


-
SpecieshumanProduct IDFXC00720Cloning SiteSgfI-PmeISymbolKCND2
Alias : KV4.2, RK5Descriptionpotassium channel, voltage gated Shal related subfamily D, member 2 Length: 1890 bp
Length: 1890 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 630 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
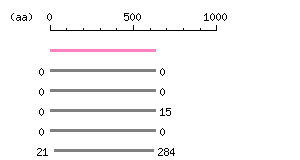
Entry Exp ID% symbol CCDS5776.1 0 100.0 KCND2 CCDS844.1 4.5e-175 76.0 KCND3 CCDS14314.1 8.9e-151 67.3 KCND1 CCDS843.1 1.6e-148 73.8 KCND3 CCDS6209.1 1.1e-46 31.3 KCNB2
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]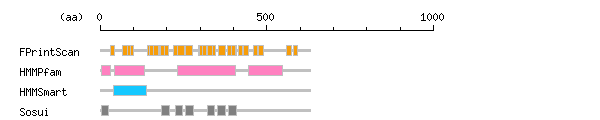 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR004055 30 42 PR01517 Potassium channel IPR003975 68 81 PR01497 Potassium channel IPR003091 82 101 PR00169 Voltage-dependent potassium channel IPR003968 82 92 PR01491 Potassium channel IPR003975 143 159 PR01497 Potassium channel IPR004055 148 164 PR01517 Potassium channel IPR003975 161 175 PR01497 Potassium channel IPR003091 178 206 PR00169 Voltage-dependent potassium channel IPR003975 180 194 PR01497 Potassium channel IPR003975 220 236 PR01497 Potassium channel IPR003091 231 254 PR00169 Voltage-dependent potassium channel IPR003091 257 277 PR00169 Voltage-dependent potassium channel IPR003091 294 320 PR00169 Voltage-dependent potassium channel IPR003968 299 307 PR01491 Potassium channel IPR003975 318 337 PR01497 Potassium channel IPR003091 323 346 PR00169 Voltage-dependent potassium channel IPR003968 323 337 PR01491 Potassium channel IPR003091 354 376 PR00169 Voltage-dependent potassium channel IPR003091 383 409 PR00169 Voltage-dependent potassium channel IPR003968 394 405 PR01491 Potassium channel IPR003975 415 426 PR01497 Potassium channel IPR003975 429 445 PR01497 Potassium channel IPR004055 461 473 PR01517 Potassium channel IPR003975 475 489 PR01497 Potassium channel IPR004055 560 573 PR01517 Potassium channel IPR004055 580 592 PR01517 Potassium channel HMMPfam IPR021645 3 30 PF11601 Shal-type voltage-gated potassium channels IPR003131 43 132 PF02214 Potassium channel IPR005821 231 405 PF00520 Ion transport NULL 445 546 PF11879 NULL HMMSmart IPR000210 41 140 SM00225 BTB/POZ-like
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 4 GVAAWLPFARAAAIGWMPVASG 25 SECONDARY 22 2 185 LVFYYVTGFFIAVSVIANVVETV 207 SECONDARY 23 3 226 AVAFFCLDTACVMIFTVEYLLRL 248 SECONDARY 23 4 257 FVRSVMSIIDVVAILPYYIGLVM 279 PRIMARY 23 5 321 ASELGFLLFSLTMAIIIFATVMF 343 PRIMARY 23 6 353 KFTSIPAAFWYTIVTMTTLGYGD 375 SECONDARY 23 7 386 FGSICSLSGVLVIALPVPVIVSN 408 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_036413 630 605410 100.0 100.0 XP_006710693 636 605411,607346,616399 76.0 100.0 NP_751948 636 605411,607346,616399 76.0 100.0 NP_004970 647 300281 67.3 100.0 XP_011542212 647 300281 67.3 100.0 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KSDA1044 Download>KIAA1044 1890 bp ATGGCGGCGGGGGTGGCAGCGTGGCTGCCTTTTGCAAGGGCAGCGGCTATCGGGTGGATG CCTGTGGCCTCGGGGCCTATGCCGGCTCCCCCGAGGCAGGAGAGGAAAAGGACCCAAGAT GCTCTCATTGTGCTGAATGTGAGTGGCACCCGCTTCCAGACGTGGCAGGACACCCTGGAA CGTTACCCAGACACTCTACTGGGCAGTTCTGAGAGGGACTTTTTCTACCACCCAGAAACT CAGCAGTATTTCTTTGACCGTGACCCAGACATCTTCCGCCACATCCTGAATTTCTACCGC ACTGGGAAGCTCCACTATCCTCGCCACGAGTGCATCTCTGCTTACGATGAAGAACTGGCC TTCTTTGGCCTCATCCCGGAAATCATCGGCGACTGCTGTTATGAGGAGTACAAGGATCGC AGGCGAGAGAACGCCGAGCGCCTGCAGGACGACGCGGATACCGACACCGCTGGGGAGAGC GCCTTGCCCACCATGACTGCAAGGCAGAGGGTCTGGAGGGCCTTCGAGAACCCCCACACC AGCACGATGGCCCTGGTGTTCTACTATGTCACGGGGTTTTTCATTGCCGTCTCTGTCATC GCGAATGTGGTGGAAACAGTGCCGTGCGGATCAAGCCCAGGTCACATTAAAGAACTGCCC TGTGGAGAGCGGTATGCTGTGGCCTTCTTCTGCTTGGACACGGCCTGCGTCATGATCTTC ACAGTTGAGTATTTGCTTCGCCTGGCTGCAGCGCCTAGTCGTTACCGTTTTGTGCGTAGT GTCATGAGTATCATCGACGTGGTGGCCATCCTGCCTTATTACATTGGGCTGGTGATGACA GACAATGAGGACGTCAGCGGAGCCTTTGTCACACTCCGAGTCTTCCGGGTCTTCAGGATC TTTAAGTTTTCCCGCCACTCTCAAGGCCTGCGCATCCTGGGGTACACACTGAAGAGTTGT GCCTCAGAATTGGGCTTCTTGCTTTTCTCGCTCACCATGGCTATCATCATCTTCGCTACA GTTATGTTCTACGCAGAGAAGGGGTCTTCGGCTAGCAAGTTCACCAGCATCCCTGCAGCC TTCTGGTATACCATCGTCACCATGACAACACTAGGGTATGGTGACATGGTGCCAAAAACC ATAGCAGGGAAGATTTTTGGTTCTATCTGTTCGCTGAGTGGGGTCTTGGTCATTGCTCTA CCTGTTCCGGTGATTGTATCCAACTTCAGTCGCATCTACCACCAGAATCAACGAGCAGAC AAACGAAGGGCACAAAAGAAAGCTAGACTGGCCAGGATCCGGGCAGCCAAAAGCGGAAGC GCAAATGCTTACATGCAGAGCAAACGGAATGGTTTACTCAGTAATCAGCTGCAGTCCTCA GAGGATGAGCAGGCTTTTGTTAGCAAATCCGGCTCCAGCTTTGAAACCCAGCACCACCAC CTGCTTCACTGCCTGGAAAAAACCACGAATCACGAGTTTGTGGACGAACAAGTCTTTGAA GAAAGCTGCATGGAAGTTGCAACTGTTAATCGTCCTTCAAGTCACAGTCCTTCACTGTCT TCACAACAAGGAGTCACCAGCACCTGCTGTTCACGACGACACAAAAAAACTTTTCGCATC CCAAATGCCAATGTATCAGGAAGCCATCAAGGTAGTATACAAGAACTCAGCACGATTCAG ATCAGATGTGTGGAGAGAACACCTCTGTCTAACAGCCGATCCAGTTTAAATGCCAAAATG GAAGAGTGTGTTAAACTAAACTGTGAACAACCTTATGTGACTACAGCAATAATAAGCATC CCAACACCTCCAGTAACCACACCAGAAGGAGACGATAGGCCAGAATCCCCTGAGTACTCA GGAGGAAATATTGTCAGAGTTTCTGCTTTG
Cloned ORF protein sequence for pF1KSDA1044 Download>KIAA1044 630 aa MAAGVAAWLPFARAAAIGWMPVASGPMPAPPRQERKRTQDALIVLNVSGTRFQTWQDTLE RYPDTLLGSSERDFFYHPETQQYFFDRDPDIFRHILNFYRTGKLHYPRHECISAYDEELA FFGLIPEIIGDCCYEEYKDRRRENAERLQDDADTDTAGESALPTMTARQRVWRAFENPHT STMALVFYYVTGFFIAVSVIANVVETVPCGSSPGHIKELPCGERYAVAFFCLDTACVMIF TVEYLLRLAAAPSRYRFVRSVMSIIDVVAILPYYIGLVMTDNEDVSGAFVTLRVFRVFRI FKFSRHSQGLRILGYTLKSCASELGFLLFSLTMAIIIFATVMFYAEKGSSASKFTSIPAA FWYTIVTMTTLGYGDMVPKTIAGKIFGSICSLSGVLVIALPVPVIVSNFSRIYHQNQRAD KRRAQKKARLARIRAAKSGSANAYMQSKRNGLLSNQLQSSEDEQAFVSKSGSSFETQHHH LLHCLEKTTNHEFVDEQVFEESCMEVATVNRPSSHSPSLSSQQGVTSTCCSRRHKKTFRI PNANVSGSHQGSIQELSTIQIRCVERTPLSNSRSSLNAKMEECVKLNCEQPYVTTAIISI PTPPVTTPEGDDRPESPEYSGGNIVRVSAL
Nucleotide Sequence (with vector) for pF1KSDA1044 Download>pF1KSDA1044 5027 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT AGAACCATGGCGGCGGGGGTGGCAGCGTGGCTGCCTTTTGCAAGGGCAGCGGCTATCGGG TGGATGCCTGTGGCCTCGGGGCCTATGCCGGCTCCCCCGAGGCAGGAGAGGAAAAGGACC CAAGATGCTCTCATTGTGCTGAATGTGAGTGGCACCCGCTTCCAGACGTGGCAGGACACC CTGGAACGTTACCCAGACACTCTACTGGGCAGTTCTGAGAGGGACTTTTTCTACCACCCA GAAACTCAGCAGTATTTCTTTGACCGTGACCCAGACATCTTCCGCCACATCCTGAATTTC TACCGCACTGGGAAGCTCCACTATCCTCGCCACGAGTGCATCTCTGCTTACGATGAAGAA CTGGCCTTCTTTGGCCTCATCCCGGAAATCATCGGCGACTGCTGTTATGAGGAGTACAAG GATCGCAGGCGAGAGAACGCCGAGCGCCTGCAGGACGACGCGGATACCGACACCGCTGGG GAGAGCGCCTTGCCCACCATGACTGCAAGGCAGAGGGTCTGGAGGGCCTTCGAGAACCCC CACACCAGCACGATGGCCCTGGTGTTCTACTATGTCACGGGGTTTTTCATTGCCGTCTCT GTCATCGCGAATGTGGTGGAAACAGTGCCGTGCGGATCAAGCCCAGGTCACATTAAAGAA CTGCCCTGTGGAGAGCGGTATGCTGTGGCCTTCTTCTGCTTGGACACGGCCTGCGTCATG ATCTTCACAGTTGAGTATTTGCTTCGCCTGGCTGCAGCGCCTAGTCGTTACCGTTTTGTG CGTAGTGTCATGAGTATCATCGACGTGGTGGCCATCCTGCCTTATTACATTGGGCTGGTG ATGACAGACAATGAGGACGTCAGCGGAGCCTTTGTCACACTCCGAGTCTTCCGGGTCTTC AGGATCTTTAAGTTTTCCCGCCACTCTCAAGGCCTGCGCATCCTGGGGTACACACTGAAG AGTTGTGCCTCAGAATTGGGCTTCTTGCTTTTCTCGCTCACCATGGCTATCATCATCTTC GCTACAGTTATGTTCTACGCAGAGAAGGGGTCTTCGGCTAGCAAGTTCACCAGCATCCCT GCAGCCTTCTGGTATACCATCGTCACCATGACAACACTAGGGTATGGTGACATGGTGCCA AAAACCATAGCAGGGAAGATTTTTGGTTCTATCTGTTCGCTGAGTGGGGTCTTGGTCATT GCTCTACCTGTTCCGGTGATTGTATCCAACTTCAGTCGCATCTACCACCAGAATCAACGA GCAGACAAACGAAGGGCACAAAAGAAAGCTAGACTGGCCAGGATCCGGGCAGCCAAAAGC GGAAGCGCAAATGCTTACATGCAGAGCAAACGGAATGGTTTACTCAGTAATCAGCTGCAG TCCTCAGAGGATGAGCAGGCTTTTGTTAGCAAATCCGGCTCCAGCTTTGAAACCCAGCAC CACCACCTGCTTCACTGCCTGGAAAAAACCACGAATCACGAGTTTGTGGACGAACAAGTC TTTGAAGAAAGCTGCATGGAAGTTGCAACTGTTAATCGTCCTTCAAGTCACAGTCCTTCA CTGTCTTCACAACAAGGAGTCACCAGCACCTGCTGTTCACGACGACACAAAAAAACTTTT CGCATCCCAAATGCCAATGTATCAGGAAGCCATCAAGGTAGTATACAAGAACTCAGCACG ATTCAGATCAGATGTGTGGAGAGAACACCTCTGTCTAACAGCCGATCCAGTTTAAATGCC AAAATGGAAGAGTGTGTTAAACTAAACTGTGAACAACCTTATGTGACTACAGCAATAATA AGCATCCCAACACCTCCAGTAACCACACCAGAAGGAGACGATAGGCCAGAATCCCCTGAG TACTCAGGAGGAAATATTGTCAGAGTTTCTGCTTTGTACGTAGTTTAAACGAATTCGAGC TCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAA CAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACC CCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGG TTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGC TACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATT CATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCA GCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCG CCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGG ATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATG CTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGC TATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCG CAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAG GACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTC GACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGAT CTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGG CGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATC GAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAG CATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGT GAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGC CGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATA GCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTC GTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGAC GAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGT ATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAA GAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGC GTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAG GTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGT GCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGG AAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCG CTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGG TAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCAC TGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTG GCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGT TACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGG TGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCC TTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTT GGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGG AACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGT GGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAA AATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCT GCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAA TCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGC GTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAG CGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCAT GCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAG AGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTC GTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGG ATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTG CCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAA CTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}