Nucleotide Sequence (with vector) for pF1KSDA0920
Download
>pF1KSDA0920 6448 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT
AGAACCATGGCAGAGGCGGAATTGCACAAGGAAAGGCTGCAAGCCATAGCAGAAAAAAGA
AAGAGGCAGACTGAAATAGAAGGCAAGCGACAACAGCTTGACGAGCAGATACTTCTGCTG
CAGCATTCCAAGTCCAAAGTGCTTCGGGAGAAATGGCTGCTGCAGGGCATACCCGCTGGA
ACTGCCGAAGAGGAGGAAGCCAGGAGGCGGCAGTCTGAAGAGGATGAGTTCAGAGTCAAG
CAACTTGAAGATAACATTCAGAGGCTGGAGCAAGAAATACAAACGCTAGAAAGTGAAGAG
TCCCAGATATCTGCCAAAGAGCAAATCATCCTAGAGAAACTGAAGGAAACAGAAAAATCC
TTCAAGGACTTTCAGAAGGGTTTCTCCAGTACGGATGGAGATGCAGTAAATTACATTTCC
TCCCAGCTTCCCGACCTGCCAATCCTCTGTTCACGAACAGCAGAACCATCACCTGGGCAG
GACGGGACCAGCAGAGCGGCTGGAGTCGGGTGGGAGAATGTGCTGCTAAAGGAAGGTGAG
TCAGCCTCGAACGCCACAGAAACATCCGGCCCAGACATGACTATCAAGAAGCCTCCCCAG
CTTTCTGAGGATGATATCTGGCTAAAAAGCGAGGGAGACAACTATAGTGCCACCCTCCTG
GAGCCTGCTGCCAGCTCTCTTTCCCCAGATCACAAAAACATGGAAATTGAGGTGTCTGTT
GCAGAATGTAAAAGTGTTCCTGGAATCACCTCTACCCCACATCCCATGGACCATCCCTCC
GCTTTCTATTCACCCCCGCATAATGGCCTCCTTACTGATCACCACGAATCCCTGGATAAT
GATGTTGCCAGAGAGATCCGCTATCTAGATGAGGTGCTAGAGGCCAACTGCTGTGATTCT
GCTGTGGATGGAACGTACAATGGAACATCCTCCCCAGAGCCTGGTGCAGTGGTTCTGGTG
GGCGGCCTAAGCCCCCCTGTCCACGAGGCGACCCAGCCAGAACCCACTGAAAGAACAGCT
AGCCGGCAGGCACCTCCTCACATCGAGCTCAGTAATAGCAGCCCTGACCCCATGGCAGAG
GCAGAAAGAACAAATGGCCATTCCCCCAGCCAGCCTAGAGATGCGCTGGGGGACAGCCTG
CAGGTGCCTGTCAGCCCCAGCTCCACAACCAGCTCACGGTGTTCTTCCCGAGATGGAGAG
TTCACTCTCACCACACTGAAAAAGGAGGCCAAGTTTGAGCTGCGTGCCTTCCATGAGGAC
AAGAAGCCCTCCAAGCTCTTTGAGGATGACGAGCATGAGAAAGAACAATACTGCATTAGA
AAAGTGAGGCCTTCAGAGGAGATGCTGGAGCTGGAAAAGGAGAGGAGAGAGCTCATCCGC
AGCCAGGCCGTCAAGAAGAATCCTGGCATTGCAGCAAAATGGTGGAATCCCCCGCAGGAA
AAAACCATCGAGGAGCAGCTGGACGAGGAACATCTGGAGTCGCACAAAAAGTACAAGGAG
CGCAAAGAGAGAAGGGCACAGCAGGAACAGTTGCTGCTGCAGAAGCAGTTACAGCAGCAG
CAGCAGCAGCCCCCATCGCAGCTCTGCACAGCCCCTGCCTCTTCTCATGAACGCGCAAGC
ATGATTGACAAAGCAAAGGAGGACATTGTCACAGAGCAGATAGATTTCTCTGCTGCTCGC
AAACAATTTCAGCTGATGGAGAATTCCAGGCAAGCGGTGGCCAAGGGCCAGAGTACACCC
AGGCTGTTCTCCATCAAGCCTTTCTACAGGCCTCTGGGGTCAGTCAACTCAGACAAGCCA
CTGACTAATCCGAGACCACCTTCTGTCGGGGGACCTCCAGAAGACAGTGGTGCCTCAGCC
GCCAAGGGACAGAAATCCCCCGGTGCCCTGGAGACCCCATCGGCAGCAGGAAGCCAGGGC
AACACAGCCTCTCAGGGGAAGGAAGGGCCCTACAGCGAGCCTTCTAAACGTGGGCCCTTA
TCTAAACTGTGGGCTGAGGATGGAGAATTTACGAGCGCCCGGGCTGTCCTCACTGTGGTC
AAGGATGATGACCATGGGATTTTGGATCAGTTCTCAAGATCTGTCAATGTCTCCTTGACC
CAAGAGGAGCTTGACTCTGGTCTGGACGAATTGTCGGTGAGGTCTCAGGATACCACAGTC
CTGGAGACCCTATCCAATGATTTCAGCATGGACAACATCAGTGACAGCGGGGCATCCAAT
GAGACAACCAATGCCCTCCAGGAAAATTCACTGGCTGATTTTTCTCTGCCCCAGACACCA
CAAACTGACAACCCCTCAGAGGGCCGAGGAGAAGGCGTCTCCAAGTCATTTAGTGATCAT
GGTTTCTATTCCCCTTCCTCCACGCTGGGGGACTCTCCGTTGGTTGATGACCCCTTGGAG
TATCAGGCTGGCCTCCTGGTGCAGAATGCCATTCAACAAGCCATAGCCGAGCAGGTGGAT
AAAGCTGTGTCCAAAACCAGCAGGGATGGAGCAGAGCAACAGGGACCTGAAGCGACTGTA
GAGGAAGCTGAAGCTGCGGCTTTCGGCTCAGAAAAGCCTCAGAGCATGTTTGAGCCACCT
CAGGTGTCTTCTCCTGTTCAAGAGAAAAGGGATGTATTACCAAAGATTCTGCCTGCTGAA
GACAGGGCGCTCAGGGAAAGGGGGCCCCCCCAGCCACTGCCAGCTGTGCAGCCCAGTGGC
CCGATTAACATGGAGGAGACCAGGCCCGAAGGAAGCTATTTCAGCAAGTACTCGGAGGCA
GCTGAGCTGAGAAGCACAGCCTCCCTCCTGGCCACTCAAGAATCTGACGTGATGGTTGGG
CCTTTCAAGCTGAGGTCCAGGAAACAGCGGACTTTGTCCATGATTGAGGAAGAGATCCGA
GCAGCTCAGGAAAGGGAAGAGGAGCTGAAGAGGCAGAGACAAGTCTTGCAGAGTACGCAG
AGCCCCAGGACAAAGAATGCCCCATCACTGCCCTCCAGAACATGCTACAAAACTGCTCCA
GGGAAAATAGAGAAAGTCAAACCTCCTCCATCCCCCACCACTGAAGGCCCCAGCCTGCAG
CCTGACTTAGCCCCTGAAGAGGCTGCCGGAACCCAGCGGCCCAAGAATCTGATGCAGACC
CTCATGGAAGACTATGAGACACACAAATCTAAAAGGCGCGAGAGAATGGATGATAGTAGT
TACACTTCTAAGTTACTGTCTTGCAAGGTGACTTCCGAGGTCCTCGAGGCCACACGGGTT
AATCGAAGAAAGAGCGCACTGGCTTTGCGCTGGGAAGCAGGGATCTATGCCAACCAGGAG
GAAGAAGACAACGAATACGTAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTA
GAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGA
GTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGT
CTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAAC
CGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCT
TGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTT
CTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTT
GCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAG
CCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCA
AGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCAC
GCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACA
ATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTT
GTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCG
TGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGA
AGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCT
CCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCG
GCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATG
GAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCC
GAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCAT
GGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGAC
TGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATT
GCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCT
CCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTC
TGGGGTTCGCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCG
GTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGC
CAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGC
CCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGA
CTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACC
CTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCAT
AGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTG
CACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCC
AACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGA
GCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACT
AGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTT
GGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAG
CAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGG
TCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAA
AGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCC
TTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATG
TGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTG
CGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGA
ACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCT
CGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGA
GATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAAT
TTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAA
CGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCA
TCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTC
GGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCA
ACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCA
GAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCT
AAATACATTCAAATATGTATCCGCTCAT



 Length: 3309 bp
Length: 3309 bp Restriction map B
Restriction map B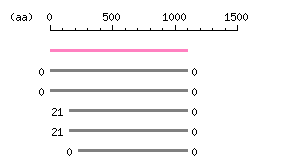

 more Linker info
more Linker info
{kind=link}