Nucleotide Sequence (with vector) for pF1KSDA1014
Download
>pF1KSDA1014 6190 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT
AGAACCATGGGGAAGAAGTCCCGGGCGGTACCCGGCCGTAGGCCCATCCTGCAACTCTCT
CCGCCGGGTCCTCGGGGCAGCACGCCGGGCCGGGACCCGGAGCCGGAACCCGACACTGAG
CCGGACTCAACCGCGGCGGTCCCCAGCCAGCCCGCCCCGTCGGCGGCGACGACCACCGCG
GTGACTGCCGCCGCGGCCTCGGACGACTCGCCTTCAGAAGGCAAGGATGAACAGGAAGCG
GTGCAGGAGGTTCCTAGAGTTGTTCAGAATCCTCCAAAACCAGTCATGACCACTAGACCC
ACAGCTGTTAAAGCAACAGGCGGTCTATGCTTGCTTGGTGCTTATGCTGACAGTGATGAC
GATGACAATGATGTTTCCGAAAAACTAGCACAATCCAAAGAGACAAATGGAAACCAGTCA
ACTGATATTGATAGTACATTGGCCAACTTCCTAGCGGAGATCGATGCCATAACAGCTCCT
CAGCCTGCAGCTCCTGTAGGAGCTTCTGCTCCACCTCCAACTCCACCTCGACCAGAGCCA
AAGGAAGCAGCAACATCTACCCTTTCTTCTTCTACTTCAAATGGAACAGACTCCACCCAA
ACATCTGGTTGGCAATATGATACTCAGTGTTCACTGGCAGGAGTCGGAATTGAGATGGGC
GATTGGCAGGAAGTCTGGGATGAGAACACGGGATGTTATTATTATTGGAATACACAAACA
AATGAAGTGACTTGGGAGTTACCCCAATATCTTGCCACACAGGTACAGGGATTACAGCAT
TACCAGCCCAGTTCTGTGCCAGGTGCTGAAACTAGTTTTGTGGTAAATACAGACATATAT
TCTAAGGAGAAAACGATTTCTGTTTCCAGTAGTAAAAGTGGACCAGTCATAGCCAAGCGA
GAAGTTAAAAAGGAAGTAAATGAAGGAATTCAGGCTCTCTCAAATAGTGAGGAGGAGAAG
AAAGGGGTGGCAGCATCGCTGCTTGCTCCTTTATTGCCTGAGGGAATAAAAGAAGAAGAA
GAGAGATGGAGAAGAAAAGTAATTTGTAAAGAGGAGCCAGTTTCAGAAGTAAAAGAAACA
AGTACAACAGTAGAAGAAGCAACAACAATAGTAAAGCCACAGGAAATTATGTTGGACAAT
ATAGAAGACCCTTCTCAGGAGGATCTTTGCAGTGTTGTCCAATCTGGAGAAAGTGAGGAG
GAAGAGGAACAAGATACCCTTGAACTGGAGCTAGTTTTGGAAAGGAAAAAAGCAGAGTTG
CGAGCCTTGGAGGAAGGAGATGGTAGTGTGTCAGGGTCTAGTCCACGTTCTGATATCAGC
CAGCCAGCATCTCAAGATGGAATGCGTAGGCTTATGTCTAAAAGAGGAAAATGGAAGATG
TTTGTTCGAGCTACCAGTCCAGAATCTACCAGTAGGAGTTCTAGTAAAACTGGACGAGAT
ACTCCAGAAAATGGAGAAACTGCAATTGGTGCTGAAAATTCAGAAAAAATAGATGAGAAT
TCAGATAAAGAGATGGAAGTAGAAGAATCTCCAGAGAAAATAAAAGTACAGACAACACCA
AAAGTAGAAGAAGAACAGGATTTGAAATTTCAGATTGGAGAACTGGCAAATACCCTGACA
AGTAAATTCGAGTTTCTAGGCATTAATAGACAATCCATCTCCAACTTTCATGTGCTGCTC
TTACAGACTGAGACTCGAATTGCAGACTGGCGGGAAGGGGCTCTTAATGGAAACTACCTT
AAACGAAAACTTCAGGATGCAGCAGAACAACTAAAACAGTATGAAATAAACGCCACTCCT
AAAGGCTGGTCCTGCCACTGGGACAGGGATCATAGACGGTATTTCTATGTAAACGAACAG
TCGGGCGAGTCTCAGTGGGAGTTTCCAGATGGTGAAGAGGAAGAAGAAGAAAGCCAAGCA
CAAGAAAATAGAGATGAGACTCTTGCCAAACAGACCTTGAAAGACAAAACTGGCACTGAT
TCAAATTCAACAGAATCCTCTGAAACTTCCACAGGTTCTCTTTGTAAAGAATCCTTTTCT
GGTCAAGTTTCTTCTTCATCACTCATGCCACTTACTCCATTCTGGACCCTCCTTCAGTCA
AATGTTCCTGTGCTTCAACCTCCATTACCCTTGGAAATGCCACCACCCCCACCTCCACCT
CCAGAATCACCTCCACCCCCTCCTCCACCACCTCCTCCTGCGGAAGATGGTGAGATCCAG
GAGGTAGAGATGGAGGATGAGGGAAGTGAGGAGCCCCCTGCCCCAGGAACAGAGGAAGAT
ACCCCTTTGAAACCTTCAGCACAAACCACAGTTGTAACTAGCCAGAGTTCAGTTGATTCC
ACCATCTCTAGTTCTTCTTCCACTAAAGGAATAAAGAGGAAAGCTACAGAAATTAGCACT
GCAGTGGTTCAGAGGTCAGCTACCATTGGCAGTTCTCCAGTTCTCTATAGCCAGTCAGCT
ATAGCTACAGGTCACCAGGCAGCAGGGATTGGAAACCAGGCAACAGGAATTGGACATCAG
ACAATACCAGTTAGCCTTCCAGCAGCAGGAATGGGTCATCAGGCCAGAGGAATGAGCCTG
CAGTCAAATTACCTTGGACTAGCGGCAGCACCTGCAATTATGAGTTATGCAGAATGTTCT
GTCCCAATTGGAGTGACTGCTCCCTCATTGCAGCCAGTTCAGGCCCGAGGTGCTGTGCCT
ACCGCTACCATTATAGAACCACCACCACCACCTCCTCCTCCTCCTCCTCCACCACCACCA
GCTCCCAAAATGCCACCACCTGAAAAGACAAAAAAAGGAAGGAAAGACAAGGCAAAGAAG
AGTAAGACCAAAATGCCATCTTTGGTAAAAAAGTGGCAGAGTATCCAGCGTGAGTTAGAT
GAAGAGGACAATTCTAGTTCCAGTGAAGAGGATCGGGAATCAACTGCACAGAAGCGAATT
GAAGAGTGGAAACAGCAGCAGCTGGTTAGTGGCATGGCAGAGAGAAATGCTAATTTTGAA
GCCCTTCCTGAGGATTGGAGAGCAAGGCTGAAGAGAAGGAAAATGGCTCCAAACACATAC
GTAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCAT
GCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGC
TGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCT
GAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCG
CCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCA
GATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTA
CGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCA
AAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGG
ATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACA
GGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCT
TGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCC
GCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCC
GGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGC
GTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTG
GGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCC
ATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGAC
CACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGAT
CAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTC
AAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCG
AATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTG
GCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGC
GAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATC
GCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGCGAAATGAC
CGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACA
GAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAAC
CGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCAC
AAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCG
TTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATAC
CTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTAT
CTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAG
CCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGAC
TTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGT
GCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGT
ATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGC
AAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGA
AAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAAC
GAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATC
CTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAA
CCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGT
TGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGG
TTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCG
TACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAA
CCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATA
CAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGC
GCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGT
AGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGC
TCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAG
TAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCG
GGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGA
TGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGT
ATCCGCTCAT



 Length: 3051 bp
Length: 3051 bp Restriction map B
Restriction map B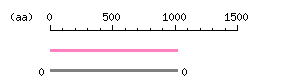

 more Linker info
more Linker info
{kind=link}