Nucleotide Sequence (with vector) for pF1KSDA1754
Download
>pF1KSDA1754 4778 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT
AGAACCATGGCCATGGGGCTCTTCCGCGTGTGTCTGGTGGTGGTGACGGCCATCATCAAC
CACCCGCTGCTGTTCCCGCGGGAGAACGCCACAGTCCCCGAGAACGAGGAGGAGATCATC
CGCAAGATGCAGGCGCACCAGGAGAAGCTGCAGCTGGAGCAGTTGCGCCTGGAGGAGGAG
GTGGCTCGGCTGGCGGCCGAAAAGGAGGCACTGGAGCAGGTGGCGGAGGAGGGCAGGCAG
CAGAACGAGACACGCGTGGCCTGGGACCTCTGGAGCACCCTCTGCATGATCCTCTTCCTG
ATGATCGAGGTGTGGCGGCAGGACCACCAGGAGGGGCCCTCACCTGAGTGCCTGGGCGGT
GAGGAGGATGAGCTGCCTGGGCTGGGGGGCGCCCCCTTGCAGGGCCTCACCCTGCCCAAC
AAGGCCACGCTTGGCCACTTTTATGAGCGCTGCATCCGGGGGGCCACGGCCGATGCAGCC
CGTACCCGGGAGTTCCTGGAAGGCTTCGTGGATGACTTGCTGGAAGCCCTGAGGAGCCTC
TGCAACCGGGACACCGACATGGAGGTGGAGGACTTCATTGGCGTGGACAGCATGTACGAG
AACTGGCAGGTGGACAGGCCACTGCTGTGCCACCTTTTCGTGCCCTTCACACCCCCCGAG
CCCTACCGCTTCCACCCAGAGCTCTGGTGCTCCGGCCGCTCAGTGCCCCTGGATCGCCAG
GGCTACGGCCAGATCAAGGTGGTCCGCGCCGATGGGGACACATTGAGCTGCATCTGCGGC
AAGACCAAGCTCGGGGAAGACATGCTGTGTCTCCTGCACGGCAGGAACAGCATGGCGCCT
CCCTGCGGCGACATGGAGAACCTGCTGTGTGCCACAGATTCCCTGTACCTGGACACGATG
CAGGTCATGAAGTGGTTCCAGACGGCCCTCACCAGAGCCTGGAAGGGCATCGCCCACAAG
TACGAGTTCGACCTGGCCTTTGGCCAGCTGGACAGCCCGGGGTCCCTGAAGATCAAGTTC
CGTTCAGGGAAGTTCATGCCCTTCAACCTGATTCCTGTGATCCAGTGTGATGACTCGGAC
CTGTACTTTGTCTCCCACCTTCCCAGGGAGCCCTCTGAGGGCACCCCAGCCTCCAGCACA
GACTGGCTCCTGTCCTTTGCTGTCTATGAGCGACACTTCCTCAGGACGACACTAAAGGCA
CTGCCCGAGGGCGCCTGCCACCTCAGCTGCCTGCAGATAGCATCCTTCCTGCTCTCCAAG
CAGAGCCGCCTGACCGGTCCCAGCGGGCTCAGCAGCTACCACCTGAAGACGGCCCTACTG
CACCTCCTACTCCTCCGGCAGGCCGCCGACTGGAAGGCGGGGCAGCTGGACGCTCGTCTG
CACGAGTTGCTGTGCTTCCTGGAGAAGAGCTTGCTCCAGAAGAAGCTCCACCACTTCTTC
ATCGGCAACCGCAAGGTGCCTGAGGCCATGGGACTCCCTGAGGCCGTGCTCAGGGCCGAG
CCCCTCAACCTCTTCCGGCCCTTCGTCCTGCAGCGAAGCCTTTACCGTAAGACACTGGAC
TCCTTCTATGAGATGCTCAAGAATGCCCCAGCGCTCATTAGCGAGTATTCCCTACATGTC
CCCTCAGACCAGCCTACCCCAAAAAGCTACGTAGTTTAAACGAATTCGAGCTCGGTACCC
GGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCG
AAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGC
CTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGC
TGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTT
TCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGG
TCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCG
CCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGT
AAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGG
CGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAA
GATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGG
GCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGC
CCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCA
GCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTC
ACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCA
TCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCAT
ACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCA
CGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGG
CTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTC
GTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCT
GGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCT
ACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTAC
GGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTC
TGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGCTCA
CTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTG
AGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCA
TAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAA
CCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCC
TGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGC
GCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCT
GGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCG
TCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAG
GATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTA
CGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGG
AAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTT
TGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTT
TTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAG
ATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCACGC
TGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGT
GGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCA
GGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTG
ATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTAC
TGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGT
AGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGAT
AAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTC
AGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAA
CTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCT
GTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACG
TTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATC
AAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGT
TTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 1641 bp
Length: 1641 bp Restriction map B
Restriction map B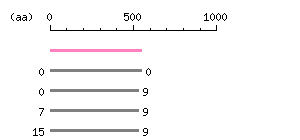
 more Linker info
more Linker info
{kind=link}