Nucleotide Sequence (with vector) for pF1KSDA1052
Download
>pF1KSDA1052 7504 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT
AGAACCATGGCTGGACGACCCCTCCGCATAGGAGATCAGCTGGTTCTGGAAGAAGATTAT
GATGAGACCTACATTCCTAGTGAGCAAGAAATTCTTGAATTTGCCCGGGAGATTGGTATT
GATCCCATCAAGGAACCAGAACTGATGTGGCTGGCGCGAGAGGGCATCGTGGCCCCACTG
CCTGGAGAGTGGAAACCATGCCAGGACATCACAGGTGACATTTACTATTTCAACTTCGCC
AACGGGCAGTCTATGTGGGACCATCCATGTGACGAACACTATCGGAGCTTGGTGATCCAA
GAGCGGGCAAAGCTGTCAACTTCTGGGGCCATTAAGAAGAAGAAAAAAAAAAAGGAAAAG
AAAGACAAGAAGGACAGAGACCCCCCCAAAAGTTCGCTGGCCTTGGGTTCCTCATTAGCC
CCAGTTCATGTTCCTCTTGGGGGCCTGGCTCCTTTACGAGGTCTTGTGGATACCCCACCC
TCTGCTCTTCGTGGATCTCAAAGCGTGAGCCTGGGGAGCTCAGTGGAGTCTGGACGTCAG
CTTGGAGAACTCATGCTGCCTTCACAGGGTCTCAAGACCTCTGCTTATACAAAGGGTCTC
TTGGGCTCCATATATGAGGACAAGACTGCTCTCAGCCTCTTGGGTTTAGGAGAAGAAACC
AATGAGGAGGATGAGGAGGAAAGTGACAACCAGAGTGTCCACAGCTCAAGTGAGCCTCTT
AGGAACCTACACCTGGACATTGGGGCACTGGGGGGTGACTTTGAGTATGAGGAGTCTCTG
AGAACAAGCCAGCCAGAGGAGAAGAAGGATGTTTCTCTGGATTCAGATGCTGCCGGTCCC
CCTACTCCCTGCAAGCCCTCCAGCCCAGGTGCAGACAGCAGTCTGAGCAGTGCTGTTGGC
AAAGGGCGACAGGGAAGTGGAGCAAGACCTGGTCTTCCAGAAAAAGAGGAAAATGAGAAG
AGTGAACCTAAGATTTGCAGGAATCTGGTGACCCCCAAGGCAGACCCTACAGGCAGTGAG
CCTGCCAAAGCCTCTGAAAAGGAAGCACCAGAGGACACAGTAGATGCAGGAGAGGAGGGT
TCCAGGAGGGAAGAGGCAGCCAAGGAGCCAAAGAAGAAGGCTTCTGCTCTGGAAGAGGGC
AGTTCAGACGCCAGCCAAGAACTGGAAATTAGTGAACACATGAAGGAACCACAGCTCTCA
GACTCCATAGCTTCTGACCCCAAGTCCTTCCATGGCCTGGACTTCGGTTTTCGCAGCCGG
ATCTCGGAGCACCTGCTGGATGTTGATGTGCTTTCCCCAGTCCTGGGTGGAGCTTGTCGG
CAGGCCCAGCAACCACTGGGAATAGAAGACAAGGATGACAGCCAGTCCAGCCAAGATGAG
CTGCAGAGCAAGCAGTCCAAAGGCCTGGAGGAGAGGTACCATAGGTTATCTCCTCCACTT
CCACACGAGGAGCGGGCCCAGAGTCCCCCTCGCAGCCTGGCCACTGAAGAAGAGCCCCCC
CAGGGCCCCGAGGGGCAGCCCGAGTGGAAGGAGGCAGAGGAGCTTGGGGAGGACTCTGCA
GCCAGCCTCAGCCTGCAGCTGTCCCTCCAGAGGGAGCAGGCCCCAAGCCCACCTGCTGCC
TGTGAGAAGGGCAAGGAGCAGCATTCCCAGGCCGAGGAGCTGGGCCCTGGGCAGGAAGAG
GCAGAGGATCCTGAGGAGAAGGTGGCGGTCAGCCCCACCCCGCCAGTCTCTCCAGAGGTG
CGATCCACAGAGCCTGTGGCTCCCCCAGAGCAGCTCTCAGAGGCTGCACTAAAGGCCATG
GAAGAGGCAGTGGCCCAAGTACTCGAGCAAGACCAGAGGCACCTGCTGGAATCCAAGCAA
GAGAAGATGCAGCAACTGCGGGAGAAGCTGTGCCAAGAGGAGGAAGAGGAGATCCTCCGG
CTTCACCAGCAGAAAGAGCAATCTCTCAGTTCCTTGAGGGAGCGGCTGCAGAAAGCCATT
GAGGAGGAGGAGGCCCGGATGAGAGAGGAGGAAAGCCAGAGGCTATCCTGGCTCCGAGCT
CAGGTCCAGTCCAGCACACAAGCAGATGAGGACCAAATCAGGGCTGAGCAAGAGGCTTCC
CTGCAGAAACTGAGAGAAGAGTTGGAGTCTCAACAGAAGGCTGAGAGGGCCAGCTTGGAA
CAGAAAAATAGGCAAATGCTGGAGCAGCTCAAGGAAGAGATAGAGGCTTCGGAGAAGAGC
GAGCAGGCTGCCCTGAATGCTGCAAAGGAGAAGGCTCTGCAGCAGCTGAGGGAGCAGCTG
GAAGGGGAGAGGAAAGAAGCTGTGGCAACGCTGGAGAAGGAGCACAGTGCTGAGCTGGAG
CGGCTCTGCTCCTCATTGGAGGCCAAGCACCGGGAGGTGGTCTCCAGCCTCCAGAAGAAG
ATACAGGAAGCTCAACAGAAAGAGGAGGCCCAGCTGCAGAAGTGCCTTGGGCAAGTGGAG
CACAGAGTTCACCAGAAGTCTTATCACGTGGCTGGGTATGAGCACGAGCTCAGCAGTCTC
CTGCGAGAGAAGCGCCAGGAAGTGGAAGGGGAGCATGAGAGGAGGTTGGACAAGATGAAG
GAGGAGCACCAGCAAGTGATGGCTAAGGCCAGAGAGCAGTATGAAGCTGAGGAGAGGAAG
CAGCGGGCTGAGCTTCTGGGGCACCTGACCGGAGAGCTGGAGCGCCTGCAGAGGGCCCAT
GAACGAGAACTGGAGACTGTGAGGCAGGAGCAACACAAGCGTCTTGAGGACTTGCGGCGC
CGGCACAGGGAGCAGGAAAGGAAGCTCCAGGATTTAGAGTTGGACCTTGAAACCAGAGCT
AAAGATGTCAAGGCCAGATTGGCTCTGCTGGAGGTCCAGGAGGAGACCGCCCGGAGGGAG
AAGCAGCAGCTGCTTGATGTGCAGAGGCAGGTTGCTCTGAAGAGTGAGGAAGCCACAGCC
ACCCATCAGCAGCTGGAGGAGGCACAGAAGGAGCACACCCACCTGTTGCAGTCAAACCAG
CAGCTCCGAGAAATTCTTGATGAGCTGCAGGCCCGCAAGCTGAAGCTGGAGTCCCAAGTG
GATCTGCTGCAGGCTCAGAGCCAGCAACTGCAGAAACACTTCAGCAGCCTGGAGGCTGAA
GCTCAAAAGAAGCAGCACCTGTTGAGAGAAGTGACAGTTGAGGAAAATAATGCTTCCCCA
CATTTTGAGCCAGATCTCCATATTGAGGACCTGAGGAAATCCCTTGGAACAAACCAGACC
AAAGAGGTGTCTTCTTCTCTCTCCCAGAGCAAGGAGGACTTATACTTGGACAGCCTGTCC
TCCCACAATGTCTGGCACCTCCTCTCTGCTGAGGGGGTAGCCCTCCGTAGTGCCAAGGAG
TTCCTTGTGCAGCAGACACGCTCCATGCGGAGGCGGCAGACAGCTCTGAAAGCTGCCCAG
CAGCATTGGCGCCATGAGCTGGCCAGTGCGCAGGAGGTGGCCAAAGACCCACCAGGCATC
AAGGCCCTGGAAGATATGCGCAAGAACCTGGAGAAGGAGACCAGGCACCTGGATGAGATG
AAGTCGGCCATGCGGAAAGGCCACAACCTGCTGAAGAAGAAAGAGGAGAAGCTGAATCAG
TTGGAGTCCTCTCTTTGGGAAGAGGCCTCAGATGAGGGCACTCTGGGAGGATCCCCCACC
AAGAAGGCAGTAACCTTCGACCTCAGTGACATGGACAGCCTGAGCAGTGAAAGTTCTGAA
TCTTTTTCCCCGCCTCACCTCGACTCAACCCCGAGTCTCACCTCCCGCAAGATCCACGGG
CTTAGCCACTCCCTCCGGCAGATCAGCAGCCAGCTGAGCAGTGTCCTCAGCATCCTGGAC
AGCCTCAACCCTCAGTCGCCGCCGCCGCTCCTCGCCTCCATGCCAGCCCAGCTCCCTCCC
CGGGACCCTAAGAGCACCCCCACCCCCACCTACTATGGCTCCCTGGCCAGGTTCTCAGCC
TTATCATCTGCTACACCCACGTCCACCCAATGGGCCTGGGATTCAGGGCAGGGGCCCAGG
CTCCCCTCCTCTGTGGCTCAAACGGTGGACGACTTCCTGTTGGAGAAGTGGCGCAAGTAT
TTTCCATCTGGCATCCCGCTGCTCAGCAACAGCCCCACCCCGCTGGAGAGCAGGCTGGGT
TACATGTCTGCCAGTGAGCAGCTCCGGCTCCTACAGCACTCCCATTCGCAAGTCCCTGAG
GCGGGCAGCACCACCTTTCAGGGCATAATTGAGGCCAACCGGAGGTGGCTGGAACGTGTC
AAGAATGACCCCAGGTTACCTCTCTTCTCTTCAACACCCAAGCCAAAAGCTACTTTGAGC
CTCCTGCAGCTGGGCCTTGATGAGCACAACAGAGTGAAGGTGTATCGCTTCTACGTAGTT
TAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGC
TGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCA
ATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGG
AGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGT
AAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGC
CCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTT
CCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAA
TTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCT
TTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGA
CGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTG
GAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTG
TTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCC
CTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCT
TGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAA
GTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATG
GCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAA
GCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGAT
GATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCG
CGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATC
ATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGAC
CGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGG
GCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTC
TATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGCGAAATGACCGACCA
AGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCA
GGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAA
AAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAAT
CGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCC
CCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCC
GCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGT
TCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGAC
CGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCG
CCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACA
GAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGC
GCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAA
ACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAA
GGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAAC
TCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTA
TAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGA
AAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATA
GGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTT
GCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAAT
TAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAG
TACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATT
AAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTG
GTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTG
GGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTC
GAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGAC
AAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGG
ACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCT
TTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGC
TCAT



 Length: 4365 bp
Length: 4365 bp Restriction map B
Restriction map B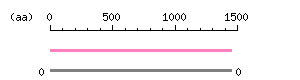

 more Linker info
more Linker info
{kind=link}