


-
SpecieshumanProduct IDFXC00676Cloning SiteSgfI-PmeISymbolWDR47DescriptionWD repeat domain 47, transcript variant 3
 Length: 2757 bp
Length: 2757 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 919 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
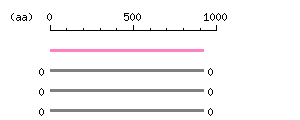
Entry Exp ID% symbol CCDS44187.1 0 100.0 WDR47 CCDS30787.1 0 99.9 WDR47 CCDS44186.1 0 99.1 WDR47
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition HMMPfam IPR019781 606 632 PF00400 WD40 repeat IPR019781 658 687 PF00400 WD40 repeat IPR019781 746 782 PF00400 WD40 repeat IPR019781 794 828 PF00400 WD40 repeat IPR019781 835 868 PF00400 WD40 repeat IPR019781 881 915 PF00400 WD40 repeat HMMSmart IPR006594 10 42 SM00667 LisH dimerisation motif IPR006595 45 102 SM00668 CTLH IPR001680 596 634 SM00320 WD40 repeat IPR001680 647 689 SM00320 WD40 repeat IPR001680 697 741 SM00320 WD40 repeat IPR001680 744 782 SM00320 WD40 repeat IPR001680 789 828 SM00320 WD40 repeat IPR001680 831 870 SM00320 WD40 repeat IPR001680 877 916 SM00320 WD40 repeat ProfileScan IPR006594 10 42 PS50896 LisH dimerisation motif IPR006595 45 102 PS50897 CTLH IPR019782 657 687 PS50082 WD40 repeat 2 IPR017986 657 919 PS50294 WD40-repeat-containing domain IPR019782 751 791 PS50082 WD40 repeat 2 IPR019782 796 837 PS50082 WD40 repeat 2 IPR019782 838 872 PS50082 WD40 repeat 2 IPR019782 884 919 PS50082 WD40 repeat 2
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_001136023 919 615734 100.0 100.0 XP_016856186 919 615734 100.0 100.0 NP_055784 920 615734 99.9 100.0 XP_011539330 921 615734 99.8 100.0 XP_016856185 926 615734 99.2 100.0 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KSDA0893 Download>KIAA0893 2757 bp ATGACGGCTGAAGAAACAGTGAATGTAAAAGAGGTTGAAATCATTAAGCTAATTTTGGAC TTCCTGAATTCAAAGAAGCTTCACATTAGTATGCTGGCCCTGGAGAAGGAAAGTGGAGTC ATAAATGGCCTGTTTTCAGATGATATGCTTTTCCTGAGGCAGCTAATACTTGATGGTCAA TGGGATGAAGTTCTTCAGTTCATTCAGCCTCTAGAATGTATGGAAAAATTTGACAAAAAA AGGTTTCGTTATATTATCCTGAAGCAGAAGTTTTTAGAAGCTTTATGTGTTAACAACGCG ATGTCAGCAGAAGATGAGCCCCAGCATCTGGAATTTACCATGCAAGAAGCTGTGCAATGT TTACATGCTCTAGAAGAATACTGTCCTTCTAAAGATGACTATAGTAAGCTCTGTTTGCTT TTGACTTTGCCTCGTCTGACCAATCATGCCGAGTTTAAGGACTGGAATCCCAGCACCGCA CGAGTTCACTGTTTTGAAGAGGCTTGTGTCATGGTTGCAGAATTCATCCCTGCTGATAGG AAGCTAAGTGAAGCTGGTTTTAAGGCTAGTAACAATCGTTTATTTCAGCTTGTAATGAAA GGCCTGCTTTATGAATGCTGTGTAGAATTTTGTCAGAGTAAAGCAACTGGAGAAGAAATT ACAGAAAGCGAAGTGCTTCTTGGCATCGACCTCTTATGTGGTAATGGTTGTGATGATTTG GATCTGAGTTTACTGTCATGGCTTCAGAATCTTCCATCTTCTGTCTTCTCTTGTGCTTTT GAACAGAAAATGCTTAATATTCATGTTGACAAACTTCTGAAACCTACAAAAGCTGCATAT GCTGATCTTTTGACTCCTCTTATCAGCAAACTCTCTCCCTATCCATCATCCCCAATGAGA AGACCTCAATCAGCTGATGCCTATATGACCCGCTCTCTGAATCCTGCTTTAGATGGCCTC ACCTGTGGACTAACCAGTCATGATAAGAGAATTTCAGACCTTGGAAACAAAACTTCTCCA ATGTCACACTCCTTTGCTAACTTCCATTATCCAGGGGTACAAAACCTCAGTAGAAGTCTC ATGCTTGAGAATACAGAATGTCACAGTATTTACGAAGAATCCCCTGAGCGTGATACACCT GTTGATGCACAGAGGCCTATCGGCAGTGAAATCTTGGGCCAGAGTTCAGTTTCAGAAAAA GAGCCTGCAAATGGAGCACAGAATCCAGGACCAGCTAAACAAGAAAAAAATGAGCTTCGA GATTCAACAGAACAATTTCAAGAATATTATAGGCAAAGATTACGCTATCAACAGCATTTA GAACAGAAGGAGCAACAGCGGCAGATATACCAACAGATGTTGCTTGAAGGAGGCGTGAAT CAGGAGGATGGTCCTGATCAGCAGCAGAATCTTACTGAACAGTTCCTTAATAGGTCCATT CAAAAGCTTGGTGAATTAAATATTGGAATGGATGGCCTTGGTAATGAGGTATCAGCACTC AACCAGCAATGTAATGGGAGCAAAGGCAATGGATCTAATGGTTCTTCTGTGACTAGTTTT ACTACACCACCCCAAGACTCTAGTCAGAGATTAACACATGATGCTTCAAATATTCATACA AGCACTCCTCGTAATCCTGGATCAACAAATCACATACCTTTTCTGGAGGAATCACCTTGT GGAAGCCAAATCTCTTCAGAACATTCGGTCATTAAGCCACCTCTTGGAGATTCTCCAGGG AGTCTTTCAAGGTCGAAAGGGGAAGAGGATGACAAATCAAAAAAGCAGTTTGTTTGTATT AATATCCTAGAAGACACACAAGCTGTTAGAGCAGTGGCTTTTCATCCAGCTGGAGGTTTA TATGCTGTTGGTTCAAATTCAAAAACTCTGAGAGTATGTGCCTATCCAGATGTAATTGAT CCAAGTGCACATGAGACTCCTAAGCAGCCGGTGGTACGTTTTAAAAGGAATAAACATCAT AAAGGATCCATTTACTGTGTGGCCTGGAGTCCTTGTGGGCAGTTATTAGCAACAGGATCA AATGACAAATACGTCAAAGTGCTGCCCTTCAATGCAGAGACTTGTAACGCAACAGGACCA GATCTGGAATTTAGTATGCATGATGGAACAATTAGAGACTTGGCATTTATGGAAGGCCCA GAAAGCGGAGGAGCTATTTTAATAAGTGCTGGAGCAGGGGATTGTAACATTTATACAACC GATTGTCAAAGAGGTCAGGGCCTCCATGCTTTGAGTGGACATACTGGGCATATTTTAGCA CTTTATACCTGGAGTGGCTGGATGATTGCATCTGGTTCCCAAGATAAGACTGTTAGATTT TGGGATCTTCGAGTACCAAGTTGTGTTCGTGTTGTTGGCACAACATTTCATGGAACTGGC AGTGCAGTGGCATCTGTAGCTGTAGATCCCAGTGGTCGTCTCTTAGCCACAGGTCAAGAA GATTCTAGCTGCATGTTGTATGACATAAGAGGAGGAAGAATGGTACAAAGTTATCATCCT CATTCCAGTGATGTTCGCTCTGTTCGATTCTCCCCTGGAGCTCACTACTTGCTAACAGGC TCTTATGATATGAAAATAAAGGTGACAGACCTACAAGGGGACCTCACCAAGCAGCTTCCT ATCATGGTGGTGGGGGAGCACAAGGACAAAGTGATTCAGTGCAGATGGCACACCCAGGAT CTTTCCTTCCTGTCATCCTCTGCAGATAGAACTGTCACCCTCTGGACTTACAATGGG
Cloned ORF protein sequence for pF1KSDA0893 Download>KIAA0893 919 aa MTAEETVNVKEVEIIKLILDFLNSKKLHISMLALEKESGVINGLFSDDMLFLRQLILDGQ WDEVLQFIQPLECMEKFDKKRFRYIILKQKFLEALCVNNAMSAEDEPQHLEFTMQEAVQC LHALEEYCPSKDDYSKLCLLLTLPRLTNHAEFKDWNPSTARVHCFEEACVMVAEFIPADR KLSEAGFKASNNRLFQLVMKGLLYECCVEFCQSKATGEEITESEVLLGIDLLCGNGCDDL DLSLLSWLQNLPSSVFSCAFEQKMLNIHVDKLLKPTKAAYADLLTPLISKLSPYPSSPMR RPQSADAYMTRSLNPALDGLTCGLTSHDKRISDLGNKTSPMSHSFANFHYPGVQNLSRSL MLENTECHSIYEESPERDTPVDAQRPIGSEILGQSSVSEKEPANGAQNPGPAKQEKNELR DSTEQFQEYYRQRLRYQQHLEQKEQQRQIYQQMLLEGGVNQEDGPDQQQNLTEQFLNRSI QKLGELNIGMDGLGNEVSALNQQCNGSKGNGSNGSSVTSFTTPPQDSSQRLTHDASNIHT STPRNPGSTNHIPFLEESPCGSQISSEHSVIKPPLGDSPGSLSRSKGEEDDKSKKQFVCI NILEDTQAVRAVAFHPAGGLYAVGSNSKTLRVCAYPDVIDPSAHETPKQPVVRFKRNKHH KGSIYCVAWSPCGQLLATGSNDKYVKVLPFNAETCNATGPDLEFSMHDGTIRDLAFMEGP ESGGAILISAGAGDCNIYTTDCQRGQGLHALSGHTGHILALYTWSGWMIASGSQDKTVRF WDLRVPSCVRVVGTTFHGTGSAVASVAVDPSGRLLATGQEDSSCMLYDIRGGRMVQSYHP HSSDVRSVRFSPGAHYLLTGSYDMKIKVTDLQGDLTKQLPIMVVGEHKDKVIQCRWHTQD LSFLSSSADRTVTLWTYNG
Nucleotide Sequence (with vector) for pF1KSDA0893 Download>pF1KSDA0893 5896 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT AGAACCATGACGGCTGAAGAAACAGTGAATGTAAAAGAGGTTGAAATCATTAAGCTAATT TTGGACTTCCTGAATTCAAAGAAGCTTCACATTAGTATGCTGGCCCTGGAGAAGGAAAGT GGAGTCATAAATGGCCTGTTTTCAGATGATATGCTTTTCCTGAGGCAGCTAATACTTGAT GGTCAATGGGATGAAGTTCTTCAGTTCATTCAGCCTCTAGAATGTATGGAAAAATTTGAC AAAAAAAGGTTTCGTTATATTATCCTGAAGCAGAAGTTTTTAGAAGCTTTATGTGTTAAC AACGCGATGTCAGCAGAAGATGAGCCCCAGCATCTGGAATTTACCATGCAAGAAGCTGTG CAATGTTTACATGCTCTAGAAGAATACTGTCCTTCTAAAGATGACTATAGTAAGCTCTGT TTGCTTTTGACTTTGCCTCGTCTGACCAATCATGCCGAGTTTAAGGACTGGAATCCCAGC ACCGCACGAGTTCACTGTTTTGAAGAGGCTTGTGTCATGGTTGCAGAATTCATCCCTGCT GATAGGAAGCTAAGTGAAGCTGGTTTTAAGGCTAGTAACAATCGTTTATTTCAGCTTGTA ATGAAAGGCCTGCTTTATGAATGCTGTGTAGAATTTTGTCAGAGTAAAGCAACTGGAGAA GAAATTACAGAAAGCGAAGTGCTTCTTGGCATCGACCTCTTATGTGGTAATGGTTGTGAT GATTTGGATCTGAGTTTACTGTCATGGCTTCAGAATCTTCCATCTTCTGTCTTCTCTTGT GCTTTTGAACAGAAAATGCTTAATATTCATGTTGACAAACTTCTGAAACCTACAAAAGCT GCATATGCTGATCTTTTGACTCCTCTTATCAGCAAACTCTCTCCCTATCCATCATCCCCA ATGAGAAGACCTCAATCAGCTGATGCCTATATGACCCGCTCTCTGAATCCTGCTTTAGAT GGCCTCACCTGTGGACTAACCAGTCATGATAAGAGAATTTCAGACCTTGGAAACAAAACT TCTCCAATGTCACACTCCTTTGCTAACTTCCATTATCCAGGGGTACAAAACCTCAGTAGA AGTCTCATGCTTGAGAATACAGAATGTCACAGTATTTACGAAGAATCCCCTGAGCGTGAT ACACCTGTTGATGCACAGAGGCCTATCGGCAGTGAAATCTTGGGCCAGAGTTCAGTTTCA GAAAAAGAGCCTGCAAATGGAGCACAGAATCCAGGACCAGCTAAACAAGAAAAAAATGAG CTTCGAGATTCAACAGAACAATTTCAAGAATATTATAGGCAAAGATTACGCTATCAACAG CATTTAGAACAGAAGGAGCAACAGCGGCAGATATACCAACAGATGTTGCTTGAAGGAGGC GTGAATCAGGAGGATGGTCCTGATCAGCAGCAGAATCTTACTGAACAGTTCCTTAATAGG TCCATTCAAAAGCTTGGTGAATTAAATATTGGAATGGATGGCCTTGGTAATGAGGTATCA GCACTCAACCAGCAATGTAATGGGAGCAAAGGCAATGGATCTAATGGTTCTTCTGTGACT AGTTTTACTACACCACCCCAAGACTCTAGTCAGAGATTAACACATGATGCTTCAAATATT CATACAAGCACTCCTCGTAATCCTGGATCAACAAATCACATACCTTTTCTGGAGGAATCA CCTTGTGGAAGCCAAATCTCTTCAGAACATTCGGTCATTAAGCCACCTCTTGGAGATTCT CCAGGGAGTCTTTCAAGGTCGAAAGGGGAAGAGGATGACAAATCAAAAAAGCAGTTTGTT TGTATTAATATCCTAGAAGACACACAAGCTGTTAGAGCAGTGGCTTTTCATCCAGCTGGA GGTTTATATGCTGTTGGTTCAAATTCAAAAACTCTGAGAGTATGTGCCTATCCAGATGTA ATTGATCCAAGTGCACATGAGACTCCTAAGCAGCCGGTGGTACGTTTTAAAAGGAATAAA CATCATAAAGGATCCATTTACTGTGTGGCCTGGAGTCCTTGTGGGCAGTTATTAGCAACA GGATCAAATGACAAATACGTCAAAGTGCTGCCCTTCAATGCAGAGACTTGTAACGCAACA GGACCAGATCTGGAATTTAGTATGCATGATGGAACAATTAGAGACTTGGCATTTATGGAA GGCCCAGAAAGCGGAGGAGCTATTTTAATAAGTGCTGGAGCAGGGGATTGTAACATTTAT ACAACCGATTGTCAAAGAGGTCAGGGCCTCCATGCTTTGAGTGGACATACTGGGCATATT TTAGCACTTTATACCTGGAGTGGCTGGATGATTGCATCTGGTTCCCAAGATAAGACTGTT AGATTTTGGGATCTTCGAGTACCAAGTTGTGTTCGTGTTGTTGGCACAACATTTCATGGA ACTGGCAGTGCAGTGGCATCTGTAGCTGTAGATCCCAGTGGTCGTCTCTTAGCCACAGGT CAAGAAGATTCTAGCTGCATGTTGTATGACATAAGAGGAGGAAGAATGGTACAAAGTTAT CATCCTCATTCCAGTGATGTTCGCTCTGTTCGATTCTCCCCTGGAGCTCACTACTTGCTA ACAGGCTCTTATGATATGAAAATAAAGGTGACAGACCTACAAGGGGACCTCACCAAGCAG CTTCCTATCATGGTGGTGGGGGAGCACAAGGACAAAGTGATTCAGTGCAGATGGCACACC CAGGATCTTTCCTTCCTGTCATCCTCTGCAGATAGAACTGTCACCCTCTGGACTTACAAT GGGTACGTAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGC AGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGC CACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTT TTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAG CTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCT TGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGC TTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGA GCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTA AACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAA GAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCG GCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCT GATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGAC CTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACG ACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTG CTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAA GTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCA TTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTT GTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCC AGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGC TTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTG GGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTT GGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAG CGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGCGA AATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTA TCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCC AGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAG CATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATAC CAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACC GGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGT AGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCC GTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGA CACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTA GGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTA TTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGA TCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACG CGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAG TGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACC TAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATG GTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCC TCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTC GGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGC GGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGA GATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGC CTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGC AGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCC GATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACG AAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCT CCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGG GTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCT GACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAA ATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}