAGCGGATA
TTAGTGTCGTGCAACAACCAGCAGGATCTGCAGGAATGGGTGGAGCACCTACAGAAGCAA
ACGAAGGTCACGTCTGTGGGAAACCCCACCATAAAGCCTCATTCAGTGCCATCTCATACC
CTCCCCTCCCACCCGGTCACTCCGTCCAGCAAGCACGCAGACAGCAAGCCCGCGCCGCTG
ACGCCCGCCTACCACACGCTGCCCCACCCCTCCCACCACGGCACCCCGCACACCACCATC
AACTGGGGACCCCTGGAGCCTCCGAAAACACCCAAGCCCTGGAGCCTGAGCTGCCTGCGG
CCCGCGCCTCCCCTCCGGCCCTCAGCTGCTCTCTGCTACAAGGAGGATCTTAGTAAGAGC
CCTAAGACCATGAAAAAGCTGCTGCCCAAGCGCAAACCTGAACGGAAGCCTTCAGATGAG
GAGTTCGCGTCCCGGAAAAGCACAGCTGCTTTGGAAGAAGATGCTCAGATTCTGAAAGTC
ATTGAAGCTTACTGCACCAGCGCCAAAACAAGGCAAACACTCAATTCAAGTTCACGCAAA
GAATCTGCTCCACAAGTTTTGCTTCCAGAAGAAGAGAAAATTATAGTGGAAGAAACTAAA
AGTAATGGTCAGACAGTGATAGAAGAAAAGAGTCTTGTGGATACCGTATATGCATTAAAG
GATGAAGTTCAAGAATTAAGACAGGACAACAAAAAGATGAAGAAATCTCTAGAGGAAGAA
CAGAGAGCCCGCAAAGACCTGGAGAAGCTGGTGAGGAAAGTCCTGAAGAACATGAATGAT
CCTGCCTGGGATGAGACCAATCTATACGTAGTTTAAACGAATTCGAGCTCGGTACCCGGG
GATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAA
GGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTC
TAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGT
CCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCT
CTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCA
GCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCC
TGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAG
GTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGC
AGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGAT
GGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCA
CAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCG
GTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCG
CGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACT
GAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCT
CACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACG
CTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGC
ACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTC
GCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTC
GTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGA
TTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACC
CGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGT
ATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGA
GCGGGACTCTGGGGTTCGCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCAC
TCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGA
GCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCAT
AGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAAC
CCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCT
GTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCG
CTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTG
GGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGT
CTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGG
ATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTAC
GGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGA
AAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTT
GTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTT
TCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGA
TTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCT
GGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTG
GGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAG
GCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGA
TCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACT
GTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTA
GAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATA
AAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCA
GAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAAC
TGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTG
TTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGT
TGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCA
AATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTT
TATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 1938 bp
Length: 1938 bp Restriction map B
Restriction map B
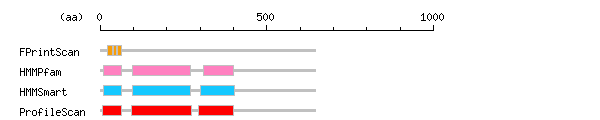
 more Linker info
more Linker info
{kind=link}