


-
SpecieshumanProduct IDFXC00686Cloning SiteSgfI-PmeISymbolSEZ6LDescriptionseizure related 6 homolog (mouse)-like, transcript variant 5
 Length: 2847 bp
Length: 2847 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 949 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
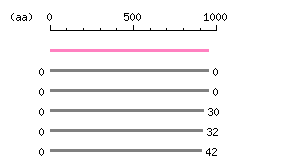
Entry Exp ID% symbol CCDS54511.1 1.2e-212 100.0 SEZ6L CCDS54510.1 1.6e-199 94.5 SEZ6L CCDS74837.1 2.6e-182 93.2 SEZ6L CCDS54509.1 2.6e-182 93.4 SEZ6L CCDS54508.1 2.6e-182 92.4 SEZ6L
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition HMMPfam IPR000859 281 386 PF00431 CUB IPR000436 393 448 PF00084 Sushi/SCR/CCP IPR000859 452 559 PF00431 CUB IPR000436 567 624 PF00084 Sushi/SCR/CCP IPR000859 628 722 PF00431 CUB IPR000436 745 800 PF00084 Sushi/SCR/CCP IPR000436 809 866 PF00084 Sushi/SCR/CCP HMMSmart IPR000859 281 389 SM00042 CUB IPR000436 393 448 SM00032 Sushi/SCR/CCP IPR000859 452 562 SM00042 CUB IPR000436 567 624 SM00032 Sushi/SCR/CCP IPR000859 628 739 SM00042 CUB IPR000436 745 800 SM00032 Sushi/SCR/CCP IPR000436 809 866 SM00032 Sushi/SCR/CCP ProfileScan IPR000859 281 389 PS01180 CUB IPR000436 391 450 PS50923 Sushi/SCR/CCP IPR000859 452 562 PS01180 CUB IPR000436 565 626 PS50923 Sushi/SCR/CCP IPR000859 628 739 PS01180 CUB IPR000436 743 802 PS50923 Sushi/SCR/CCP IPR000436 807 868 PS50923 Sushi/SCR/CCP
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 6 PPAAGLRGISLFLALLLGSPAAA 28 SECONDARY 23 2 882 MALAIFIPVLIISLLLGGAYIYI 904 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_001171705 949 607021 100.0 100.0 NP_001171706 948 607021 94.5 100.0 XP_011528341 957 607021 93.5 100.0 XP_016884189 958 607021 99.0 100.0 XP_016884188 959 607021 99.0 100.0 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KSDA0927 Download>KIAA0927 2847 bp ATGCCCGCGGCCCGGCCGCCCGCCGCGGGACTCCGCGGGATCTCGCTGTTCCTCGCTCTG CTCCTGGGGAGCCCGGCGGCAGCGCTGGAGCGAGATGCTCTTCCCGAGGGAGATGCTAGC CCTTTGGGTCCTTACCTCCTGCCCTCAGGAGCCCCGGAGAGAGGCAGTCCTGGCAAAGAG CACCCTGAAGAGAGAGTGGTAACAGCGCCCCCCAGTTCCTCACAGTCGGCGGAAGTGCTG GGCGAGCTGGTGCTGGATGGGACCGCACCCTCTGCACATCACGACATCCCAGCCCTGTCA CCGCTGCTTCCAGAGGAGGCCCGCCCCAAGCACGCCTTGCCCCCCAAGAAGAAACTGCCT TCGCTCAAGCAGGTGAACTCTGCCAGGAAGCAGCTGAGGCCCAAGGCCACCTCCGCAGCC ACTGTCCAAAGGGCAGGGTCCCAGCCAGCGTCCCAGGGCCTAGATCTCCTCTCCTCCTCC ACGGAGAAGCCTGGCCCACCGGGGGACCCGGACCCCATCGTGGCCTCCGAGGAGGCATCA GAAGTGCCCCTTTGGCTGGATCGAAAGGAGAGTGCGGTCCCTACAACACCCGCACCCCTG CAAATCTCCCCCTTCACTTCGCAGCCCTATGTGGCCCACACACTCCCCCAGAGGCCAGAA CCCGGGGAGCCTGGGCCTGACATGGCCCAGGAGGCCCCCCAGGAGGACACCAGCCCCATG GCCCTGATGGACAAAGGTGAGAATGAGCTGACTGGGTCAGCCTCAGAGGAGAGCCAGGAG ACCACTACCTCCACCATTATCACCACCACGGTCATCACCACCGAGCAAGCACCAGCTCTC TGCAGTGTGAGCTTCTCCAATCCTGAGGGGTACATTGACTCCAGCGACTACCCACTGCTG CCCCTCAACAACTTTCTGGAGTGCACATACAACGTGACAGTCTACACTGGCTATGGGGTG GAGCTCCAGGTGAAGAGTGTGAACCTGTCCGATGGGGAACTGCTCTCCATCCGCGGGGTG GACGGCCCTACCCTGACCGTCCTGGCCAACCAGACACTCCTGGTGGAGGGGCAGGTAATC CGAAGCCCCACCAACACCATCTCCGTCTACTTCCGGACCTTCCAGGACGACGGCCTTGGG ACCTTCCAGCTTCACTACCAGGCCTTCATGCTGAGCTGCAACTTTCCCCGCCGGCCTGAC TCTGGGGATGTCACGGTGATGGACCTGCACTCAGGTGGGGTGGCCCACTTTCACTGCCAC CTGGGCTATGAGCTCCAGGGCGCTAAGATGCTGACATGCATCAATGCCTCCAAGCCGCAC TGGAGCAGCCAGGAGCCCATCTGCTCAGCTCCTTGTGGAGGGGCAGTGCACAATGCCACC ATCGGCCGCGTCCTCTCCCCAAGTTACCCTGAAAACACCAATGGGAGCCAATTCTGCATC TGGACGATTGAAGCTCCAGAGGGCCAGAAGCTGCACCTGCACTTTGAGAGGCTGTTGCTG CATGACAAGGACAGGATGACGGTTCACAGCGGGCAGACCAACAAGTCAGCTCTTCTCTAC GACTCCCTTCAAACCGAGAGTGTCCCTTTTGAGGGCCTGCTGAGCGAAGGCAACACCATC CGCATCGAGTTCACGTCCGACCAGGCCCGGGCGGCCTCCACCTTCAACATCCGATTTGAA GCGTTTGAGAAAGGCCACTGCTATGAGCCCTACATCCAGAATGGGAACTTCACTACATCC GACCCGACCTATAACATTGGGACTATAGTGGAGTTCACCTGCGACCCCGGCCACTCCCTG GAGCAGGGCCCGGCCATCATCGAATGCATCAATGTGCGGGACCCATACTGGAATGACACA GAGCCCCTGTGCAGAGCCATGTGTGGTGGGGAGCTCTCTGCTGTGGCTGGGGTGGTATTG TCCCCAAACTGGCCCGAGCCCTACGTGGAAGGTGAAGATTGTATCTGGAAGATCCACGTG GGAGAAGAGAAACGGATCTTCTTAGATATCCAGTTCCTGAATCTGAGCAACAGTGACATC TTGACCATCTACGATGGCGACGAGGTCATGCCCCACATCTTGGGGCAGTACCTTGGGAAC AGTGGCCCCCAGAAACTGTACTCCTCCACGCCAGACTTAACCATCCAGTTCCATTCGGAC CCTGCTGGCCTCATCTTTGGAAAGGGCCAGGGATTTATCATGAACTACATAGAGGTATCA AGGAATGACTCCTGCTCGGATTTACCCGAGATCCAGAATGGCTGGAAAACCACTTCTCAC ACGGAGTTGGTGCGGGGAGCCAGAATCACCTACCAGTGTGACCCCGGCTATGACATCGTG GGGAGTGACACCCTCACCTGCCAGTGGGACCTCAGCTGGAGCAGCGACCCCCCATTTTGT GAGAAAACGGAGGAGTCCCTGGCATGTGACAACCCAGGGCTGCCTGAAAATGGATACCAA ATCCTGTACAAGCGACTCTACCTGCCAGGAGAGTCCCTCACCTTCATGTGCTACGAAGGC TTTGAGCTCATGGGTGAAGTGACCATCCGCTGCATCCTGGGACAGCCATCCCACTGGAAC GGGCCCCTGCCCGTGTGTAAAGTAGCAGAAGCGGCAGCAGAGACGTCGCTGGAAGGGGGG AACATGGCCCTGGCTATCTTCATCCCGGTCCTCATCATCTCCTTACTGCTGGGAGGAGCC TACATTTACATCACAAGATGTCGCTACTATTCCAACCTCCGCCTGCCTCTGATGTACTCC CACCCCTACAGCCAGATCACCGTGGAAACCGAGTTTGACAACCCCATTTACGAGACAGGG GAAACCAGAGAGTATGAGGTTTCTATC
Cloned ORF protein sequence for pF1KSDA0927 Download>KIAA0927 949 aa MPAARPPAAGLRGISLFLALLLGSPAAALERDALPEGDASPLGPYLLPSGAPERGSPGKE HPEERVVTAPPSSSQSAEVLGELVLDGTAPSAHHDIPALSPLLPEEARPKHALPPKKKLP SLKQVNSARKQLRPKATSAATVQRAGSQPASQGLDLLSSSTEKPGPPGDPDPIVASEEAS EVPLWLDRKESAVPTTPAPLQISPFTSQPYVAHTLPQRPEPGEPGPDMAQEAPQEDTSPM ALMDKGENELTGSASEESQETTTSTIITTTVITTEQAPALCSVSFSNPEGYIDSSDYPLL PLNNFLECTYNVTVYTGYGVELQVKSVNLSDGELLSIRGVDGPTLTVLANQTLLVEGQVI RSPTNTISVYFRTFQDDGLGTFQLHYQAFMLSCNFPRRPDSGDVTVMDLHSGGVAHFHCH LGYELQGAKMLTCINASKPHWSSQEPICSAPCGGAVHNATIGRVLSPSYPENTNGSQFCI WTIEAPEGQKLHLHFERLLLHDKDRMTVHSGQTNKSALLYDSLQTESVPFEGLLSEGNTI RIEFTSDQARAASTFNIRFEAFEKGHCYEPYIQNGNFTTSDPTYNIGTIVEFTCDPGHSL EQGPAIIECINVRDPYWNDTEPLCRAMCGGELSAVAGVVLSPNWPEPYVEGEDCIWKIHV GEEKRIFLDIQFLNLSNSDILTIYDGDEVMPHILGQYLGNSGPQKLYSSTPDLTIQFHSD PAGLIFGKGQGFIMNYIEVSRNDSCSDLPEIQNGWKTTSHTELVRGARITYQCDPGYDIV GSDTLTCQWDLSWSSDPPFCEKTEESLACDNPGLPENGYQILYKRLYLPGESLTFMCYEG FELMGEVTIRCILGQPSHWNGPLPVCKVAEAAAETSLEGGNMALAIFIPVLIISLLLGGA YIYITRCRYYSNLRLPLMYSHPYSQITVETEFDNPIYETGETREYEVSI
Nucleotide Sequence (with vector) for pF1KSDA0927 Download>pF1KSDA0927 5986 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT AGAACCATGCCCGCGGCCCGGCCGCCCGCCGCGGGACTCCGCGGGATCTCGCTGTTCCTC GCTCTGCTCCTGGGGAGCCCGGCGGCAGCGCTGGAGCGAGATGCTCTTCCCGAGGGAGAT GCTAGCCCTTTGGGTCCTTACCTCCTGCCCTCAGGAGCCCCGGAGAGAGGCAGTCCTGGC AAAGAGCACCCTGAAGAGAGAGTGGTAACAGCGCCCCCCAGTTCCTCACAGTCGGCGGAA GTGCTGGGCGAGCTGGTGCTGGATGGGACCGCACCCTCTGCACATCACGACATCCCAGCC CTGTCACCGCTGCTTCCAGAGGAGGCCCGCCCCAAGCACGCCTTGCCCCCCAAGAAGAAA CTGCCTTCGCTCAAGCAGGTGAACTCTGCCAGGAAGCAGCTGAGGCCCAAGGCCACCTCC GCAGCCACTGTCCAAAGGGCAGGGTCCCAGCCAGCGTCCCAGGGCCTAGATCTCCTCTCC TCCTCCACGGAGAAGCCTGGCCCACCGGGGGACCCGGACCCCATCGTGGCCTCCGAGGAG GCATCAGAAGTGCCCCTTTGGCTGGATCGAAAGGAGAGTGCGGTCCCTACAACACCCGCA CCCCTGCAAATCTCCCCCTTCACTTCGCAGCCCTATGTGGCCCACACACTCCCCCAGAGG CCAGAACCCGGGGAGCCTGGGCCTGACATGGCCCAGGAGGCCCCCCAGGAGGACACCAGC CCCATGGCCCTGATGGACAAAGGTGAGAATGAGCTGACTGGGTCAGCCTCAGAGGAGAGC CAGGAGACCACTACCTCCACCATTATCACCACCACGGTCATCACCACCGAGCAAGCACCA GCTCTCTGCAGTGTGAGCTTCTCCAATCCTGAGGGGTACATTGACTCCAGCGACTACCCA CTGCTGCCCCTCAACAACTTTCTGGAGTGCACATACAACGTGACAGTCTACACTGGCTAT GGGGTGGAGCTCCAGGTGAAGAGTGTGAACCTGTCCGATGGGGAACTGCTCTCCATCCGC GGGGTGGACGGCCCTACCCTGACCGTCCTGGCCAACCAGACACTCCTGGTGGAGGGGCAG GTAATCCGAAGCCCCACCAACACCATCTCCGTCTACTTCCGGACCTTCCAGGACGACGGC CTTGGGACCTTCCAGCTTCACTACCAGGCCTTCATGCTGAGCTGCAACTTTCCCCGCCGG CCTGACTCTGGGGATGTCACGGTGATGGACCTGCACTCAGGTGGGGTGGCCCACTTTCAC TGCCACCTGGGCTATGAGCTCCAGGGCGCTAAGATGCTGACATGCATCAATGCCTCCAAG CCGCACTGGAGCAGCCAGGAGCCCATCTGCTCAGCTCCTTGTGGAGGGGCAGTGCACAAT GCCACCATCGGCCGCGTCCTCTCCCCAAGTTACCCTGAAAACACCAATGGGAGCCAATTC TGCATCTGGACGATTGAAGCTCCAGAGGGCCAGAAGCTGCACCTGCACTTTGAGAGGCTG TTGCTGCATGACAAGGACAGGATGACGGTTCACAGCGGGCAGACCAACAAGTCAGCTCTT CTCTACGACTCCCTTCAAACCGAGAGTGTCCCTTTTGAGGGCCTGCTGAGCGAAGGCAAC ACCATCCGCATCGAGTTCACGTCCGACCAGGCCCGGGCGGCCTCCACCTTCAACATCCGA TTTGAAGCGTTTGAGAAAGGCCACTGCTATGAGCCCTACATCCAGAATGGGAACTTCACT ACATCCGACCCGACCTATAACATTGGGACTATAGTGGAGTTCACCTGCGACCCCGGCCAC TCCCTGGAGCAGGGCCCGGCCATCATCGAATGCATCAATGTGCGGGACCCATACTGGAAT GACACAGAGCCCCTGTGCAGAGCCATGTGTGGTGGGGAGCTCTCTGCTGTGGCTGGGGTG GTATTGTCCCCAAACTGGCCCGAGCCCTACGTGGAAGGTGAAGATTGTATCTGGAAGATC CACGTGGGAGAAGAGAAACGGATCTTCTTAGATATCCAGTTCCTGAATCTGAGCAACAGT GACATCTTGACCATCTACGATGGCGACGAGGTCATGCCCCACATCTTGGGGCAGTACCTT GGGAACAGTGGCCCCCAGAAACTGTACTCCTCCACGCCAGACTTAACCATCCAGTTCCAT TCGGACCCTGCTGGCCTCATCTTTGGAAAGGGCCAGGGATTTATCATGAACTACATAGAG GTATCAAGGAATGACTCCTGCTCGGATTTACCCGAGATCCAGAATGGCTGGAAAACCACT TCTCACACGGAGTTGGTGCGGGGAGCCAGAATCACCTACCAGTGTGACCCCGGCTATGAC ATCGTGGGGAGTGACACCCTCACCTGCCAGTGGGACCTCAGCTGGAGCAGCGACCCCCCA TTTTGTGAGAAAACGGAGGAGTCCCTGGCATGTGACAACCCAGGGCTGCCTGAAAATGGA TACCAAATCCTGTACAAGCGACTCTACCTGCCAGGAGAGTCCCTCACCTTCATGTGCTAC GAAGGCTTTGAGCTCATGGGTGAAGTGACCATCCGCTGCATCCTGGGACAGCCATCCCAC TGGAACGGGCCCCTGCCCGTGTGTAAAGTAGCAGAAGCGGCAGCAGAGACGTCGCTGGAA GGGGGGAACATGGCCCTGGCTATCTTCATCCCGGTCCTCATCATCTCCTTACTGCTGGGA GGAGCCTACATTTACATCACAAGATGTCGCTACTATTCCAACCTCCGCCTGCCTCTGATG TACTCCCACCCCTACAGCCAGATCACCGTGGAAACCGAGTTTGACAACCCCATTTACGAG ACAGGGGAAACCAGAGAGTATGAGGTTTCTATCTACGTAGTTTAAACGAATTCGAGCTCG GTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAA AGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCT TGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTC GCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTAC CTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCAT CCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCC CTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCC TCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATC TGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTT GAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTAT GACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAG GGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGAC GAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGAC GTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTC CTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGG CTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAG CGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCAT CAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAG GATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGC TTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCG TTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTG CTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAG TTCTTCTGAGCGGGACTCTGGGGTTCGCGAAATGACCGACCAAGCGACGCCCAACCGGTA TCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAG AACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCG TTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGG TGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTG CGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGA AGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGC TCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGT AACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACT GGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGG CCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTT ACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGT GGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCT TTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTG GTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGA ACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTG GATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAA ATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTG CTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAAT CCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCG TCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGC GGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATG CCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGA GTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCG TTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGA TTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGC CAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAAC TCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}