


-
SpecieshumanProduct IDFXC00525Cloning SiteSgfI-PmeISymbolPTPRN2
Alias : IA-2beta, IAR, ICAAR, PTPRP, R-PTP-N2Descriptionprotein tyrosine phosphatase, receptor type, N polypeptide 2 Length: 3114 bp
Length: 3114 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 1038 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)

Entry Exp ID% symbol CCDS5947.1 0 99.8 PTPRN2 CCDS5948.1 0 99.8 PTPRN2 CCDS78294.1 0 95.9 PTPRN2 CCDS5949.1 4.7e-132 96.8 PTPRN2 CCDS56167.1 2.1e-90 46.1 PTPRN
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]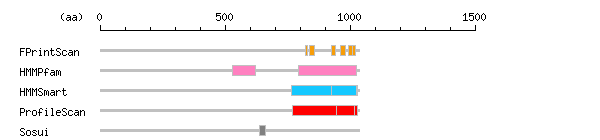 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR000242 822 829 PR00700 Protein-tyrosine phosphatase IPR000242 839 859 PR00700 Protein-tyrosine phosphatase IPR000242 924 941 PR00700 Protein-tyrosine phosphatase IPR000242 963 981 PR00700 Protein-tyrosine phosphatase IPR000242 995 1010 PR00700 Protein-tyrosine phosphatase IPR000242 1011 1021 PR00700 Protein-tyrosine phosphatase HMMPfam IPR021613 531 620 PF11548 Protein-tyrosine phosphatase receptor IA-2 IPR000242 793 1027 PF00102 Protein-tyrosine phosphatase HMMSmart IPR000242 767 1030 SM00194 Protein-tyrosine phosphatase IPR003595 925 1027 SM00404 Protein-tyrosine phosphatase ProfileScan IPR000242 768 1028 PS50055 Protein-tyrosine phosphatase IPR000387 947 1019 PS50056 Protein-tyrosine/Dual-specificity phosphatase
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 639 IALTLVSLACILGVLLASGLIYC 661 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_001295197 1038 601698 99.8 100.0 NP_002838 1015 601698 99.8 94.2 NP_570857 998 601698 99.8 92.6 XP_016867964 949 601698 99.8 91.4 NP_001295196 977 601698 95.9 94.2 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KSDA0387 Download>KIAA0387 3114 bp ATGGCTGTGGAATCTGAATATTCACTGCTGAGAACCGAAGCCAGCTTTCCTACTATGAAG ATGTTCTGTGTGAGCCACACCTTGCCCAGGGTGGAAGTGATGTTTGTTTCAGGTCCACAG ACGAGGGAGAGGACGGAGCCAGTGGACCCTCGGTGGCAGTGTCTGGTGCAGATGTGGGCA GGCTGCCTGCTCGAGGAGGGCCTCTGCGGAGCGTCCGAGGCCTGTGTGAACGATGGAGTG TTTGGAAGGTGCCAGAAGGTTCCGGCAATGGACTTTTACCGCTACGAGGTGTCGCCCGTG GCCCTGCAGCGCCTGCGCGTGGCGTTGCAGAAGCTTTCCGGCACAGGTTTCACGTGGCAG GATGACTATACTCAGTATGTGATGGACCAGGAACTTGCAGACCTCCCGAAAACCTACCTG AGGCGTCCTGAAGCATCCAGCCCAGCCAGGCCCTCAAAACACAGCGTTGGCAGCGAGAGG AGGTACAGTCGGGAGGGCGGTGCTGCCCTGGCCAACGCCCTCCGACGCCACCTGCCCTTC CTGGAGGCCCTGTCCCAGGCCCCAGCCTCAGACGTGCTCGCCAGGACCCATACGGCGCAG GACAGACCCCCCGCTGAGGGTGATGACCGCTTCTCCGAGAGCATCCTGACCTATGTGGCC CACACGTCTGCGCTGACCTACCCTCCCGGGCCCCGGACCCAGCTCCACGAGGACCTCCTG CCACGGACCCTCGGCCAGCTCCAGCCAGATGAGCTCAGCCCTAAGGTGGACAGTGGTGTG GACAGACACCATCTGATGGCGGCCCTCAGTGCCTATGCTGCCCAGAGGCCCCCAGCTCCC CCCGGGGAGGGCAGCCTGGAGCCACAGTACCTTCTGCGTGCACCCTCAAGAATGCCCAGG CCTTTGCTGGCACCAGCCGCCCCCCAGAAGTGGCCTTCACCTCTGGGAGATTCCGAAGAC CCCTCTAGCACAGGCGATGGAGCACGGATTCATACCCTCCTGAAGGACCTGCAGAGGCAG CCGGCTGAGGTGAGGGGCCTGAGTGGCCTGGAGCTGGACGGCATGGCTGAGCTGATGGCT GGCCTGATGCAAGGCGTGGACCATGGAGTAGCTCGAGGCAGCCCTGGGAGAGCGGCCCTG GGAGAGTCTGGAGAACAGGCGGATGGCCCCAAGGCCACCCTCCGTGGAGACAGCTTTCCA GATGACGGAGTGCAGGACGACGATGATAGACTTTACCAAGAGGTCCATCGTCTGAGTGCC ACACTCGGGGGCCTCCTGCAGGACCACGGGTCTCGACTCTTACCTGGAGCCCTCCCCTTT GCAAGGCCCCTCGACATGGAGAGGAAGAAGTCCGAGCACCCTGAGTCTTCCCTGTCTTCA GAAGAGGAGACTGCCGGAGTGGAGAACGTCAAGAGCCAGACGTATTCCAAAGATCTGCTG GGGCAGCAGCCGCATTCGGAGCCCGGGGCCGCTGCGTTTGGGGAGCTCCAAAACCAGATG CCTGGGCCCTCGAAGGAGGAGCAGAGCCTTCCAGCGGGTGCTCAGGAGGCCCTCAGCGAC GGCCTGCAATTGGAGGTCCAGCCTTCCGAGGAAGAGGCGCGGGGCTACATCGTGACAGAC AGAGACCCCCTGCGCCCCGAGGAAGGAAGGCGGCTGGTGGAGGACGTCGCCCGCCTCCTG CAGGTGCCCAGCAGCGCGTTCGCTGACGTGGAGGTTCTCGGACCAGCAGTGACCTTCAAA GTGAGCGCCAATGTCCAAAACGTGACCACTGAGGATGTGGAGAAGGCCACAGTTGACAAC AAAGACAAACTGGAGGAAACCTCTGGACTGAAAATTCTTCAAACCGGAGTCGGGTCGAAA AGCAAACTCAAGTTCCTGCCTCCTCAGGCGGAGCAAGAAGACTCCACCAAGTTCATCGCG CTCACCCTGGTCTCCCTCGCCTGCATCCTGGGCGTCCTCCTGGCCTCTGGCCTCATCTAC TGCCTCCGCCATAGCTCTCAGCACAGGCTGAAGGAGAAGCTCTCGGGACTAGGGGGCGAC CCAGGTGCAGATGCCACTGCCGCCTACCAGGAGCTGTGCCGCCAGCGTATGGCCACGCGG CCACCAGACCGACCTGAGGGCCCGCACACGTCACGCATCAGCAGCGTCTCATCCCAGTTC AGCGACGGGCCGATCCCCAGCCCCTCCGCACGCAGCAGCGCCTCATCCTGGTCCGAGGAG CCTGTGCAGTCCAACATGGACATCTCCACCGGCCACATGATCCTGTCCTACATGGAGGAC CACCTGAAGAACAAGAACCGGCTGGAGAAGGAGTGGGAAGCGCTGTGCGCCTACCAGGCG GAGCCCAACAGCTCGTTCGTGGCCCAGAGGGAGGAGAACGTGCCCAAGAACCGCTCCCTG GCTGTGCTGACCTATGACCACTCCCGGGTCCTGCTGAAGGCGGAGAACAGCCACAGCCAC TCAGACTACATCAACGCTAGCCCCATCATGGATCACGACCCGAGGAACCCCGCGTACATC GCCACCCAGGGACCGCTGCCCGCCACCGTGGCTGACTTTTGGCAGATGGTGTGGGAGAGC GGCTGCGTGGTGATCGTCATGCTGACACCCCTCGCGGAGAACGGCGTCCGGCAGTGCTAC CACTACTGGCCGGATGAAGGCTCCAATCTCTACCACATCTATGAGGTGAACCTGGTCTCC GAGCACATCTGGTGTGAGGACTTCCTGGTGAGGAGCTTCTATCTGAAGAACCTGCAGACC AACGAGACGCGCACCGTGACGCAGTTCCACTTCCTGAGTTGGTATGACCGAGGAGTCCCT TCCTCCTCAAGGTCCCTCCTGGACTTCCGCAGAAAAGTAAACAAGTGCTACAGGGGCCGT TCTTGTCCAATAATTGTTCATTGCAGTGACGGTGCAGGCCGGAGCGGCACCTACGTCCTG ATCGACATGGTTCTCAACAAGATGGCCAAAGGTGCTAAAGAGATTGATATCGCAGCGACC CTGGAGCACTTGAGGGACCAGAGACCCGGCATGGTCCAGACGAAGGAGCAGTTTGAGTTC GCGCTGACAGCCGTGGCTGAGGAGGTGAACGCCATCCTCAAGGCCCTTCCCCAG
Cloned ORF protein sequence for pF1KSDA0387 Download>KIAA0387 1038 aa MAVESEYSLLRTEASFPTMKMFCVSHTLPRVEVMFVSGPQTRERTEPVDPRWQCLVQMWA GCLLEEGLCGASEACVNDGVFGRCQKVPAMDFYRYEVSPVALQRLRVALQKLSGTGFTWQ DDYTQYVMDQELADLPKTYLRRPEASSPARPSKHSVGSERRYSREGGAALANALRRHLPF LEALSQAPASDVLARTHTAQDRPPAEGDDRFSESILTYVAHTSALTYPPGPRTQLHEDLL PRTLGQLQPDELSPKVDSGVDRHHLMAALSAYAAQRPPAPPGEGSLEPQYLLRAPSRMPR PLLAPAAPQKWPSPLGDSEDPSSTGDGARIHTLLKDLQRQPAEVRGLSGLELDGMAELMA GLMQGVDHGVARGSPGRAALGESGEQADGPKATLRGDSFPDDGVQDDDDRLYQEVHRLSA TLGGLLQDHGSRLLPGALPFARPLDMERKKSEHPESSLSSEEETAGVENVKSQTYSKDLL GQQPHSEPGAAAFGELQNQMPGPSKEEQSLPAGAQEALSDGLQLEVQPSEEEARGYIVTD RDPLRPEEGRRLVEDVARLLQVPSSAFADVEVLGPAVTFKVSANVQNVTTEDVEKATVDN KDKLEETSGLKILQTGVGSKSKLKFLPPQAEQEDSTKFIALTLVSLACILGVLLASGLIY CLRHSSQHRLKEKLSGLGGDPGADATAAYQELCRQRMATRPPDRPEGPHTSRISSVSSQF SDGPIPSPSARSSASSWSEEPVQSNMDISTGHMILSYMEDHLKNKNRLEKEWEALCAYQA EPNSSFVAQREENVPKNRSLAVLTYDHSRVLLKAENSHSHSDYINASPIMDHDPRNPAYI ATQGPLPATVADFWQMVWESGCVVIVMLTPLAENGVRQCYHYWPDEGSNLYHIYEVNLVS EHIWCEDFLVRSFYLKNLQTNETRTVTQFHFLSWYDRGVPSSSRSLLDFRRKVNKCYRGR SCPIIVHCSDGAGRSGTYVLIDMVLNKMAKGAKEIDIAATLEHLRDQRPGMVQTKEQFEF ALTAVAEEVNAILKALPQ
Nucleotide Sequence (with vector) for pF1KSDA0387 Download>pF1KSDA0387 6253 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT AGAACCATGGCTGTGGAATCTGAATATTCACTGCTGAGAACCGAAGCCAGCTTTCCTACT ATGAAGATGTTCTGTGTGAGCCACACCTTGCCCAGGGTGGAAGTGATGTTTGTTTCAGGT CCACAGACGAGGGAGAGGACGGAGCCAGTGGACCCTCGGTGGCAGTGTCTGGTGCAGATG TGGGCAGGCTGCCTGCTCGAGGAGGGCCTCTGCGGAGCGTCCGAGGCCTGTGTGAACGAT GGAGTGTTTGGAAGGTGCCAGAAGGTTCCGGCAATGGACTTTTACCGCTACGAGGTGTCG CCCGTGGCCCTGCAGCGCCTGCGCGTGGCGTTGCAGAAGCTTTCCGGCACAGGTTTCACG TGGCAGGATGACTATACTCAGTATGTGATGGACCAGGAACTTGCAGACCTCCCGAAAACC TACCTGAGGCGTCCTGAAGCATCCAGCCCAGCCAGGCCCTCAAAACACAGCGTTGGCAGC GAGAGGAGGTACAGTCGGGAGGGCGGTGCTGCCCTGGCCAACGCCCTCCGACGCCACCTG CCCTTCCTGGAGGCCCTGTCCCAGGCCCCAGCCTCAGACGTGCTCGCCAGGACCCATACG GCGCAGGACAGACCCCCCGCTGAGGGTGATGACCGCTTCTCCGAGAGCATCCTGACCTAT GTGGCCCACACGTCTGCGCTGACCTACCCTCCCGGGCCCCGGACCCAGCTCCACGAGGAC CTCCTGCCACGGACCCTCGGCCAGCTCCAGCCAGATGAGCTCAGCCCTAAGGTGGACAGT GGTGTGGACAGACACCATCTGATGGCGGCCCTCAGTGCCTATGCTGCCCAGAGGCCCCCA GCTCCCCCCGGGGAGGGCAGCCTGGAGCCACAGTACCTTCTGCGTGCACCCTCAAGAATG CCCAGGCCTTTGCTGGCACCAGCCGCCCCCCAGAAGTGGCCTTCACCTCTGGGAGATTCC GAAGACCCCTCTAGCACAGGCGATGGAGCACGGATTCATACCCTCCTGAAGGACCTGCAG AGGCAGCCGGCTGAGGTGAGGGGCCTGAGTGGCCTGGAGCTGGACGGCATGGCTGAGCTG ATGGCTGGCCTGATGCAAGGCGTGGACCATGGAGTAGCTCGAGGCAGCCCTGGGAGAGCG GCCCTGGGAGAGTCTGGAGAACAGGCGGATGGCCCCAAGGCCACCCTCCGTGGAGACAGC TTTCCAGATGACGGAGTGCAGGACGACGATGATAGACTTTACCAAGAGGTCCATCGTCTG AGTGCCACACTCGGGGGCCTCCTGCAGGACCACGGGTCTCGACTCTTACCTGGAGCCCTC CCCTTTGCAAGGCCCCTCGACATGGAGAGGAAGAAGTCCGAGCACCCTGAGTCTTCCCTG TCTTCAGAAGAGGAGACTGCCGGAGTGGAGAACGTCAAGAGCCAGACGTATTCCAAAGAT CTGCTGGGGCAGCAGCCGCATTCGGAGCCCGGGGCCGCTGCGTTTGGGGAGCTCCAAAAC CAGATGCCTGGGCCCTCGAAGGAGGAGCAGAGCCTTCCAGCGGGTGCTCAGGAGGCCCTC AGCGACGGCCTGCAATTGGAGGTCCAGCCTTCCGAGGAAGAGGCGCGGGGCTACATCGTG ACAGACAGAGACCCCCTGCGCCCCGAGGAAGGAAGGCGGCTGGTGGAGGACGTCGCCCGC CTCCTGCAGGTGCCCAGCAGCGCGTTCGCTGACGTGGAGGTTCTCGGACCAGCAGTGACC TTCAAAGTGAGCGCCAATGTCCAAAACGTGACCACTGAGGATGTGGAGAAGGCCACAGTT GACAACAAAGACAAACTGGAGGAAACCTCTGGACTGAAAATTCTTCAAACCGGAGTCGGG TCGAAAAGCAAACTCAAGTTCCTGCCTCCTCAGGCGGAGCAAGAAGACTCCACCAAGTTC ATCGCGCTCACCCTGGTCTCCCTCGCCTGCATCCTGGGCGTCCTCCTGGCCTCTGGCCTC ATCTACTGCCTCCGCCATAGCTCTCAGCACAGGCTGAAGGAGAAGCTCTCGGGACTAGGG GGCGACCCAGGTGCAGATGCCACTGCCGCCTACCAGGAGCTGTGCCGCCAGCGTATGGCC ACGCGGCCACCAGACCGACCTGAGGGCCCGCACACGTCACGCATCAGCAGCGTCTCATCC CAGTTCAGCGACGGGCCGATCCCCAGCCCCTCCGCACGCAGCAGCGCCTCATCCTGGTCC GAGGAGCCTGTGCAGTCCAACATGGACATCTCCACCGGCCACATGATCCTGTCCTACATG GAGGACCACCTGAAGAACAAGAACCGGCTGGAGAAGGAGTGGGAAGCGCTGTGCGCCTAC CAGGCGGAGCCCAACAGCTCGTTCGTGGCCCAGAGGGAGGAGAACGTGCCCAAGAACCGC TCCCTGGCTGTGCTGACCTATGACCACTCCCGGGTCCTGCTGAAGGCGGAGAACAGCCAC AGCCACTCAGACTACATCAACGCTAGCCCCATCATGGATCACGACCCGAGGAACCCCGCG TACATCGCCACCCAGGGACCGCTGCCCGCCACCGTGGCTGACTTTTGGCAGATGGTGTGG GAGAGCGGCTGCGTGGTGATCGTCATGCTGACACCCCTCGCGGAGAACGGCGTCCGGCAG TGCTACCACTACTGGCCGGATGAAGGCTCCAATCTCTACCACATCTATGAGGTGAACCTG GTCTCCGAGCACATCTGGTGTGAGGACTTCCTGGTGAGGAGCTTCTATCTGAAGAACCTG CAGACCAACGAGACGCGCACCGTGACGCAGTTCCACTTCCTGAGTTGGTATGACCGAGGA GTCCCTTCCTCCTCAAGGTCCCTCCTGGACTTCCGCAGAAAAGTAAACAAGTGCTACAGG GGCCGTTCTTGTCCAATAATTGTTCATTGCAGTGACGGTGCAGGCCGGAGCGGCACCTAC GTCCTGATCGACATGGTTCTCAACAAGATGGCCAAAGGTGCTAAAGAGATTGATATCGCA GCGACCCTGGAGCACTTGAGGGACCAGAGACCCGGCATGGTCCAGACGAAGGAGCAGTTT GAGTTCGCGCTGACAGCCGTGGCTGAGGAGGTGAACGCCATCCTCAAGGCCCTTCCCCAG TACGTAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGG CATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCAC CGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTT GCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTA TCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGT CCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTT CTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCT TCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAAC TGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAG ACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCC GCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGAT GCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTG TCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACG GGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTA TTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTA TCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTC GACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTC GATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGG CTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTG CCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGT GTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGC GGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGC ATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGCGAAAT GACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCC ACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGG AACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCAT CACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAG GCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGA TACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGG TATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTT CAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACAC GACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGC GGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTT GGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCC GGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGC AGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGG AACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAG ATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTG AAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCT GGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGG TGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGT GCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGAT AAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTG ATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGT AGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGAT GGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAA GGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCT GAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTG GCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGAC GGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATA TGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}