Nucleotide Sequence (with vector) for pF1KSDA0200
Download
>pF1KSDA0200 6185 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT
AGAACCATGGTGCTGCCCACCTGCCCCATGGCGGAGTTCGCGCTGCCGCGGCACAGCGCG
GTCATGGAGCGCCTTCGCCGGCGCATCGAGCTGTGCCGGCGCCACCACAGCACCTGCGAG
GCCCGCTACGAGGCCGTGTCGCCCGAGCGCCTGGAGCTGGAGCGCCAACACACCTTCGCC
CTGCACCAGCGCTGCATCCAGGCCAAGGCCAAGCGCGCCGGGAAGCACAGGCAGCCGCCC
GCCGCCACGGCCCCGGCGCCCGCCGCCCCGGCCCCGCGCCTGGACGCCGCTGACGGCCCC
GAGCACGGCCGCCCGGCCACGCATCTTCATGATACAGTTAAGAGGAATCTTGACAGCGCC
ACTTCCCCTCAGAATGGCGATCAACAGAATGGCTACGGGGACCTCTTTCCTGGGCATAAG
AAGACTCGCCGGGAGGCCCCTCTGGGAGTTGCCATCTCTTCCAATGGACTGCCTCCAGCC
TCCCCCCTCGGTCAGTCTGACAAGCCTTCTGGAGCCGACGCCCTGCAGTCCAGTGGGAAG
CACTCTCTGGGGCTAGACTCTCTCAACAAAAAGCGTCTGGCTGACTCCAGCCTTCACTTG
AATGGAGGCAGTAACCCCAGTGAGTCATTTCCTCTGAGCCTGAATAAAGAACTGAAGCAG
GAGCCTGTCGAAGACCTGCCTTGCATGATCACTGGGACTGTCGGCTCCATATCGCAAAGC
AACCTCATGCCAGACCTCAACCTTAACGAGCAGGAGTGGAAGGAGCTCATCGAGGAGCTG
AACAGGTCGGTGCCCGATGAAGACATGAAGGACCTGTTTAATGAGGACTTCGAGGAGAAG
AAGGACCCAGAGTCTTCTGGCTCTGCCACACAAACCCCCTTGGCACAGGACATTAATATT
AAGACGGAATTCTCTCCAGCAGCCTTTGAGCAAGAACAGTTAGGCTCTCCACAAGTGAGG
GCCGGGTCTGCAGGGCAGACCTTTCTGGGGCCTTCCTCTGCCCCTGTGAGTACAGATTCC
CCCAGCCTAGGGGGCTCCCAAACCTTATTCCACACCTCTGGTCAGCCCCGGGCGGACAAT
CCCAGTCCAAACCTGATGCCGGCATCAGCCCAGGCCCAGAACGCACAAAGAGCCCTTGCA
GGTGTGGTATTGCCCAGTCAGGGCCCAGGAGGGGCCTCAGAGCTGTCCTCTGCCCACCAG
CTCCAGCAGATCGCTGCCAAGCAGAAGCGCGAGCAGATGCTCCAGAACCCACAGCAGGCC
ACCCCGGCACCAGCCCCGGGCCAGATGTCCACATGGCAGCAGACGGGGCCCTCCCACAGT
TCCTTAGATGTCCCTTACCCCATGGAGAAGCCTGCCAGCCCTTCCAGCTACAAGCAAGAC
TTCACTAACTCCAAACTGCTCATGATGCCTAGTGTGAATAAGAGTTCCCCTCGGCCCGGA
GGCCCCTACCTCCAGCCCAGCCATGTGAACCTGCTGAGTCACCAGCCACCGAGTAACTTG
AATCAGAACTCCGCGAATAACCAGGGGTCTGTGCTGGACTACGGCAATACAAAACCCCTT
TCTCATTACAAAGCGGACTGTGGGCAAGGCAGCCCGGGGTCTGGCCAGAGCAAGCCAGCC
CTGATGGCTTATCTTCCCCAGCAGCTGTCCCATATAAGTCACGAGCAGAACTCCCTGTTT
CTGATGAAGCCAAAGCCAGGAAATATGCCTTTCCGATCACTGGTTCCACCTGGCCAGGAG
CAGAACCCTTCCAGTGTCCCTGTGCAAGCCCAGGCTACCAGTGTTGGGACCCAGCCGCCT
GCCGTGTCCGTGGCCAGCTCCCACAACAGCTCCCCCTATCTCAGCAGCCAGCAACAGGCC
GCTGTAATGAAGCAGCATCAGTTGCTTTTGGACCAACAGAAACAAAGGGAGCAGCAGCAA
AAGCATTTACAGCAACAGCAGTTCCTTCAGAGGCAACAGCACCTTCTCGCGGAACAGGAG
AAGCAACAGTTTCAGCGCCATCTGACCCGCCCACCACCCCAGTACCAAGACCCGACACAA
GGCAGCTTCCCACAGCAGGTTGGACAGTTCACAGGGTCCTCTGCTGCCGTGCCCGGCATG
AACACCTTGGGTCCATCCAACTCCAGCTGTCCTCGAGTGTTCCCTCAGGCTGGGAATCTG
ATGCCAATGGGCCCTGGACATGCTTCAGTTTCCTCTCTCCCCACAAACTCAGGCCAACAG
GACCGGGGTGTGGCTCAGTTCCCTGGCTCCCAAAACATGCCTCAGAGCAGCCTCTATGGC
ATGGCTTCTGGCATAACCCAGATAGTTGCCCAGCCCCCGCCACAGGCCACCAATGGACAT
GCCCACATTCCACGGCAGACCAACGTGGGCCAGAACACCTCCGTCTCAGCTGCCTATGGG
CAGAACTCTCTGGGAAGCTCTGGCCTCTCCCAGCAGCACAATAAGGGGACCCTGAACCCT
GGTTTAACAAAGCCACCGGTCCCAAGGGTGTCACCAGCCATGGGAGGCCAGAATTCCTCC
TGGCAGCATCAGGGAATGCCGAACCTCAGTGGCCAGACCCCAGGGAACAGCAACGTGAGT
CCCTTCACTGCAGCCTCCAGTTTCCACATGCAGCAGCAGGCCCACCTGAAAATGTCTAGC
CCGCAATTCTCCCAGGCAGTGCCCAACAGGCCCATGGCTCCCATGAGCTCAGCAGCTGCC
GTGGGGTCCTTGCTACCCCCAGTGAGTGCACAGCAGAGGACCAGCGCCCCTGCCCCAGCA
CCACCCCCAACAGCCCCTCAGCAGGGCTTGCCTGGCCTGAGCCCAGCAGGGCCTGAGCTG
GGGGCCTTCAGCCAGAGCCCTGCCTCACAGATGGGCGGTCGGGCGGGGCTGCACTGCACC
CAGGCCTACCCTGTGCGGACCGCGGGCCAGGAGCTGCCTTTTGCCTATAGCGGGCAGCCA
GGTGGCAGTGGGCTCTCTAGTGTGGCTGGACACACCGATCTGATCGACTCCCTGCTGAAG
AACAGGACTTCAGAGGAGTGGATGAGTGATTTGGACGACCTGTTAGGGTCTCAGTACGTA
GTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCA
AGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGA
GCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAA
AGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCA
TGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGAT
AGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGT
GTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAA
GAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATG
GCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGA
TGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGG
GTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCC
GTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGT
GCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTT
CCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGC
GAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATC
ATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCAC
CAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAG
GATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAG
GCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAAT
ATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCG
GACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAA
TGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCC
TTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACC
AAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATC
AGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAA
AAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAA
TCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCC
CCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTC
CGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAG
TTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGA
CCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATC
GCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTAC
AGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTG
CGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACA
AACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAA
AGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAA
CTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTT
ATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATG
AAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCAT
AGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGT
TGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAA
TTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCA
GTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGAT
TAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGT
GGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGT
GGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGT
CGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGA
CAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAG
GACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCC
TTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCG
CTCAT



 Length: 3048 bp
Length: 3048 bp Restriction map B
Restriction map B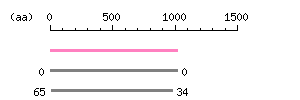

 more Linker info
more Linker info
{kind=link}