Nucleotide Sequence (with vector) for pF1KSDA0222
Download
>pF1KSDA0222 6626 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT
AGAACCATGGATCGCAACAGAGAGGCCGAGATGGAGCTGAGGCGAGGCCCCAGCCCCACC
AGGGCCGGCCGGGGCCACGAGGTGGATGGGGACAAGGCTACCTGCCACACCTGCTGCATC
TGCGGCAAGAGCTTCCCCTTCCAGAGCTCGCTTTCGCAGCACATGCGCAAGCACACGGGC
GAGAAGCCCTACAAGTGTCCCTACTGCGACCACCGGGCTTCCCAGAAGGGCAACCTGAAG
ATTCACATCCGGAGCCACCGCACGGGGACTCTGATTCAGGGACACGAGCCGGAGGCGGGC
GAGGCGCCGCTGGGTGAGATGCGCGCCTCCGAGGGCCTGGACGCCTGCGCCAGCCCCACC
AAGAGCGCCTCTGCCTGCAACCGGCTGCTGAACGGGGCCTCGCAGGCCGACGGCGCCAGG
GTCCTGAACGGGGCCTCGCAGGCCGACAGCGGCAGAGTCCTGCTGCGGAGCAGCAAGAAG
GGGGCAGAGGGGTCCGCATGCGCCCCGGGGGAGGCCAAGGCAGCGGTCCAGTGCTCCTTC
TGCAAGAGCCAGTTCGAGCGTAAGAAGGACCTGGAGCTGCACGTGCACCAGGCGCACAAG
CCGTTCAAGTGCAGGCTGTGCAGCTACGCGACGCTGCGGGAGGAGTCGCTGCTGAGCCAC
ATCGAGAGGGACCACATCACCGCGCAGGGGCCCGGCAGCGGCGAGGCCTGCGTGGAGAAC
GGCAAGCCCGAGCTGAGCCCCGGGGAGTTCCCGTGCGAGGTGTGTGGCCAGGCCTTCAGC
CAGACCTGGTTCCTGAAGGCGCACATGAAGAAGCACCGGGGCTCCTTCGACCACGGCTGC
CACATCTGCGGCCGTAGGTTCAAGGAGCCCTGGTTCCTCAAGAACCACATGAAGGCGCAC
GGCCCCAAGACGGGCAGCAAGAACAGGCCCAAGAGTGAGCTGGACCCCATCGCCACCATC
AACAACGTGGTCCAGGAGGAGGTGATCGTCGCCGGCCTGAGCCTCTACGAGGTCTGCGCC
AAGTGCGGGAACCTGTTTACAAACCTGGACAGCTTGAACGCCCACAATGCCATCCACCGC
AGAGTCGAGGCCAGCCGCACGCGCGCCCCGGCCGAGGAGGGGGCGGAGGGGCCCTCGGAC
ACCAAGCAGTTCTTTCTCCAGTGCCTGAACCTGAGGCCGTCGGCGGCCGGCGACTCGTGC
CCTGGCACGCAGGCCGGACGGCGGGTGGCTGAGCTGGACCCGGTCAACAGCTACCAGGCC
TGGCAGCTGGCCACGCGGGGTAAGGTGGCCGAGCCGGCCGAGTACCTCAAGTACGGGGCC
TGGGACGAGGCGCTGGCCGGGGACGTGGCCTTCGACAAGGACAGGCGCGAGTACGTCCTG
GTGAGCCAGGAGAAGCGCAAGCGTGAGCAGGATGCACCAGCCGCGCAGGGGCCCCCGCGG
AAGCGCGCGAGCGGGCCTGGGGACCCCGCGCCCGCCGGCCACCTCGATCCCCGCTCGGCC
GCGCGCCCCAACCGCAGGGCCGCAGCCACCACCGGCCAGGGCAAGTCCTCCGAGTGCTTC
GAGTGCGGCAAGATCTTCCGCACCTATCATCAGATGGTGCTGCACTCACGCGTGCATCGC
CGCGCGCGCCGCGAGAGGGACAGTGACGGGGACAGGGCGGCGCGGGCCCGCTGCGGATCA
CTCAGTGAGGGTGACTCGGCCTCCCAGCCCAGCAGCCCTGGCTCCGCCTGTGCCGCTGCT
GACTCCCCGGGCTCTGGCCTGGCCGACGAGGCTGCCGAAGACAGTGGTGAGGAGGGCGCC
CCTGAACCTGCACCAGGGGGACAGCCGCGCCGCTGCTGCTTTTCCGAAGAGGTGACTTCG
ACCGAGCTCTCCAGTGGAGACCAGAGTCACAAGATGGGAGATAACGCCTCGGAAAGAGAC
ACCGGCGAGTCCAAGGCAGGGATCGCAGCTTCTGTGTCCATACTTGAAAACAGTAGCAGA
GAGACTTCTAGAAGGCAAGAGCAGCACAGATTTTCTATGGACTTAAAGATGCCAGCATTT
CACCCCAAGCAGGAGGTGCCCGTCCCTGGTGATGGTGTGGAGTTCCCTTCCAGTACGGGA
GCGGAGGGCCAGACGGGTCACCCTGCAGAAAAGCTGTCCGATTTGCACAACAAGGAACAC
TCTGGGGGAGGGAAGCGGGCGCTGGCCCCAGACCTCATGCCGCTAGATTTAAGTGCGAGG
TCGACGCGGGATGACCCCAGCAATAAGGAGACGGCCTCCTCCCTGCAGGCGGCTTTAGTC
GTTCACCCGTGTCCTTACTGCAGCCACAAGACCTACTACCCCGAGGTCCTGTGGATGCAC
AAACGCATCTGGCACCGTGTCAGCTGCAACTCCGTGGCTCCCCCGTGGATTCAGCCCAAT
GGTTACAAAAGCATCAGAAGCAATTTGGTTTTCCTTTCCCGGAGCGGACGCACGGGCCCC
CCGCCTGCCCTCGGTGGCAAAGAATGCCAGCCTTTGCTCCTTGCTCGGTTCACCCGCACT
CAGGTGCCAGGGGGGATGCCGGGGTCCAAAAGTGGCTCTTCTCCCCTGGGAGTGGTCACA
AAAGCCGCTAGCATGCCTAAGAATAAGGAGAGCCATTCCGGAGGTCCCTGCGCTCTGTGG
GCGCCCGGCCCTGACGGGTATCGACAGACCAAACCTTGTCACGGCCAGGAGCCACATGGC
GCGGCCACACAGGGGCCCCTGGCCAAGCCCAGGCAGGAGGCTAGCTCCAAACCGGTGCCT
GCCCCGGGTGGCGGGGGCTTCAGCAGGAGCGCCACCCCTACGCCCACCGTCATCGCCCGG
GCTGGCGCGCAGCCCTCGGCCAATAGCAAGCCTGTGGAGAAGTTTGGGGTCCCCCCAGCG
GGGGCTGGCTTTGCCCCCACAAATAAGCACAGTGCCCCGGACTCCCTGAAAGCCAAATTC
AGTGCTCAGCCTCAGGGTCCACCTCCTGCAAAGGGCGAAGGGGGCGCTCCTCCTCTACCT
CCCCGCGAGCCCCCCTCGAAGGCAGCCCAGGAGCTGAGGACTCTGGCCACCTGTGCTGCG
GGGTCCAGGGGCGACGCGGCCTTGCAGGCCCAGCCCGGCGTGGCTGGGGCGCCCCCCGTC
CTACACTCCATCAAACAGGAGCCAGTGGCCGAGGGGCATGAGAAGCGCCTGGACATCCTC
AACATCTTTAAGACGTACATTCCAAAGGACTTTGCGACCCTCTACCAGGGATGGGGTGTC
AGCGGCCCTGGGTTGGAGCACAGAGGGACACTCCGGACGCAGGCCCGGCCAGGAGAGTTC
GTCTGCATCGAGTGCGGAAAGAGCTTCCACCAGCCCGGCCACCTCAGGGCCCACATGCGG
GCACACTCAGTGGTGTTTGAGTCCGATGGGCCTCGGGGTTCTGAAGTTCATACCACCTCC
GCAGACGCCCCCAAACAAGGGAGAGACCATTCTAACACAGGTACCGTCCAGACAGTGCCT
CTGAGAAAGGGAACCTACGTAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTA
GAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGA
GTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGT
CTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAAC
CGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCT
TGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTT
CTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTT
GCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAG
CCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCA
AGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCAC
GCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACA
ATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTT
GTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCG
TGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGA
AGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCT
CCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCG
GCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATG
GAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCC
GAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCAT
GGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGAC
TGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATT
GCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCT
CCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTC
TGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGT
AATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCA
GCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCC
CCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACT
ATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCT
GCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAG
CTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCA
CGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAA
CCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGC
GAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAG
AAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGG
TAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCA
GCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTC
TGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAG
GATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTT
CGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTG
GCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCG
GCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAAC
GCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCG
TAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGA
TCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTT
GCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACG
CCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATC
AAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGG
TGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAAC
GGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGA
AGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAA
ATACATTCAAATATGTATCCGCTCAT



 Length: 3489 bp
Length: 3489 bp Restriction map B
Restriction map B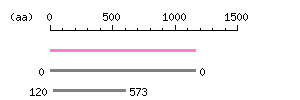

 more Linker info
more Linker info
{kind=link}